资源
- ComfyUI 2026年入门教程分享 - 资源荟萃 - LINUX DO
- ComfyUI Course - Learn ComfyUI From Scratch | Full 5 Hour Course (Ep01) - YouTube
- Comfy — Professional Control of Visual AI
- Pixaroma - Designing at the Speed of Innovation
- HF-Mirror
正文
第 3 章 – 安装 ComfyUI(便携版)
视频中推荐从
- Comfy-Org/ComfyUI: The most powerful and modular diffusion model GUI, api and backend with a graph/nodes interface. 或
- Tavris1/ComfyUI-Easy-Install: Portable ComfyUI installer for Windows, macOS and Linux with EZi Desktop app 🔹 Nvidia GPU support 🔹 Pixaroma Community Edition 直接从
README.md处下载ComfyUI-Easy-Install.zip,解压后运行ComfyUI-Easy-Install.bat。
下载安装。而我选择从官网下载 ComfyUI Desktop:Download Comfy Desktop — Run AI on Your Hardware,启动后,可在 Desktop 中使用,也可 http://127.0.0.1:8188/。
第 4 章 – 首次启动与界面概览
打开 ComfyUI,得到这样的界面。
第 5 章 – 运行现成的工作流
ComfyUI 中的 workflow、settings 等数据都是用 json 形式存储的。
从 Pixaroma Workflows - Free ComfyUI Workflows 里下载 EP01 Workflows.zip。
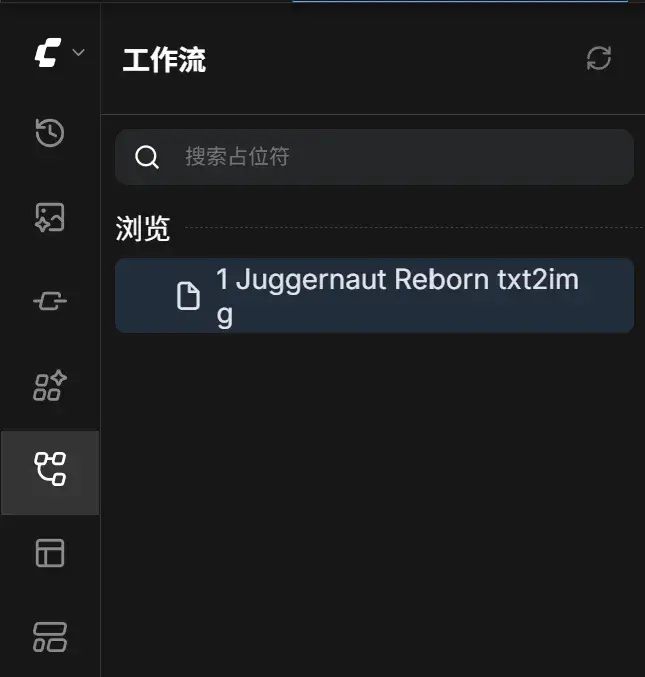
让 ComyUI 打开 0 Help and Resources.json:
打开 1 Juggernaut Reborn txt2img.json,提示找不到 Checkpoint,看简介下载对应的模型 juggernaut_reborn.safetensors(2 GB 左右)。
提示
Checkpoint 加载器(简易)
加载扩散模型检查点文件,并将其分解为三个核心组件:用于去噪潜空间的主模型、CLIP 文本编码器以及 VAE 图像编码器/解码器。此节点会自动检测 Comfy-Desktop/ComfyUI-Installs/ComfyUI/models/checkpoints 文件夹以及 extra_model_paths.yaml 文件中配置的所有其他路径中的模型文件。
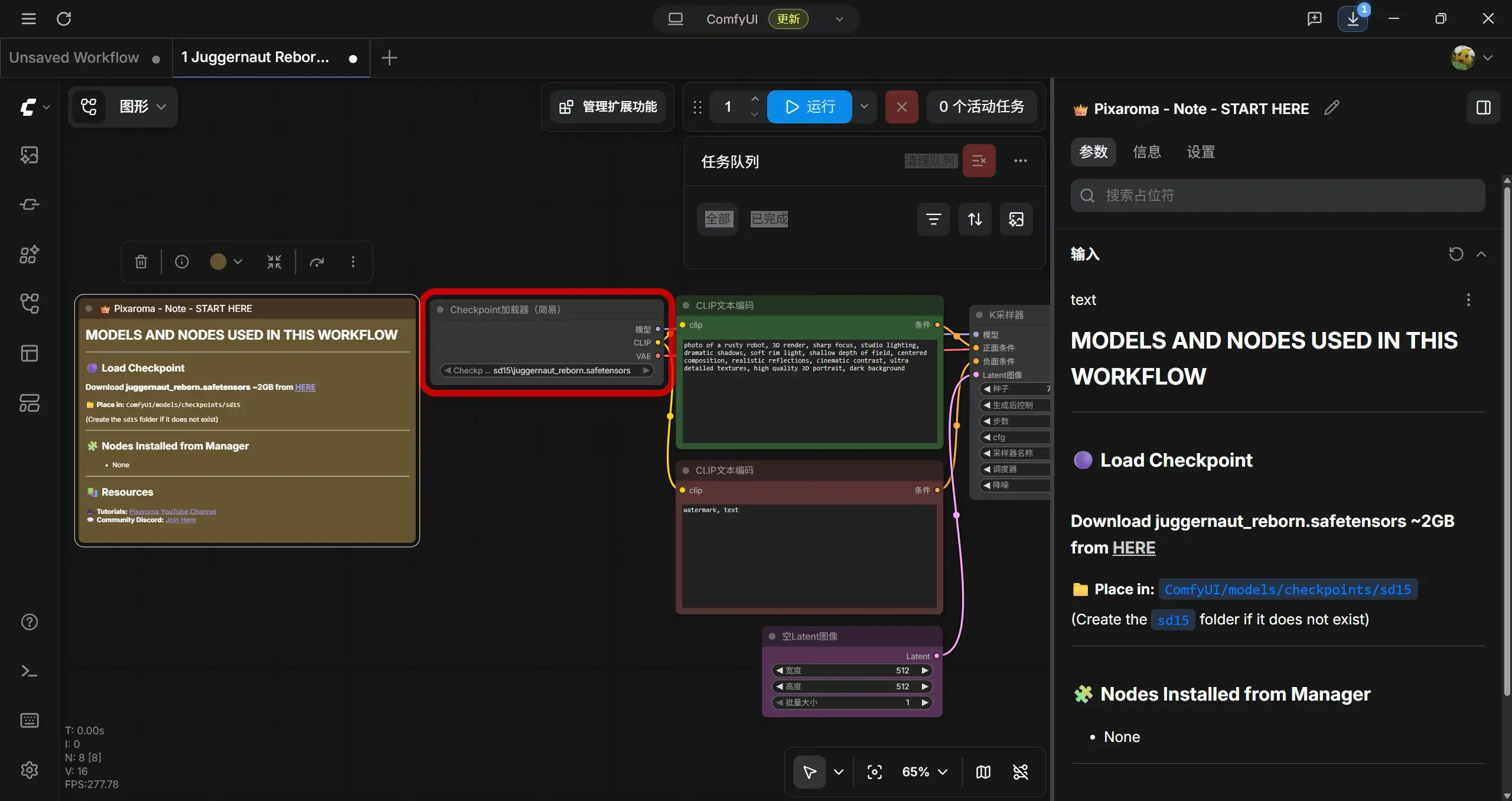
将模型放置在 Comfy-Desktop/ComfyUI-Installs/ComfyUI/models/checkpoints/sd15 下:

按下 R 刷新,然后开跑,即可得到输出结果:
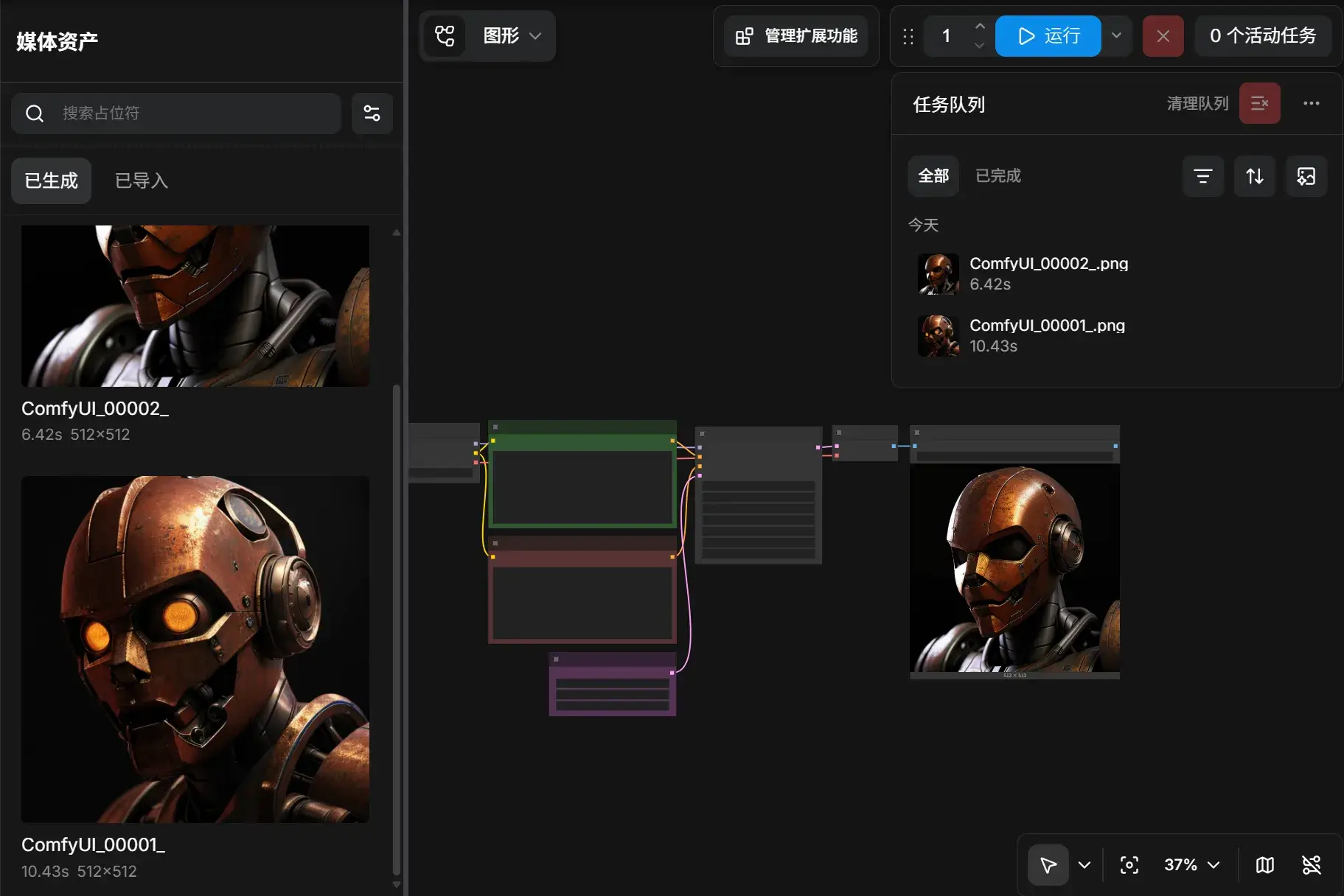
图片被默认地保存到了 Comfy-Desktop/ComfyUI-Shared/output/ComfyUI_XXXXX_.png.。
第 6 章 – 理解节点与工作流原理
有多种方法可以在 ComfyUI 中添加节点,双击空白处/右键添加节点/左侧节点库。
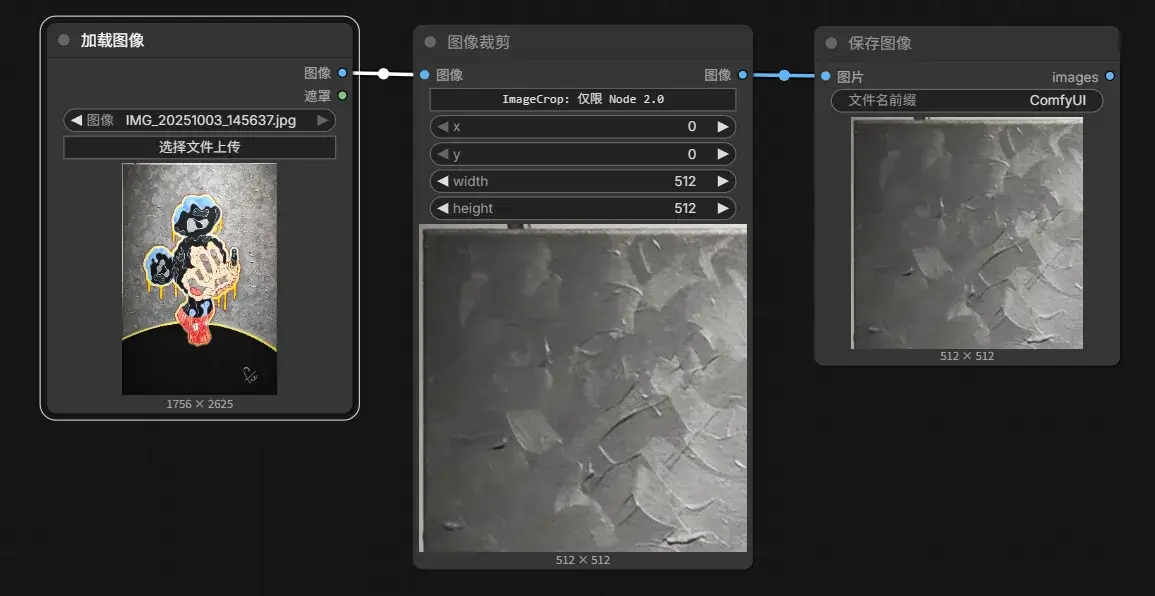
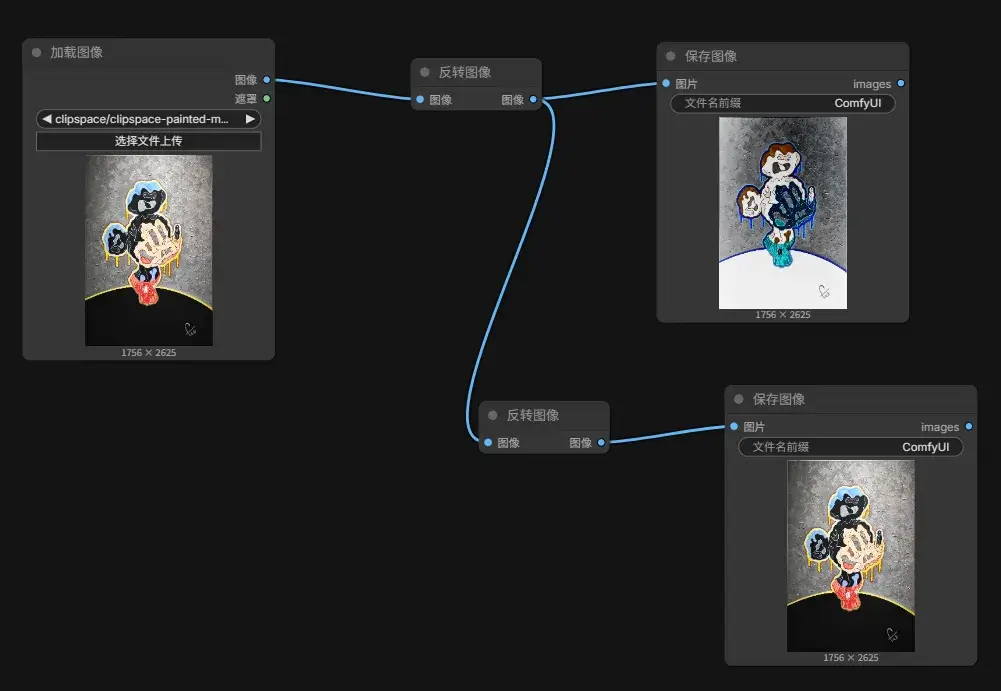
Graph 的工作流程对我来说已经比较熟悉。创建 Load Image、Image Crop 和 Save Image 节点并用线连接,上传图片,然后开跑:
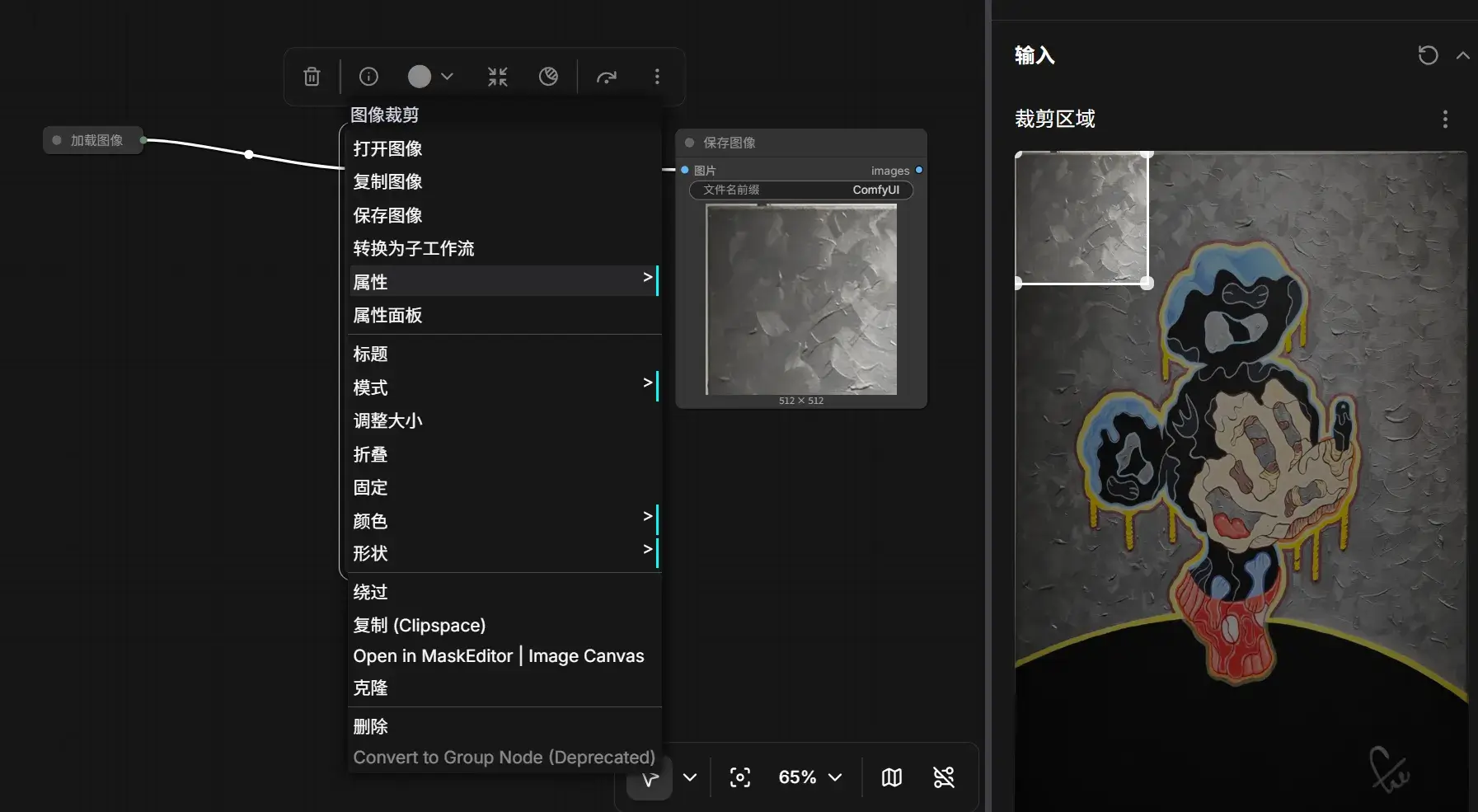
可以调整节点的具体属性(折叠/更改标题/修改具体参数等):
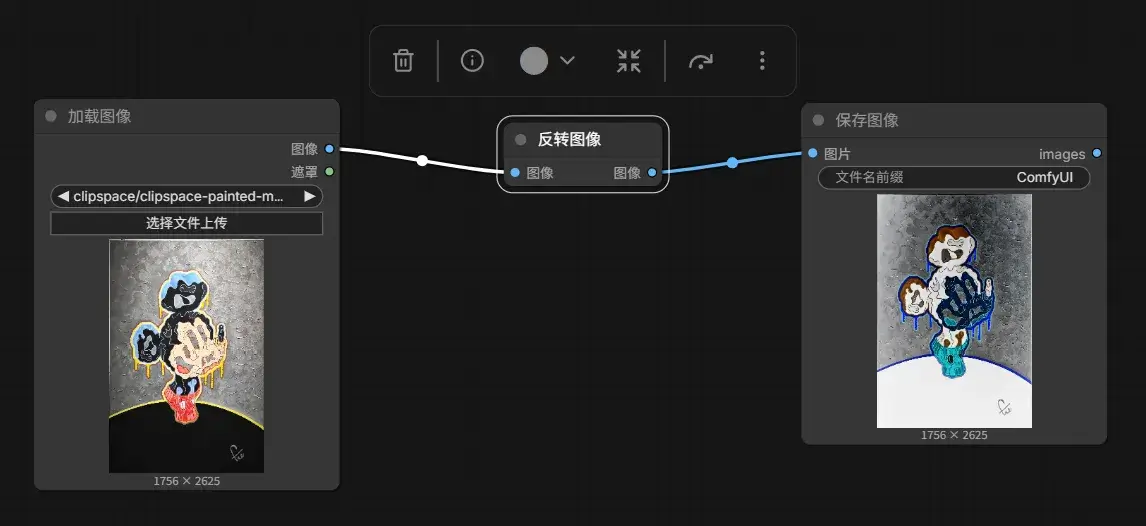
再试一试 Invert Image 节点:
可以有多个 Save Image 节点:
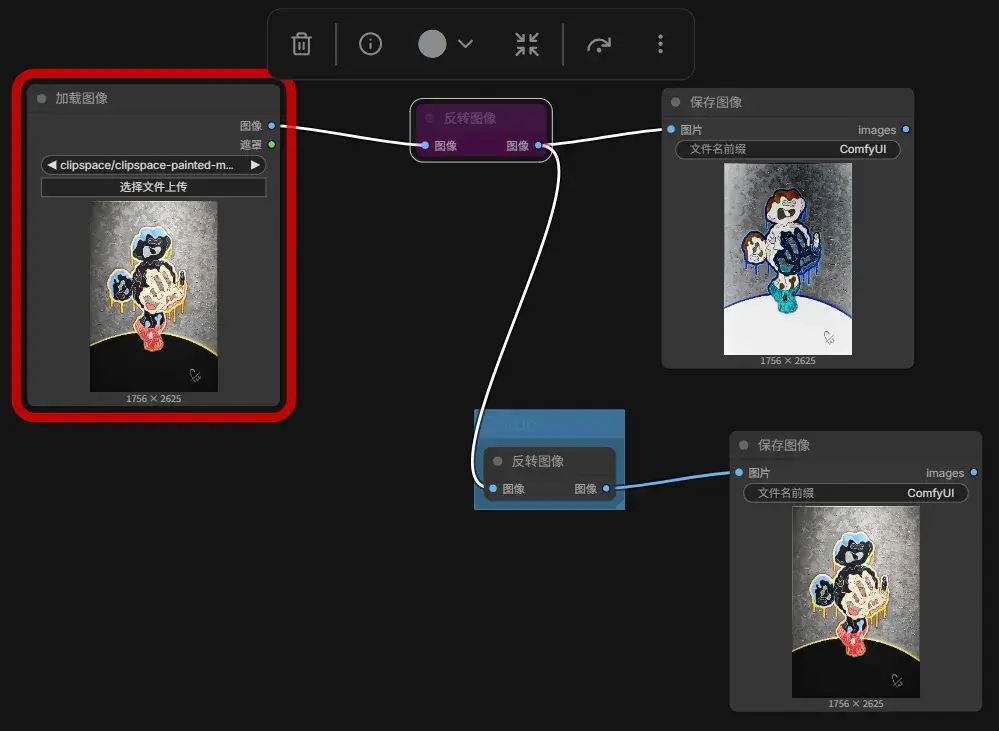
一些与其他软件差不多的快捷键:Ctrl + B 绕过节点,Ctrl + G 成组。
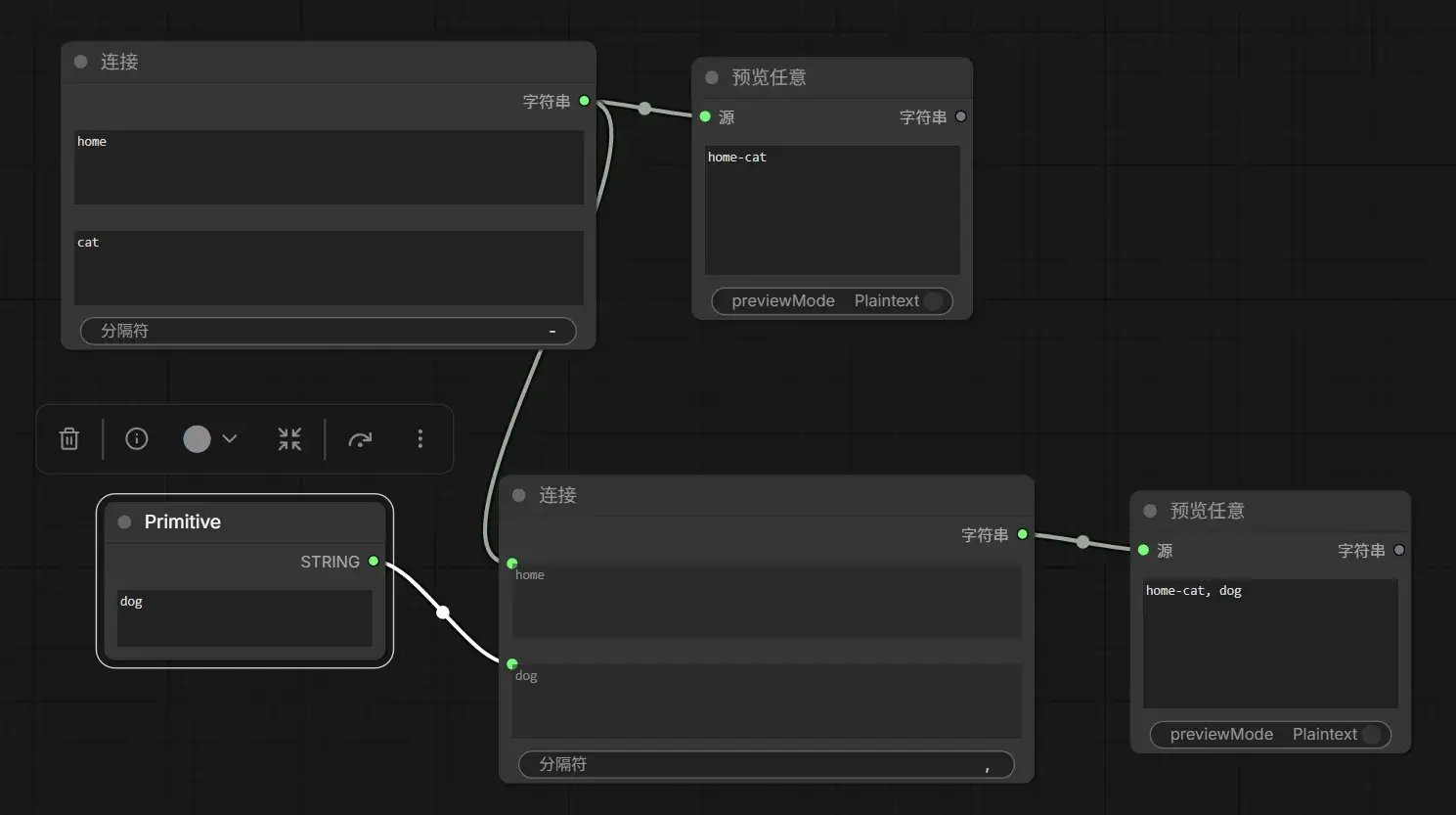
除了操作图像,还可以操作数字,字符串等:
剩下自己慢慢玩吧……
第 7 章 – 从零开始构建工作流
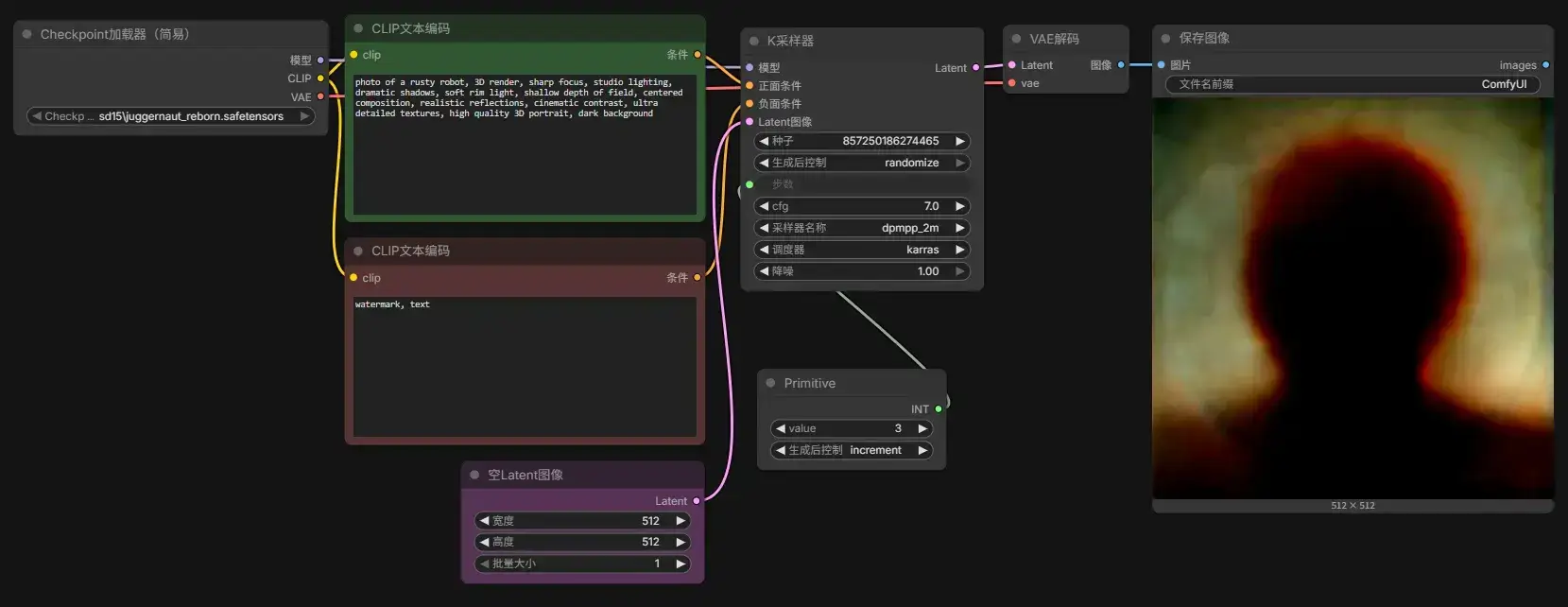
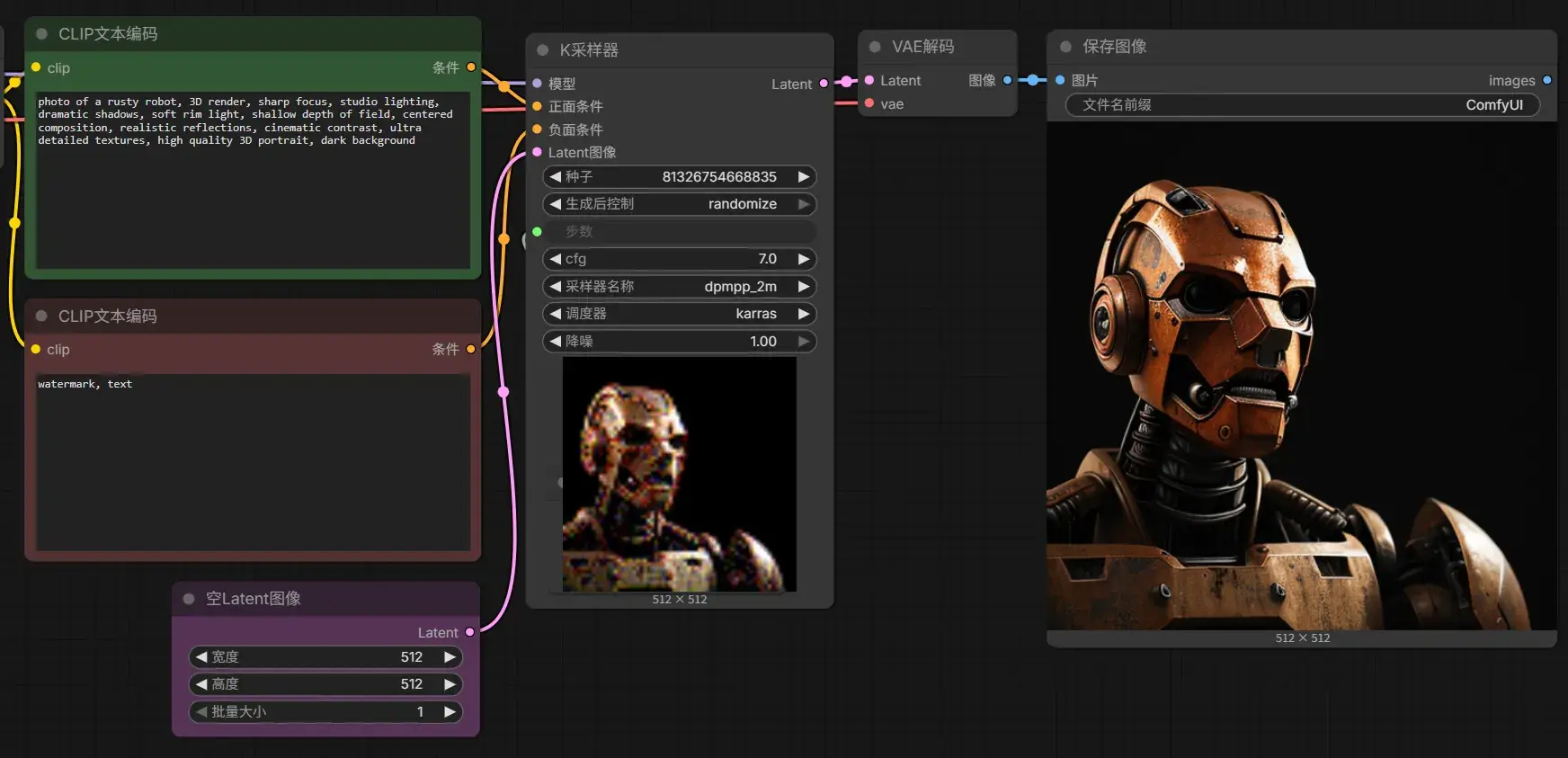
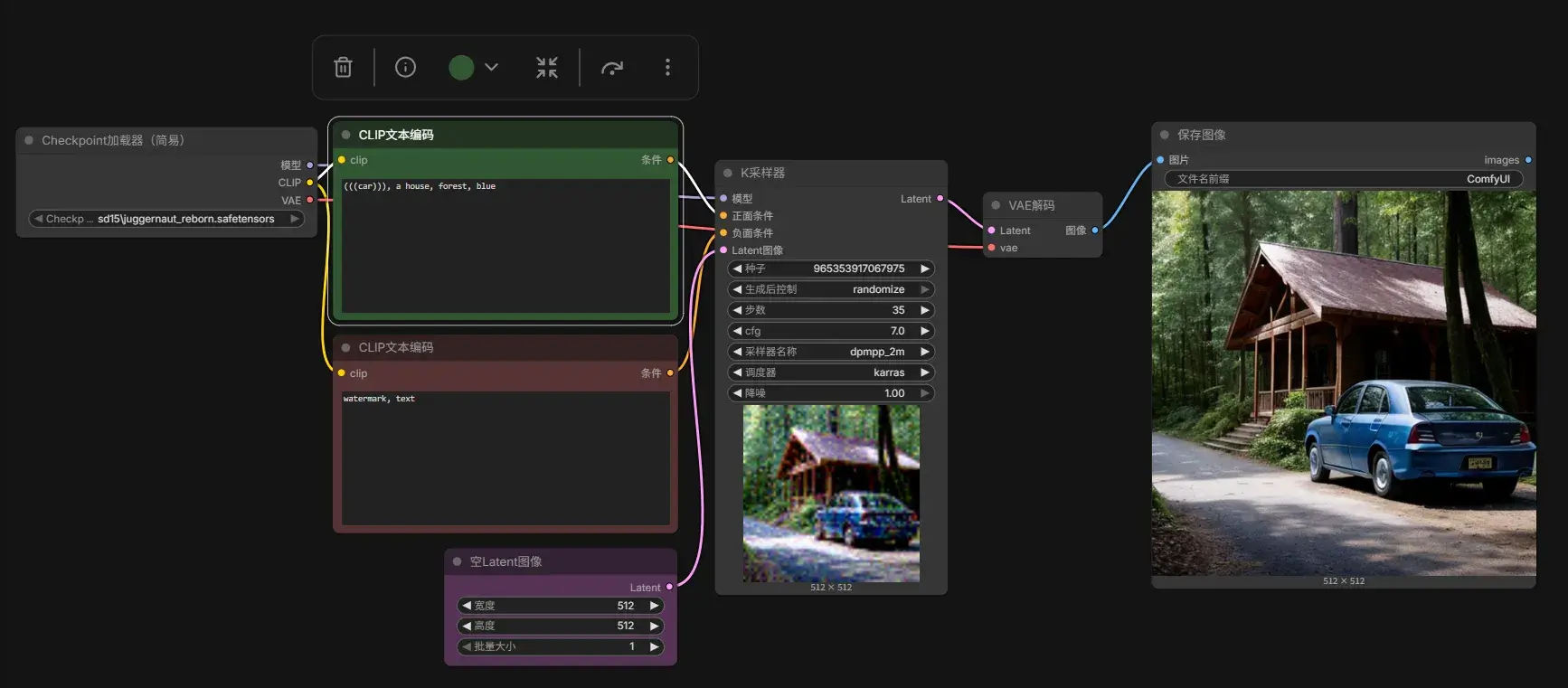
本章讲述了 1 Juggernaut Reborn txt2img.json 工作流中各个节点的作用,其实把这个 json 扔给 LLM 就行:
| 节点 ID | 节点名称 | 作用 | 输入 | 输出 | 本工作流中的配置 |
|---|---|---|---|---|---|
| 1 | CheckpointLoaderSimple | 加载 Stable Diffusion 模型(Checkpoint),同时输出模型、CLIP、VAE 三部分 | 无 | MODEL、CLIP、VAE | 加载 juggernaut_reborn.safetensors |
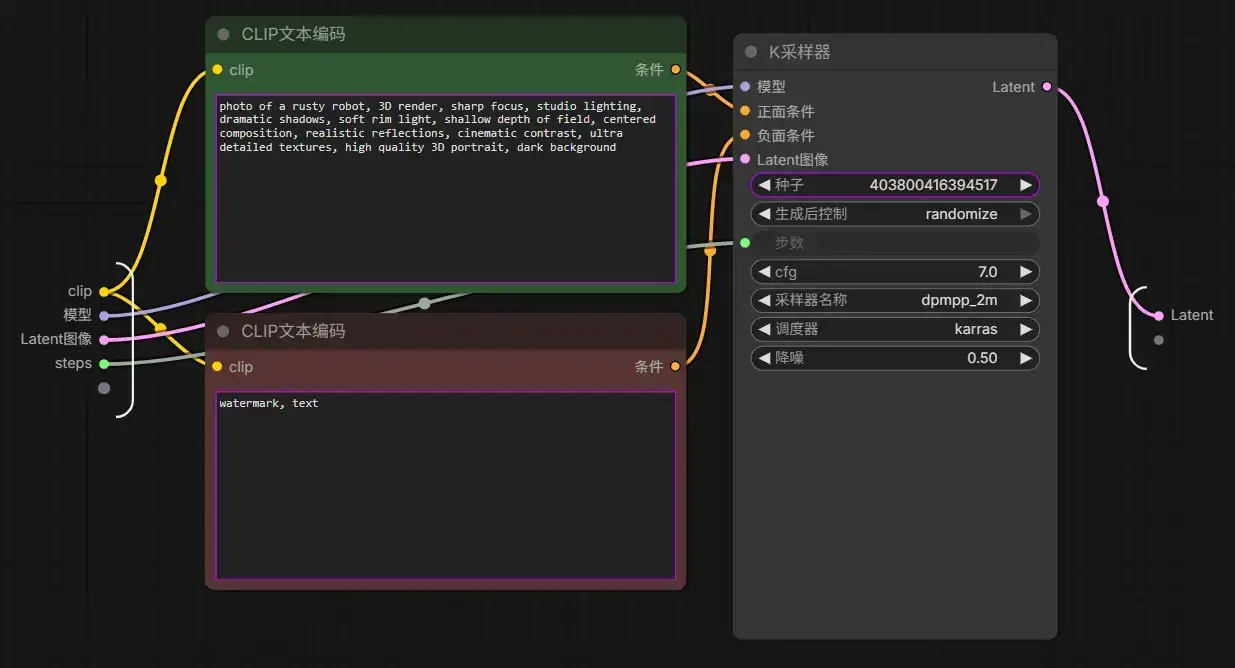
| 2 | CLIPTextEncode(Positive) | 将**正向提示词(Prompt)**编码成 AI 可以理解的向量(Conditioning) | CLIP | CONDITIONING | "photo of a rusty robot..." |
| 3 | CLIPTextEncode(Negative) | 将**反向提示词(Negative Prompt)**编码成向量,用于告诉模型不要生成什么 | CLIP | CONDITIONING | "watermark, text" |
| 7 | EmptyLatentImage | 创建一张空白 Latent(潜空间),相当于告诉模型最终图片尺寸 | 无 | LATENT | 512×512,Batch=1 |
| 4 | KSampler | 整个 AI 绘图最核心的节点,根据模型、Prompt 和随机噪声一步步去噪生成 Latent 图像 | MODEL、Positive、Negative、Latent | LATENT | 35 Steps、CFG=7、DPM++ 2M、Karras |
| 5 | VAEDecode | 将 Latent(模型内部表示)解码成真正的 RGB 图片 | LATENT、VAE | IMAGE | 使用模型自带 VAE |
| 6 | SaveImage | 保存图片到输出目录 | IMAGE | 无 | 文件名前缀 ComfyUI |
| 9 | MarkdownNote | 备注说明节点,仅用于给作者写说明,不参与计算 | 无 | 无 | 下载模型、教程链接等说明 |
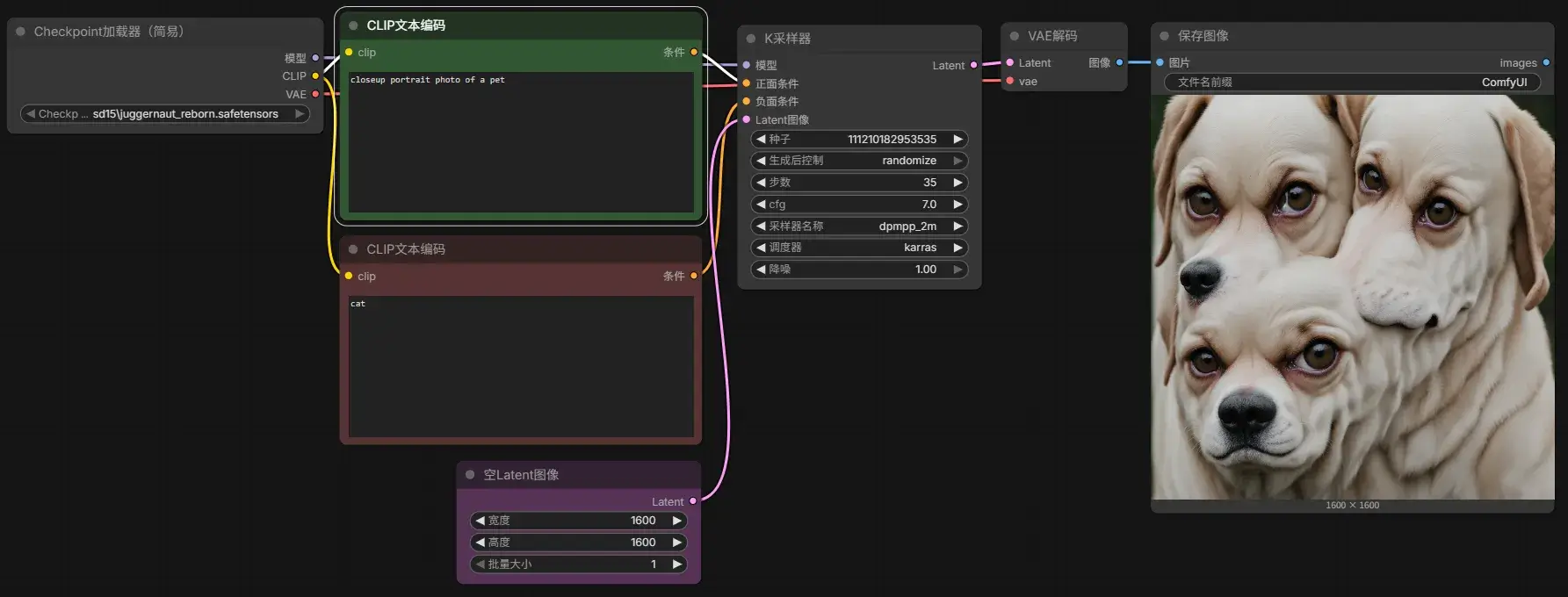
如我想画一张 closeup portrait photo of a pet,但是不希望 cat:
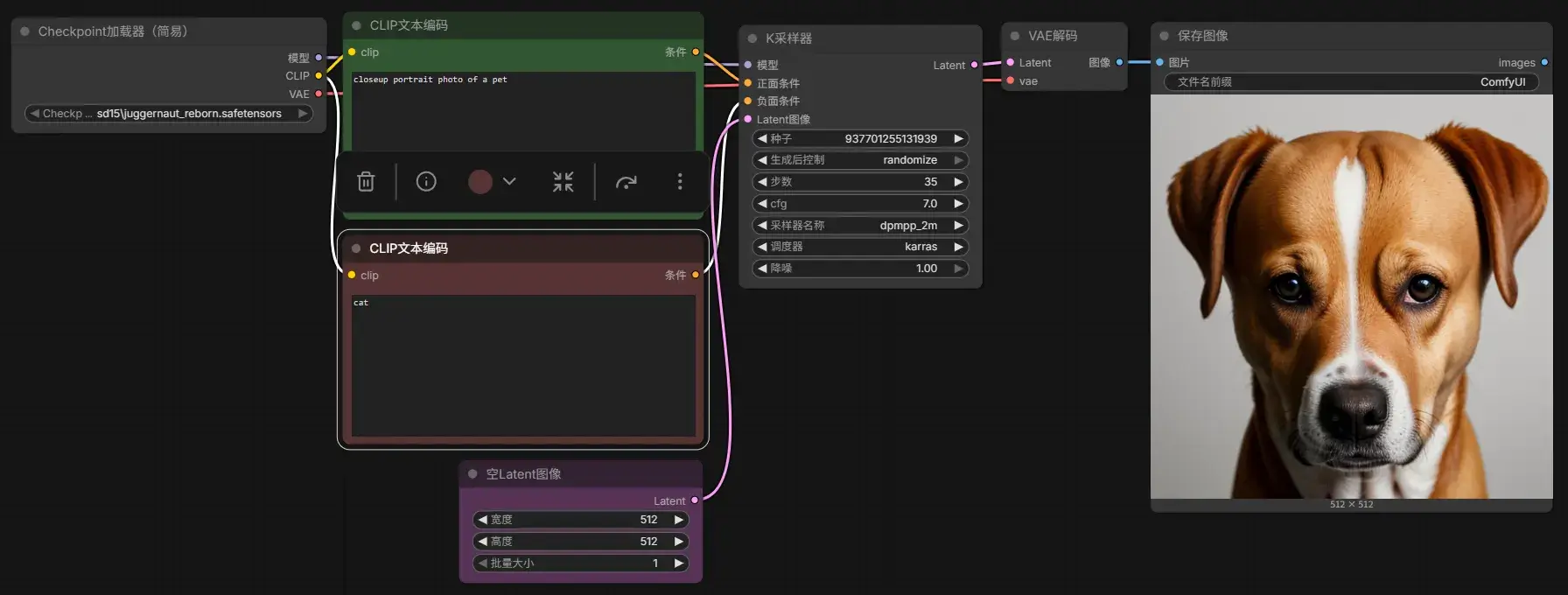
对于当前模型,如果 EmptyLatentImage 的尺寸设得太大(如 1600 x 1600),会导致出图时间慢且出现提示词之外的东西。这是因为当前模型仅是在 512 x 512 的图片数据下训练的,它将难以理解更大的图像空间。
第 8 章 – 保存、导出和导入工作流
提示
日常编辑 → 用 Save / Save As。
备份、分享、发给别人 → 用 Export。
程序调用(Python、API) → 用 Export API。
保存的工作流存储在 Comfy-Desktop/ComfyUI-Installs/ComfyUI/ComfyUI/user/default/workflows,可在左侧菜单中快速找到:
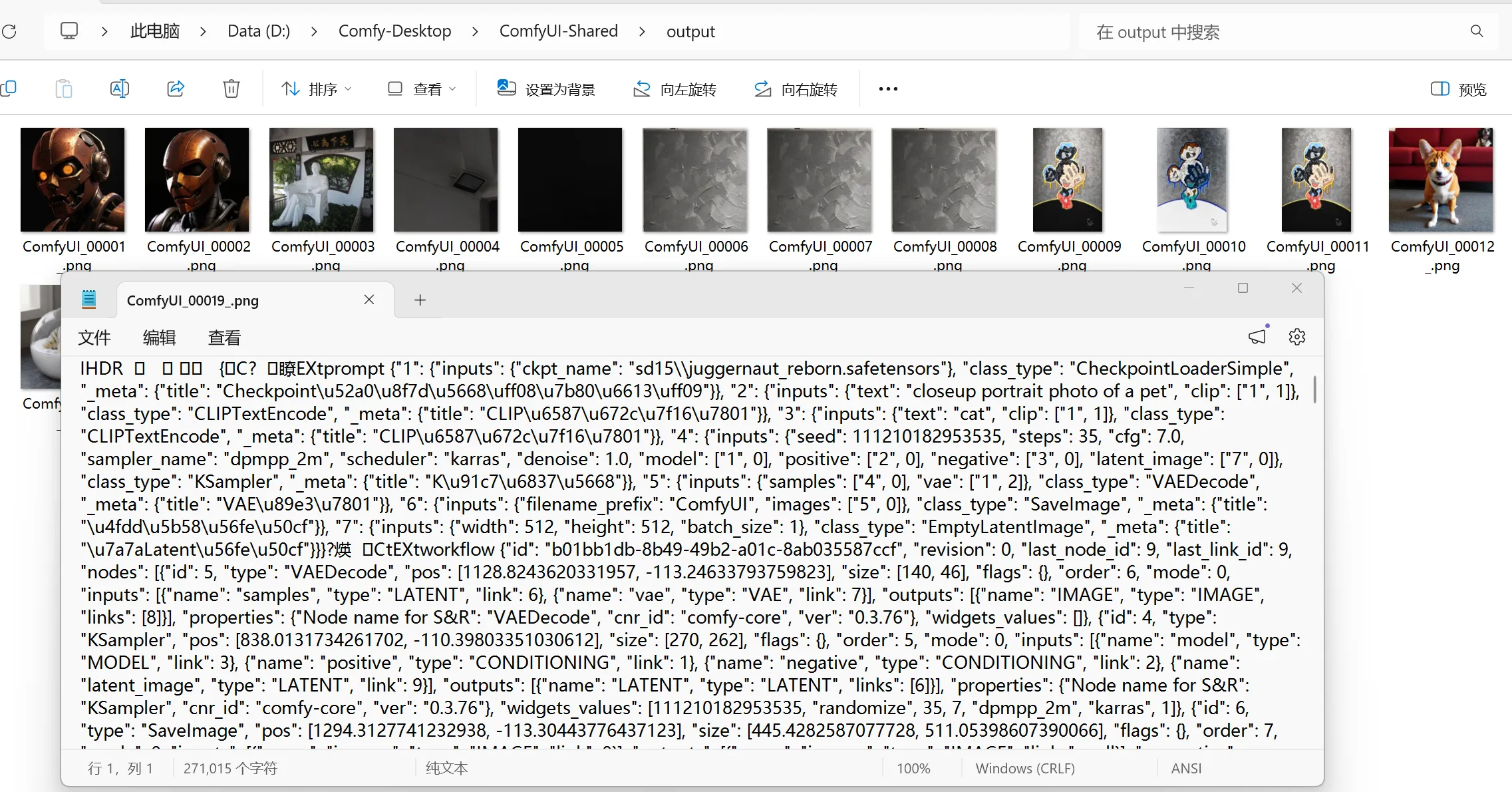
如果用记事本打开 ComfyUI 生成的图片,会看到图片中还藏有工作流的信息,所以如果直接让 ComfyUI 打开这张图,将会还原这张图生成时的工作流:
第 9 章 – ComfyUI 文件夹结构与组织
| 文件夹 | 用途 |
|---|---|
comfy/ | ComfyUI 核心代码 |
models/ | 所有 AI 模型 |
custom_nodes/ | 第三方节点插件 |
input/ | 输入图片 |
output/ | 输出图片 |
temp/ | 临时缓存 |
user/ | 用户配置、工作流等 |
web/ | 前端网页资源 |
extra_model_paths.yaml | 外部模型映射 |
第 10 章 – 更新 ComfyUI 和管理自定义节点
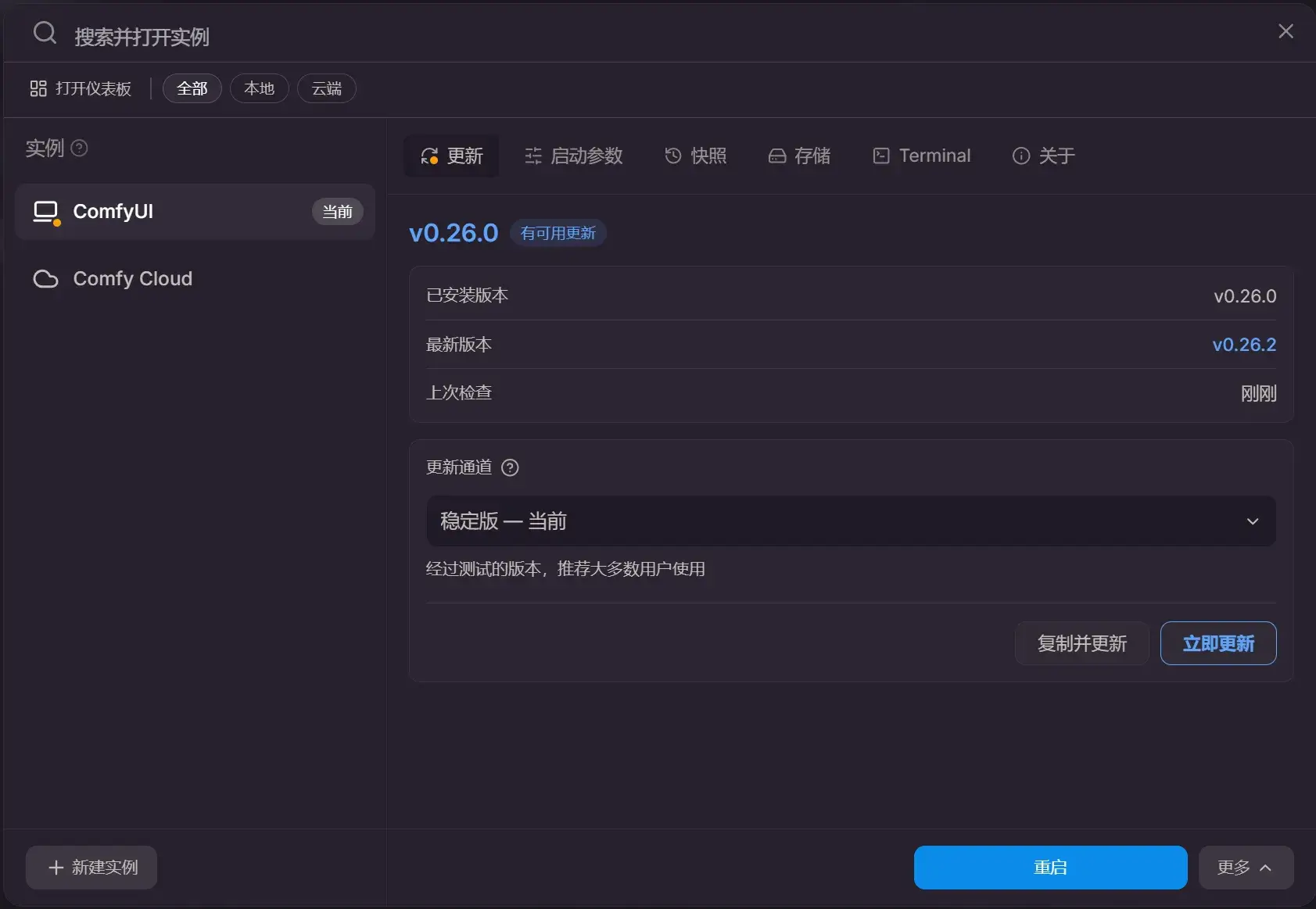
原课程用的 ComfyUI-Easy-Install,通过使用相应的 .bat 进行更新。Desk top 就比较傻瓜式了。
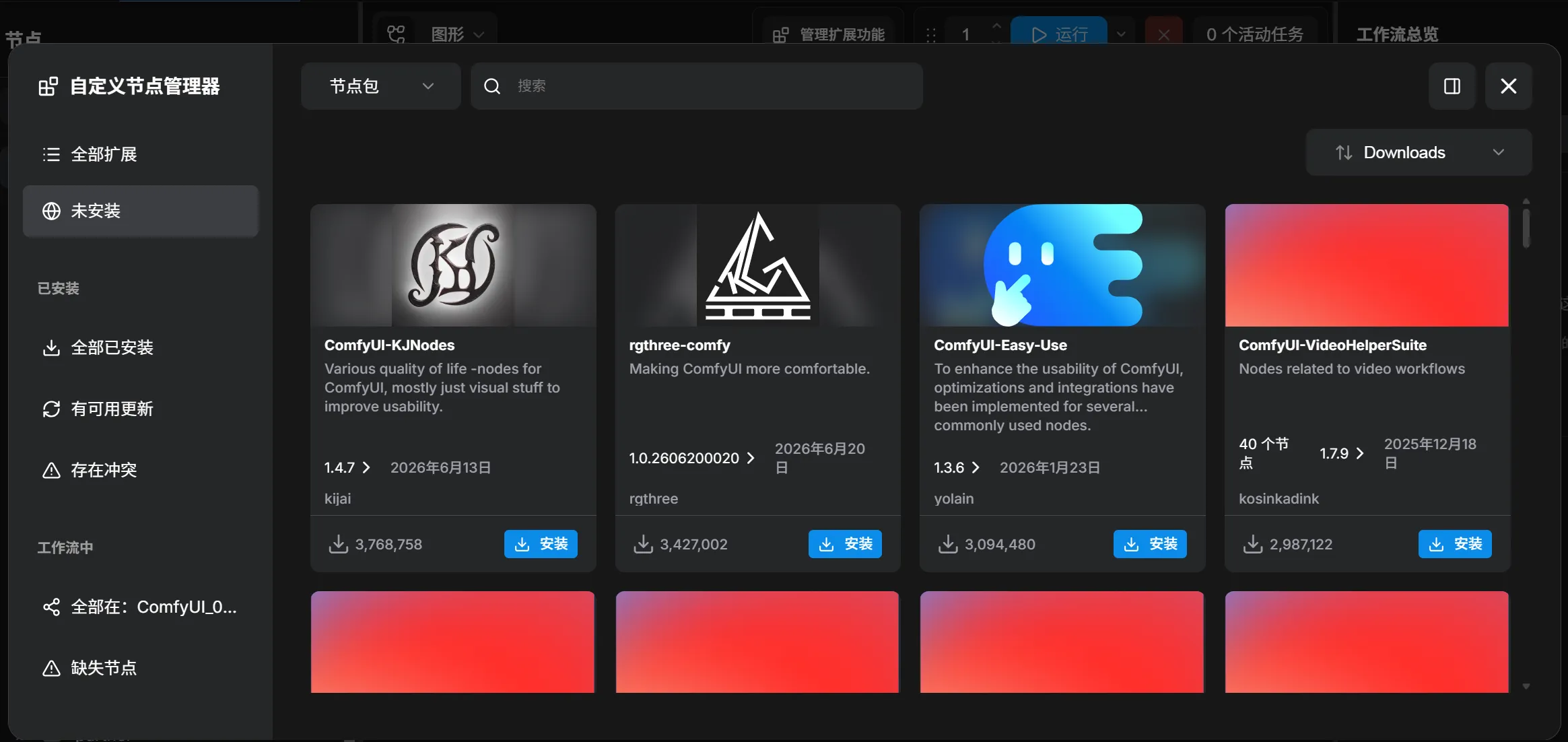
从管理扩展功能处下载更多节点,这里下载并安装 rgbthree-comfy(重启后生效):
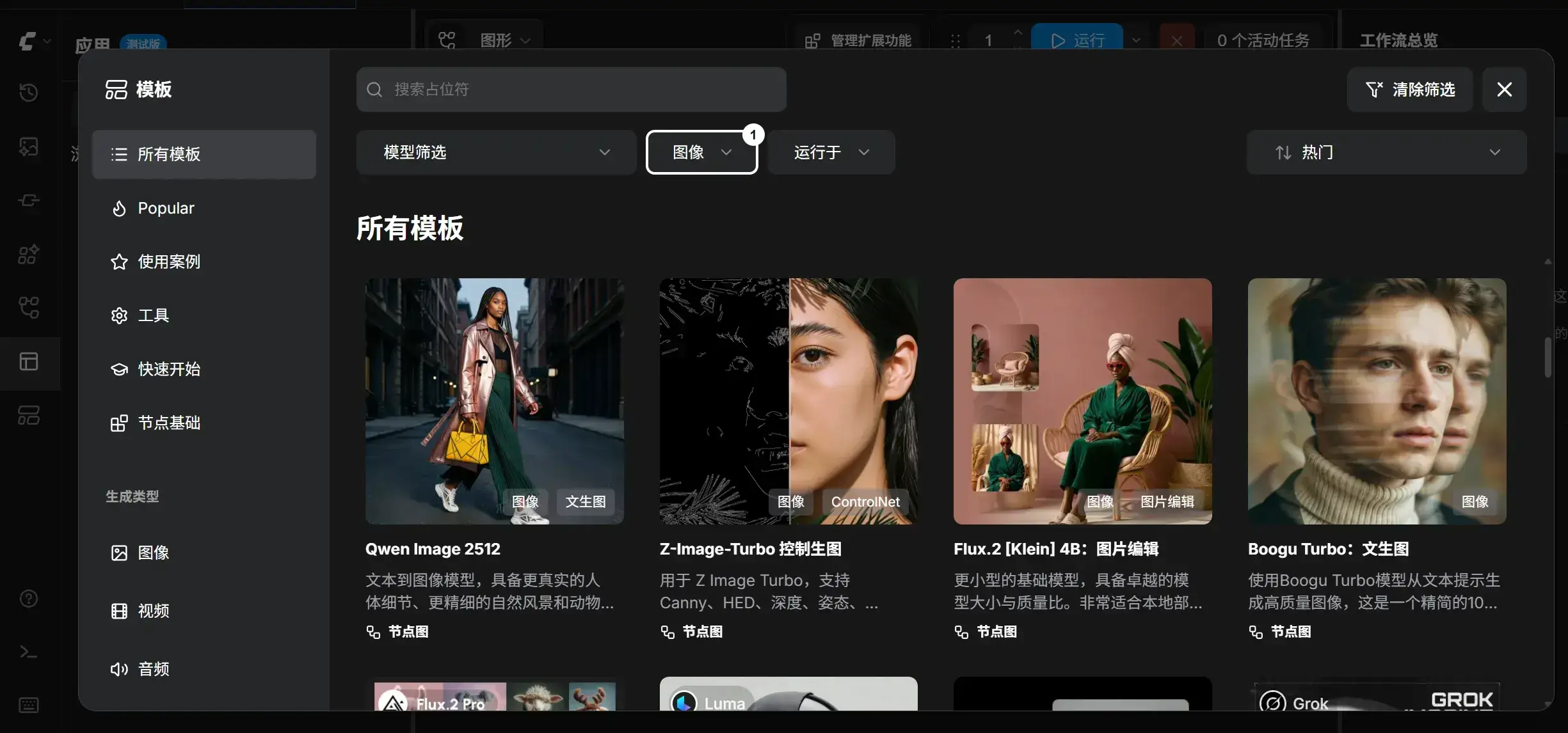
从模板出下载其它工作流(通常需要额外下载对应的模型或节点):
第 11 章 – 扩散模型、KSampler、图生图基础
提示
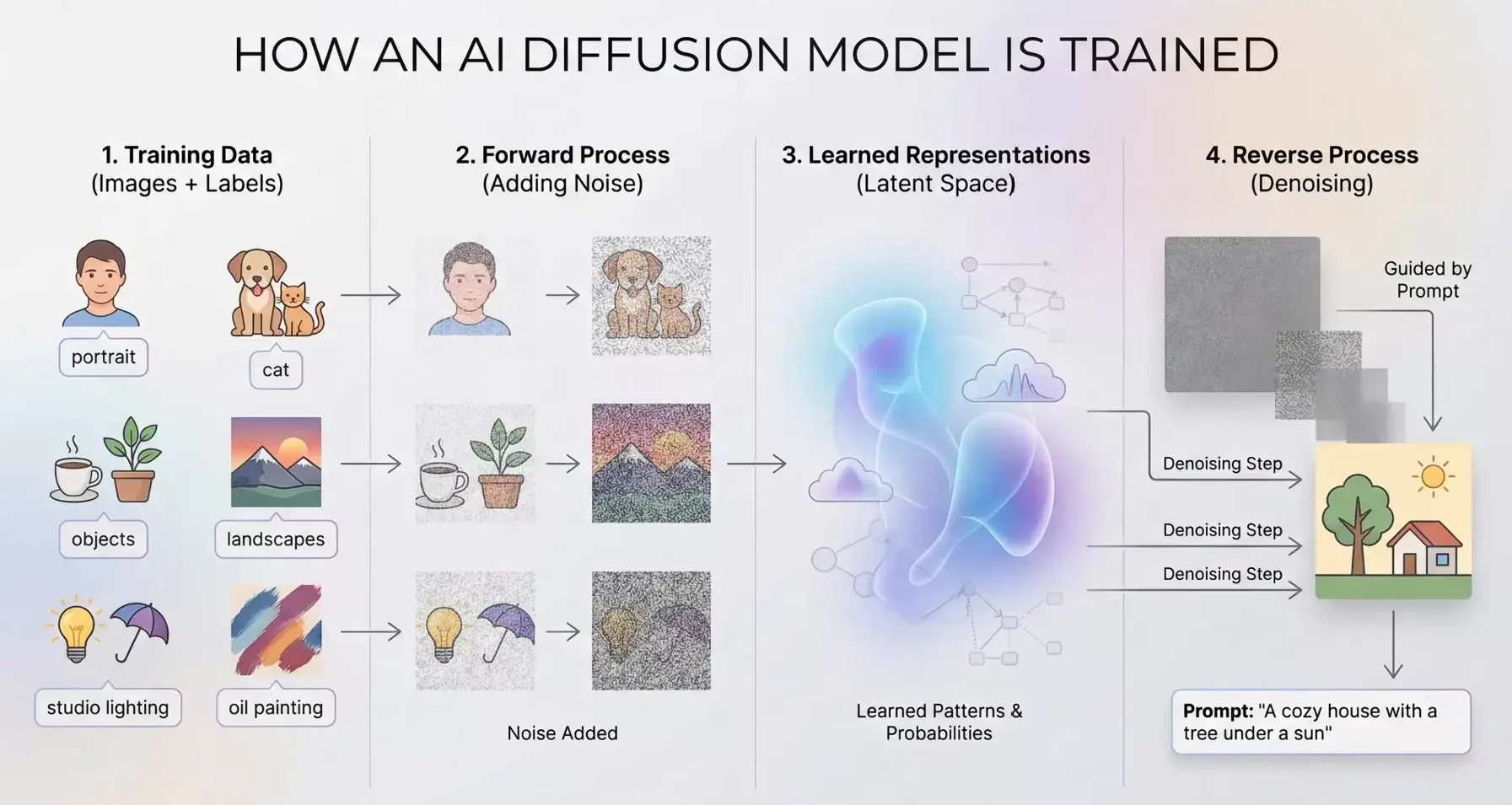
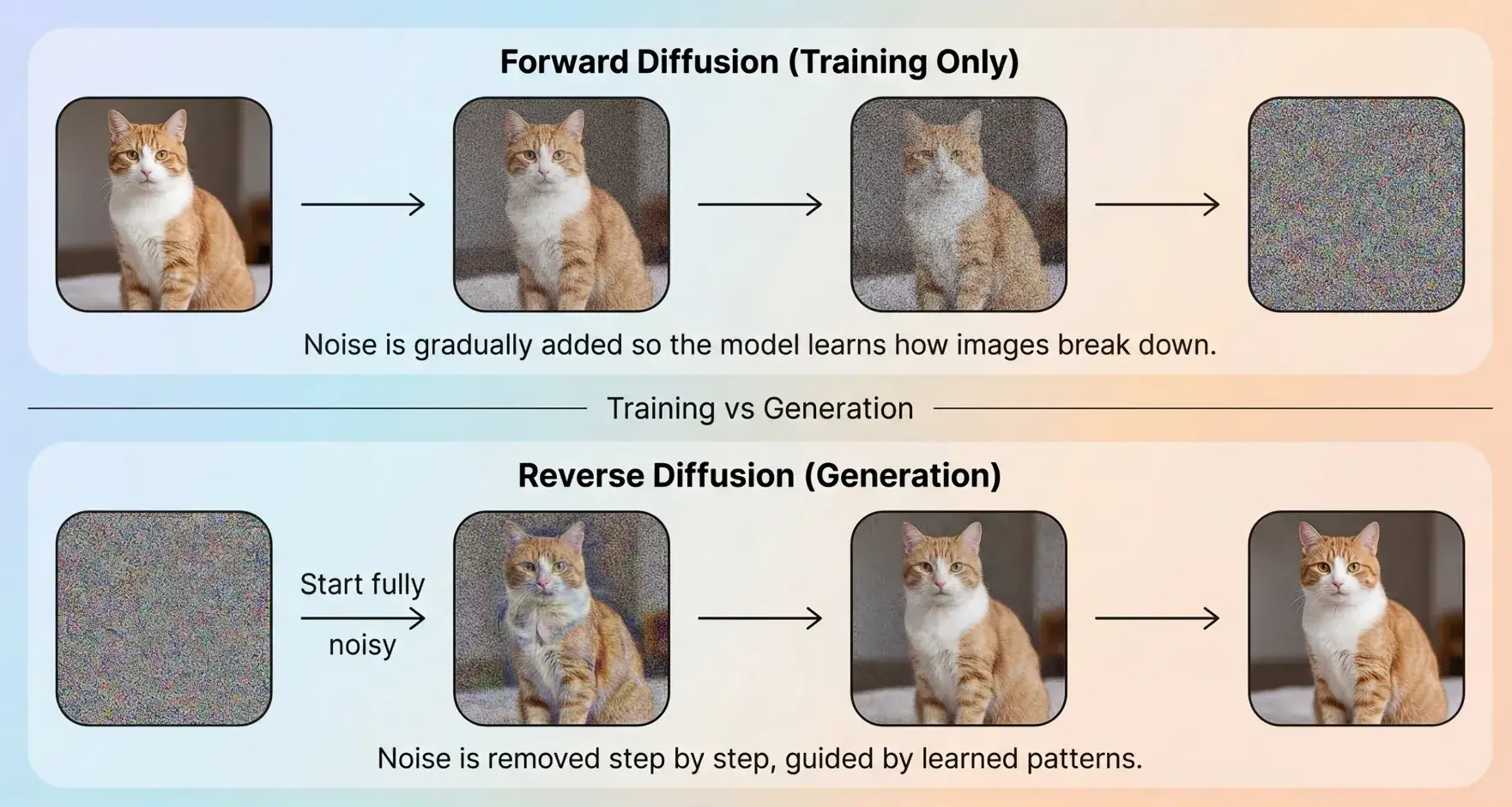
扩散模型的核心思想是:先学会如何把一张完全被噪声污染的图片一步步“去噪”,然后反过来利用这个能力从随机噪声生成全新的图片。
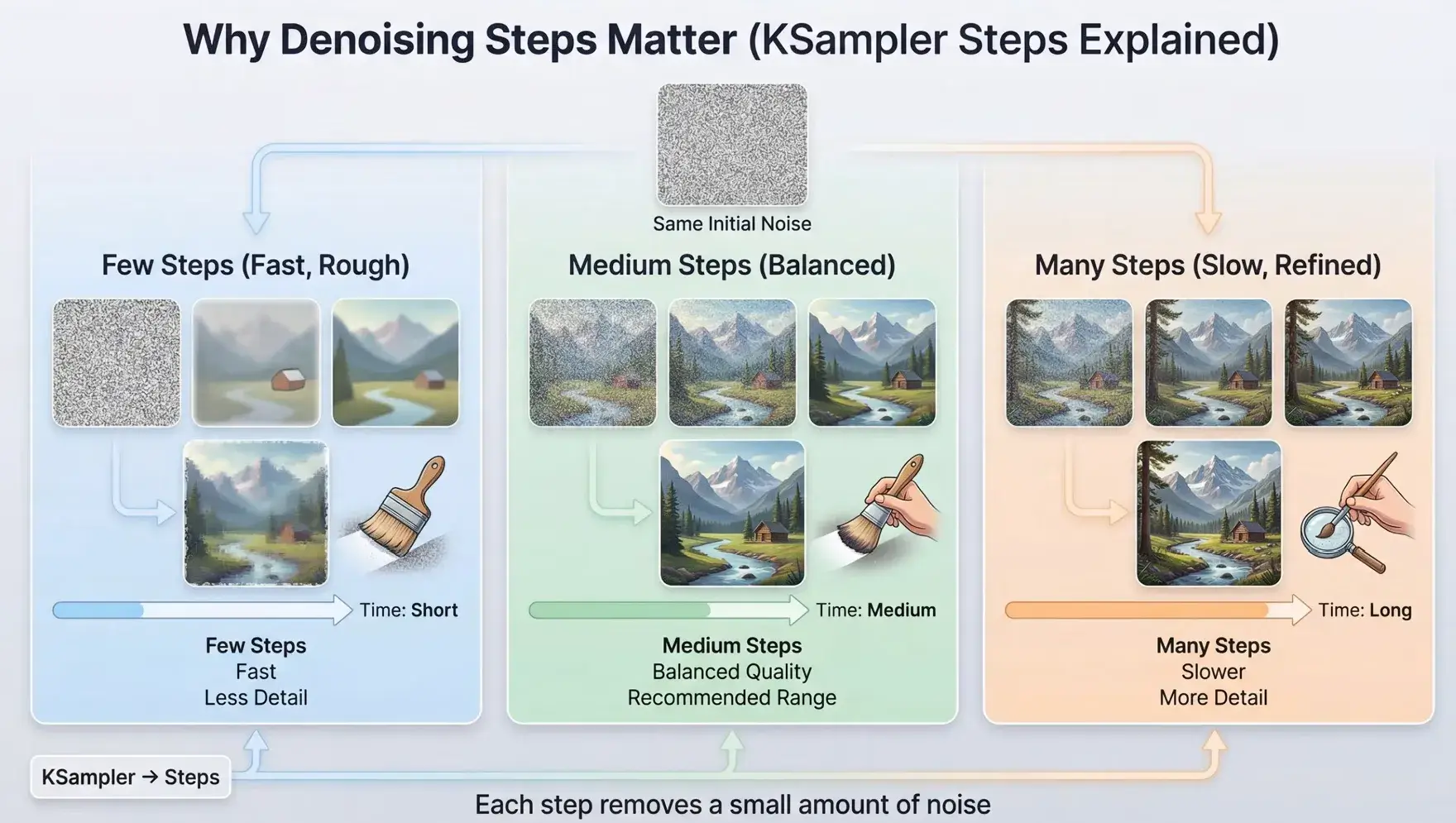
当采样次数过少时,生成的图像像是噪声。steps 越多,计算开销越大,生成效果往往越好直至趋于稳定。
使用递增的 Primitive 作为 stps。执行 运行(实时),工作流将一直运行直到人工干预。
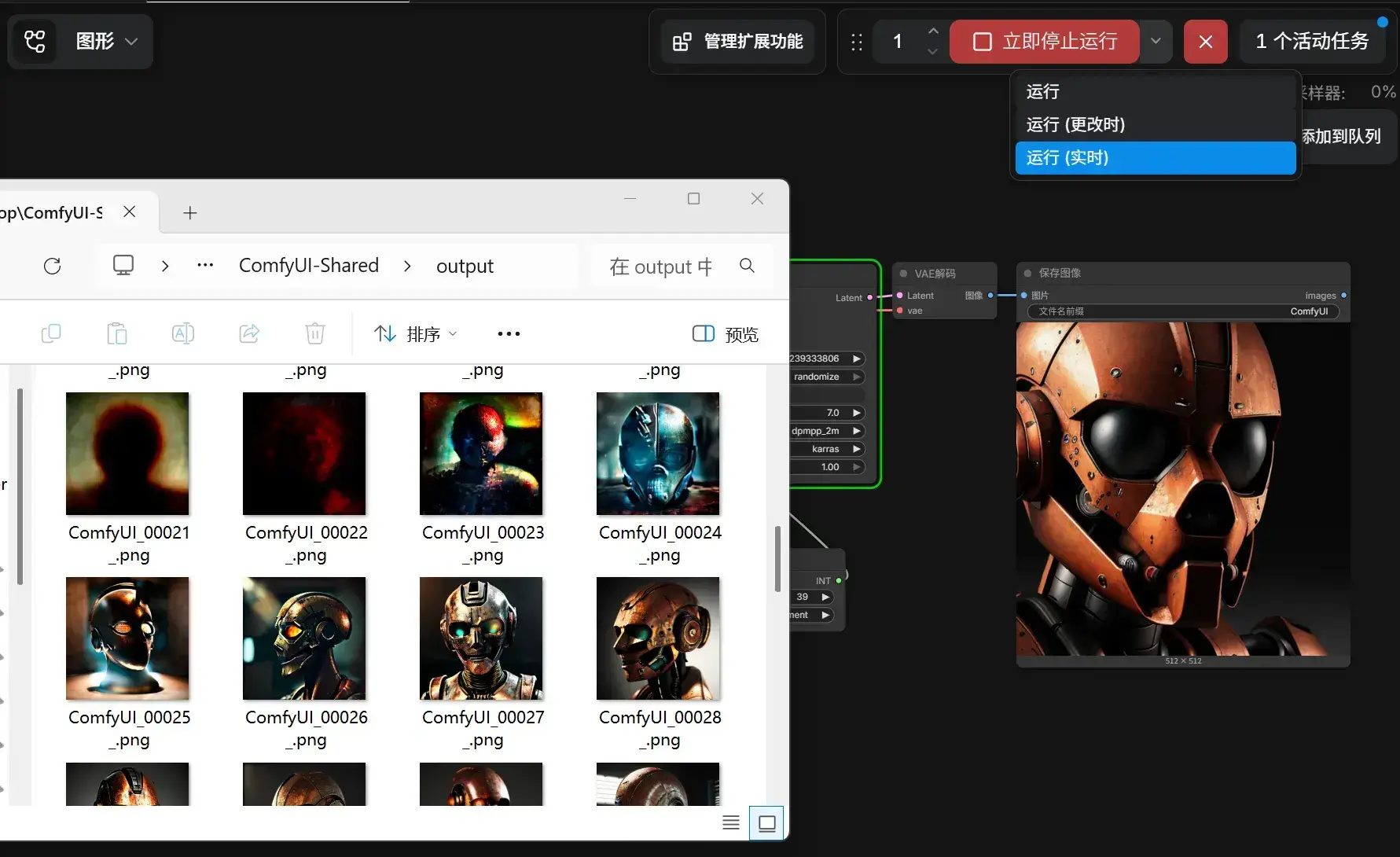
可在设置中调整以查看模型绘制的过程。

扩散模型的原理展示:
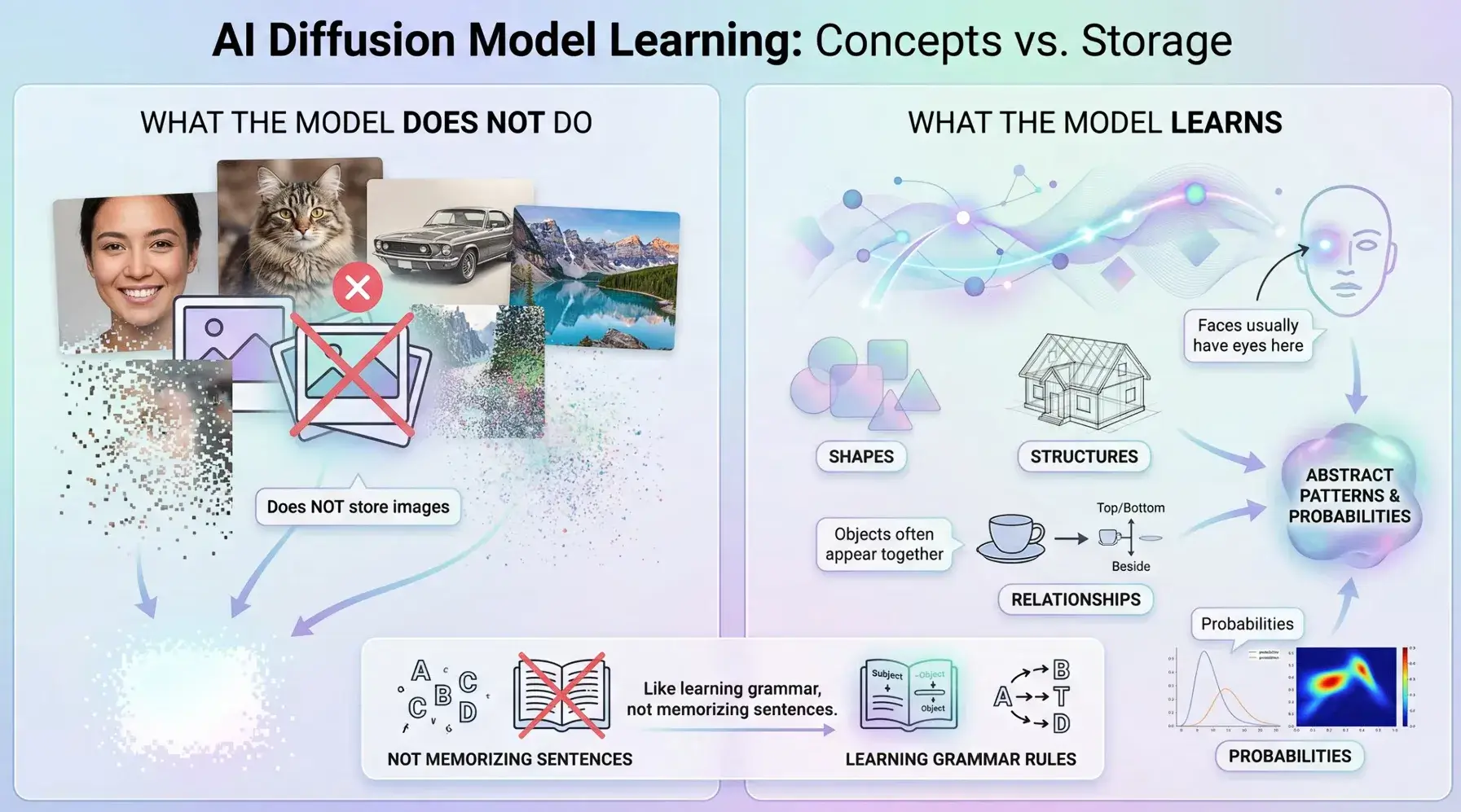
模型不会存储照片,而是物品的各个特征。
提示
Pixel Space:人类看得懂的真实图片(PNG、JPG 等)。
Latent Space:AI 看得懂的压缩表示,扩散模型在这里进行生成和去噪。
VAE Decode:把 AI 内部的潜变量「翻译」回人类可以查看和保存的图片;对应的 VAE Encode 则完成相反的转换。

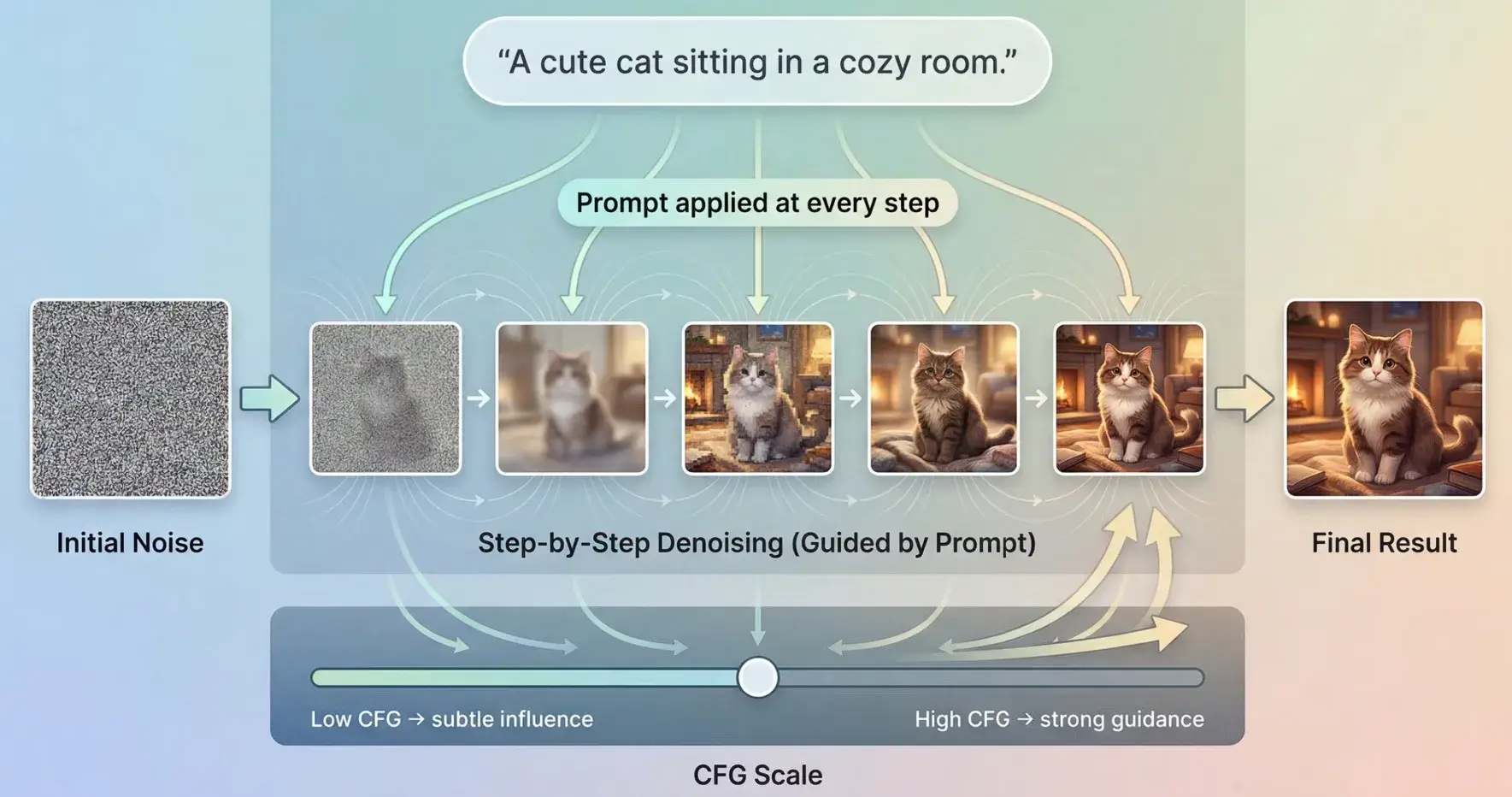
文本提示词用于指导降噪过程,cfg 用于控制文本提示词对图像的影响力度(越低模型将约忽略提示,过高可能导致图像不自然)。
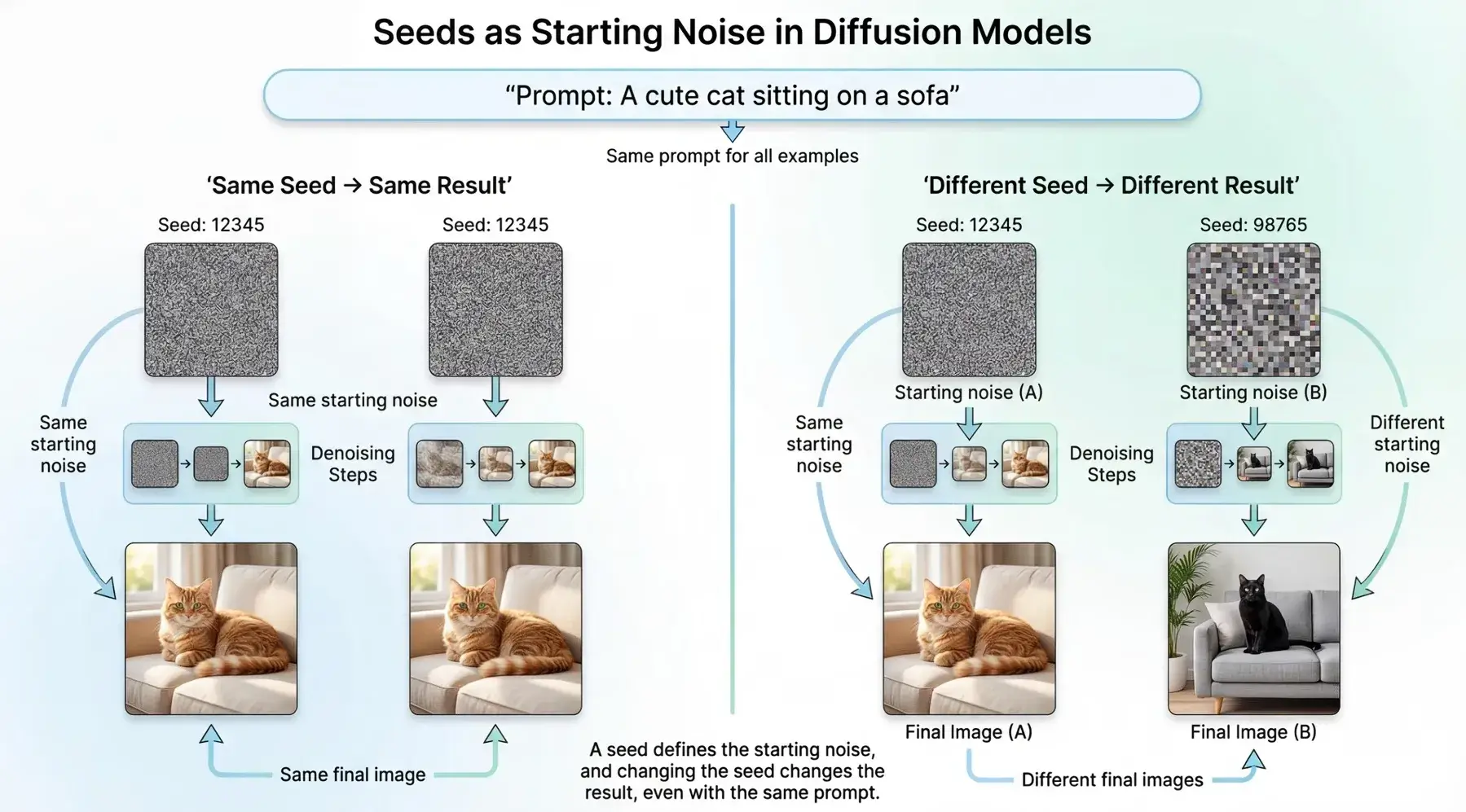
随机数种子决定了初始噪声图的样子,从而导致最终生成图样式的差异。
重要的文本提示词应尽可能放在前面。可以通过 () 增强文本提示词。
KSampler 中steps 与生成图像的关系示意图如下。
现在打开 2 Juggernaut Reborn img2img.json,如果将初始的噪声图换成其它现有的图片,并连上 VAE Encoder 即可实现简易的图生图,降噪程度(0 到 1 之间)决定了图像将会被修改的幅度:
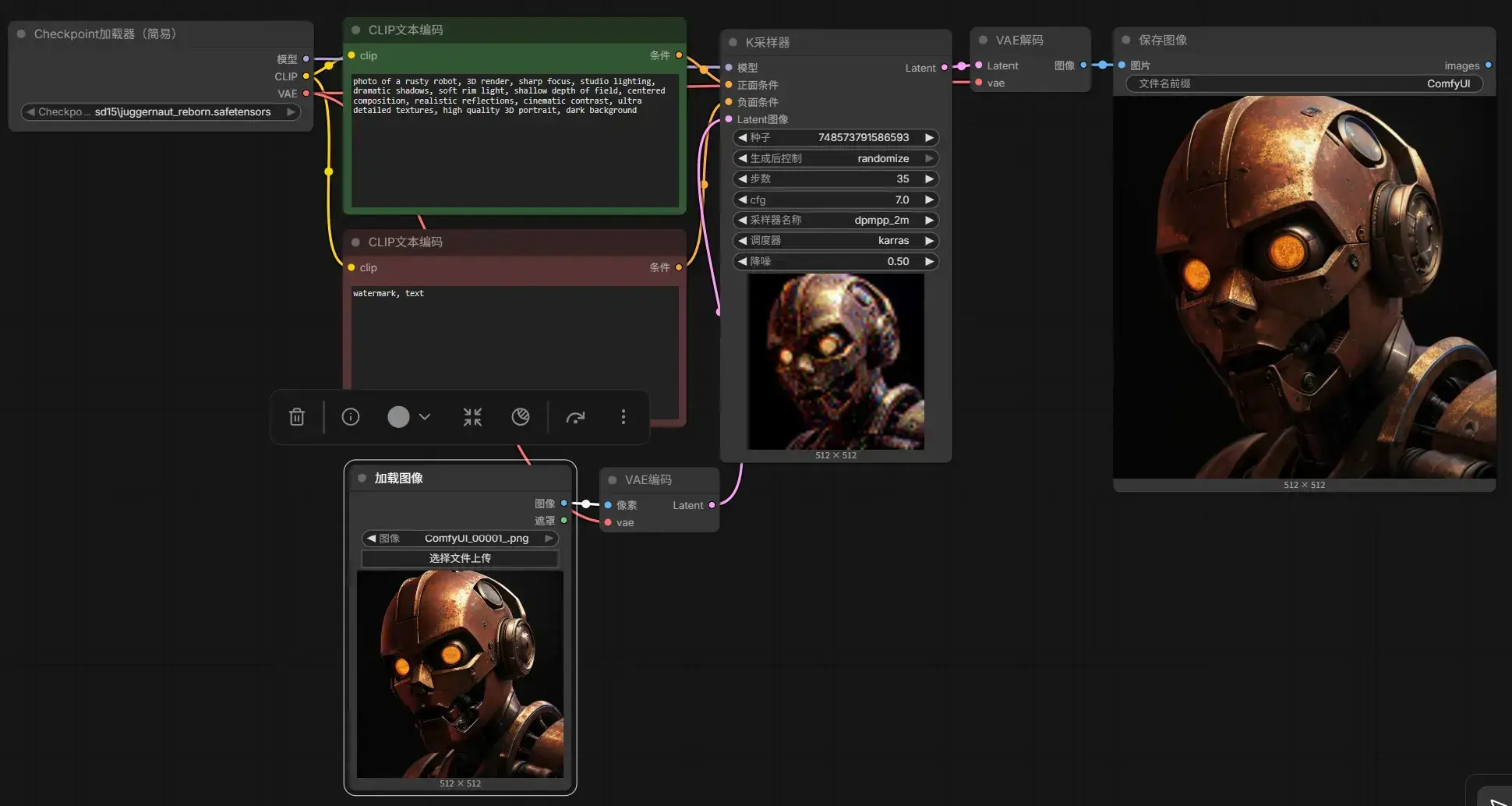
使用 rgbthree-comfy 的 Image Comparer 节点可直观地展示两张图的差异:
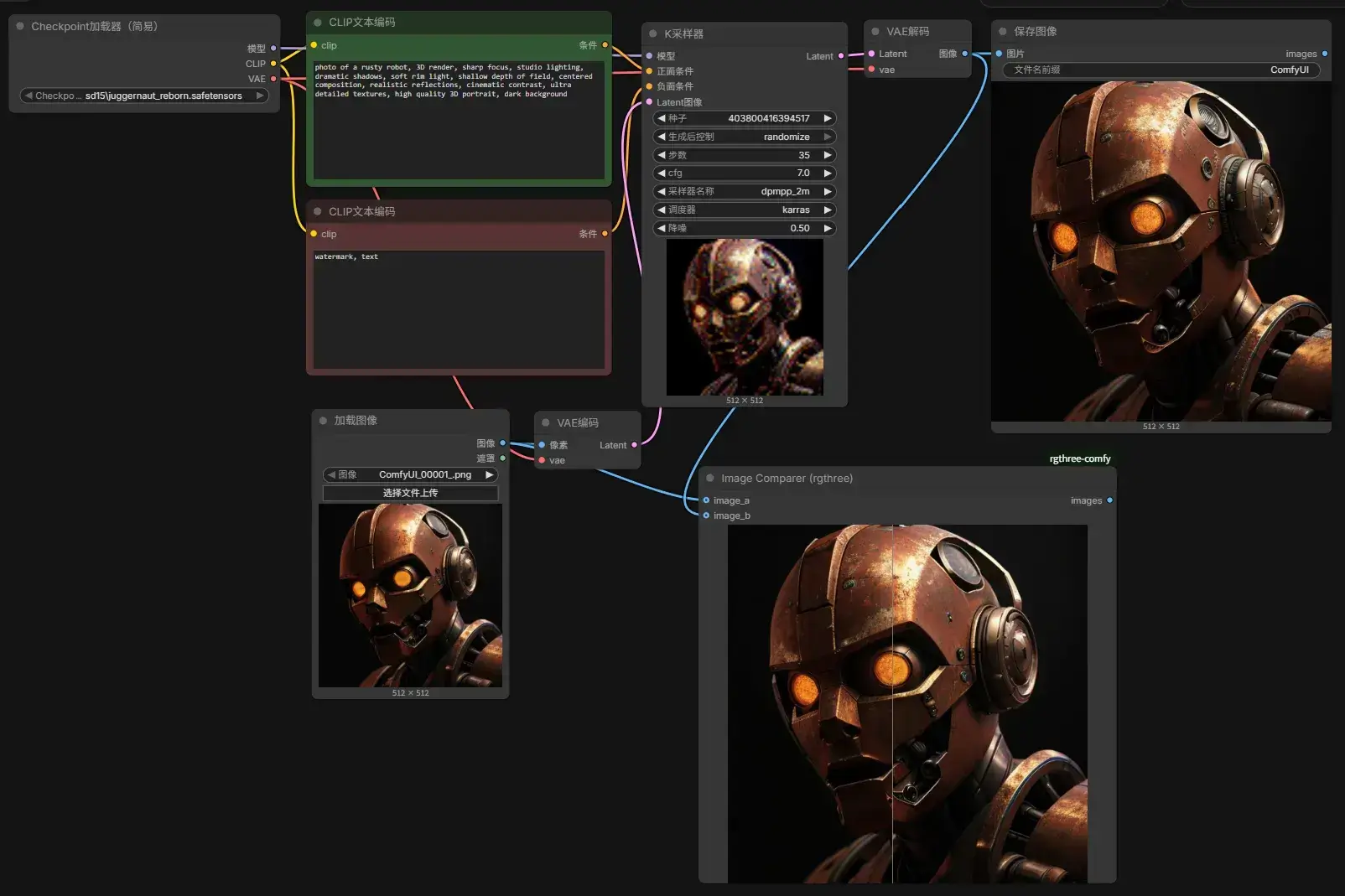
扩散模型中,Sampler 决定"怎么走",Scheduler 决定"什么时候走到哪里"。都会影响图像的生成的速度和结果。不是所有 Sampler 都能与所有 Scheduler 任意组合。一些调度器是为特定采样算法设计的,而某些新模型(例如 FLUX 或部分 SDXL 工作流)也会推荐特定的组合。
提示
假设:从 A 地开车去 B 地。Sampler 决定怎么开车(开高速、走国道、绕拥堵、急刹车),Scheduler 决定什么时候减速,什么时候加速。
第 12 章 – 子图
将众多节点合并起来,在视觉上看着不会那么糟。
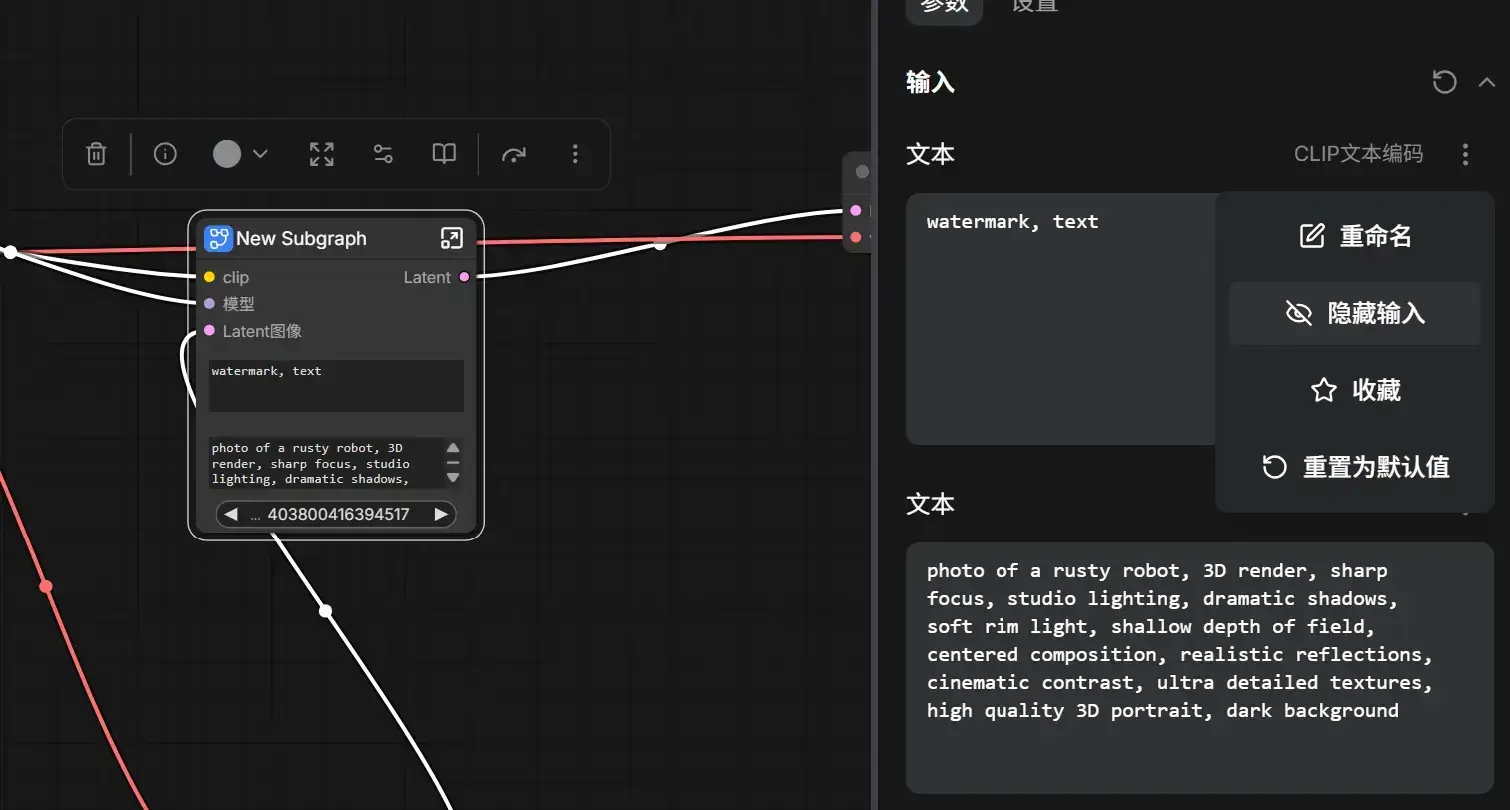
在子图中设置哪些参数可以暴露:
空白处右键可将当前选中的节点保存成模板。
第 13 章 – 在工作流中使用 LoRAs
提示
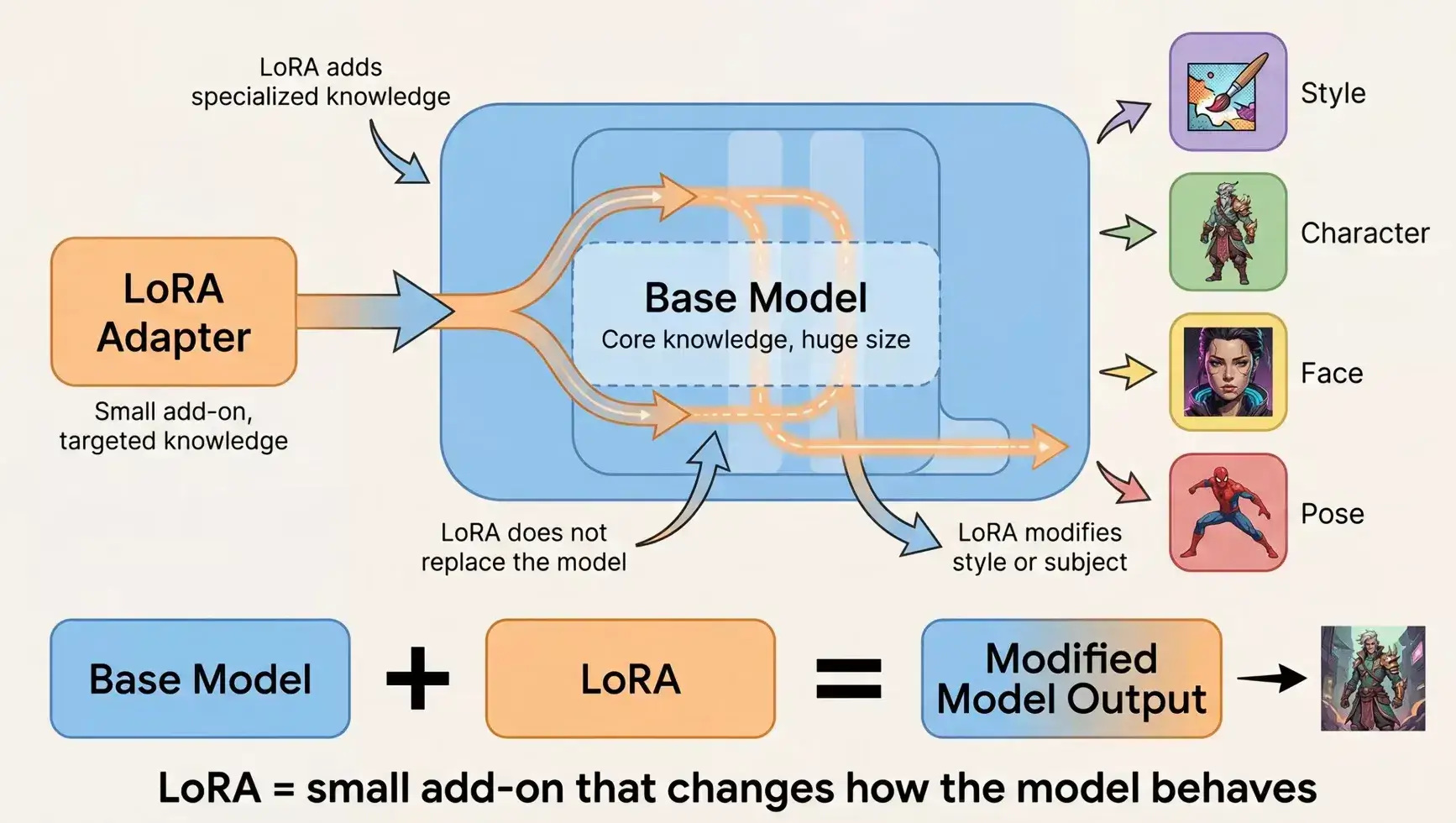
LoRA 能在不改动大模型的前提下,用一个很小的“外挂参数包”为扩散模型增加特定风格或概念的能力。
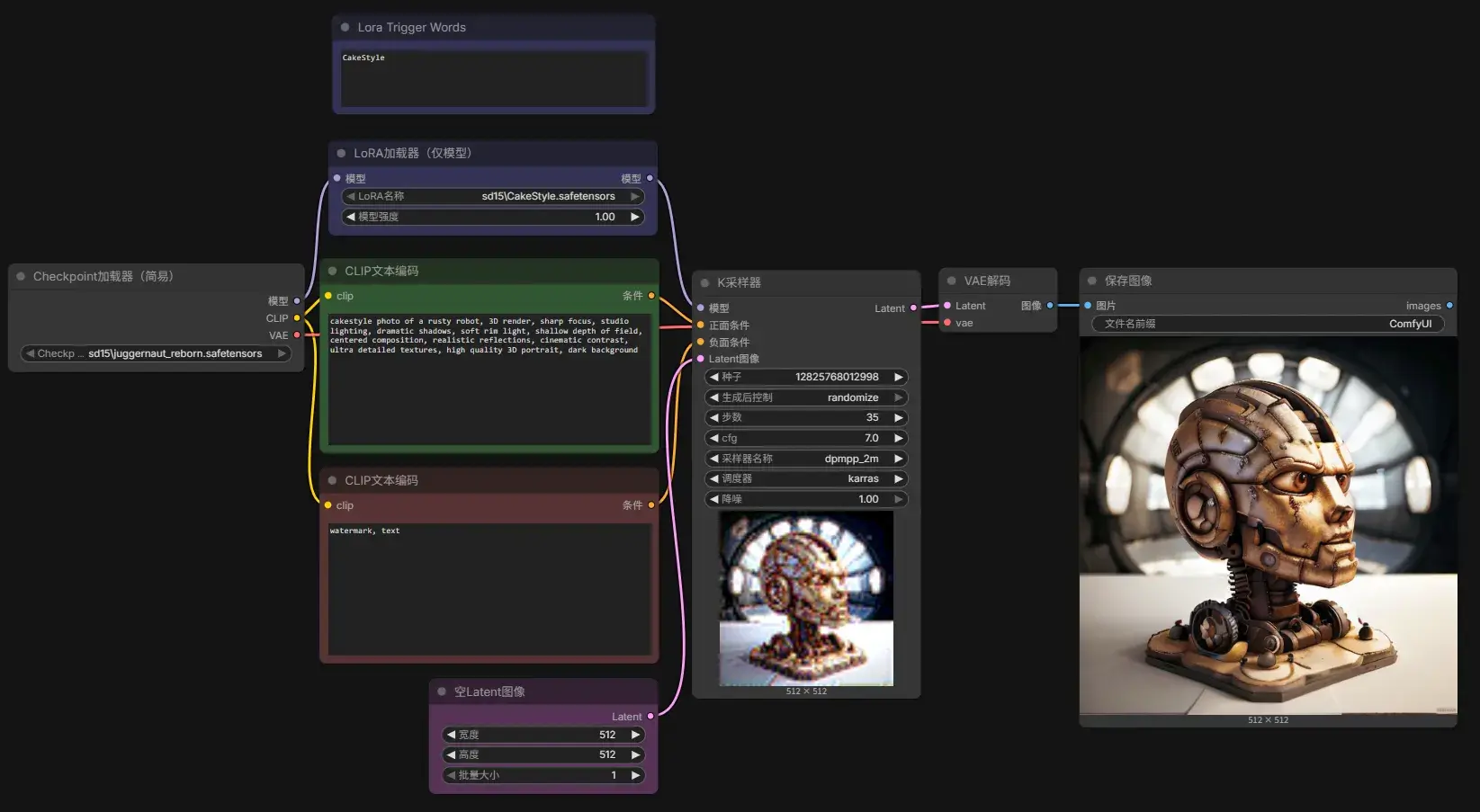
加载 3 Juggernaut Reborn txt2img + Lora.json,按照提示下载 CakeStyle.safetensors 放置在 Comfy-Desktop/ComfyUI-Installs/ComfyUI/ComfyUI/models/loras/sd15。它能让模型更懂提示词 cakestyle。
通过在 Load Checkpoint 和 KSampler 之间加入节点 LoraLoaderModelOnly。开跑,得到 cakestyle 的 robot。通过调整参数可调整 LoRA 的力量。
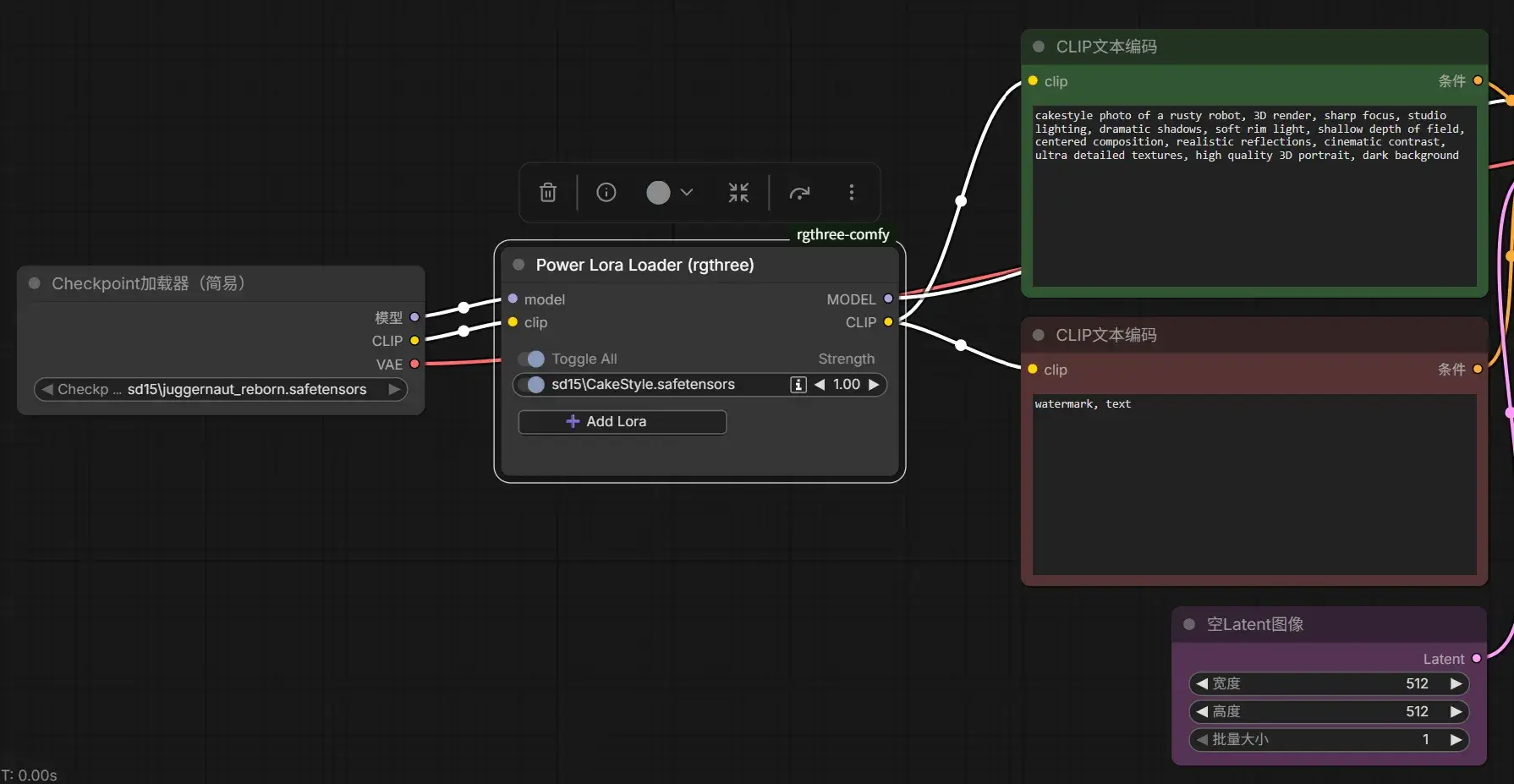
使用 rgbthree-comfy 的 Power Lora Loader 节点可以得到增强的 LoRA 加载能力。
按下 [i] 按钮可查看该 LoRA 的详细信息。如果这个 LoRA 被 Civitai 网站收录,则可以 fetch 到关键的提示词信息。
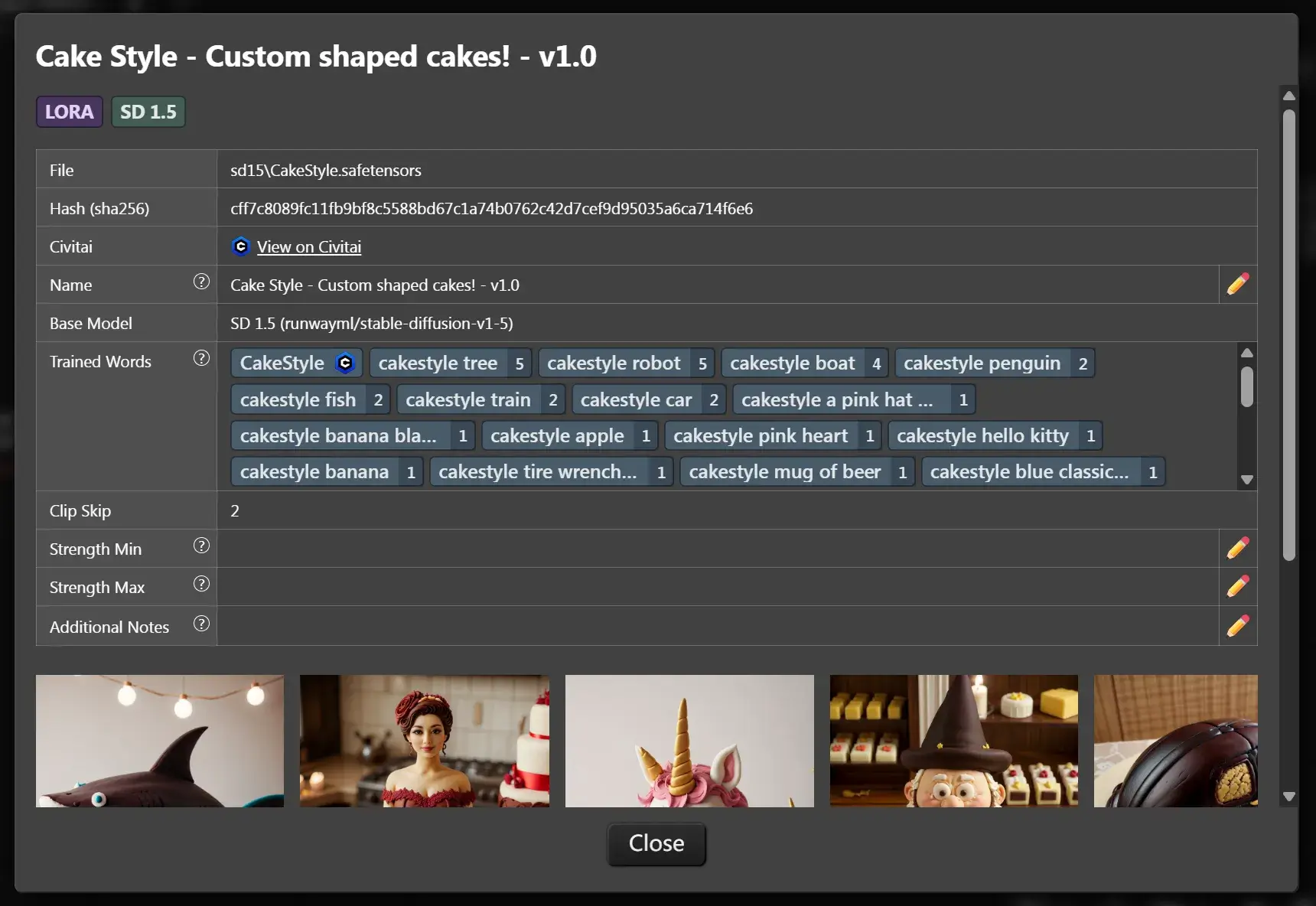
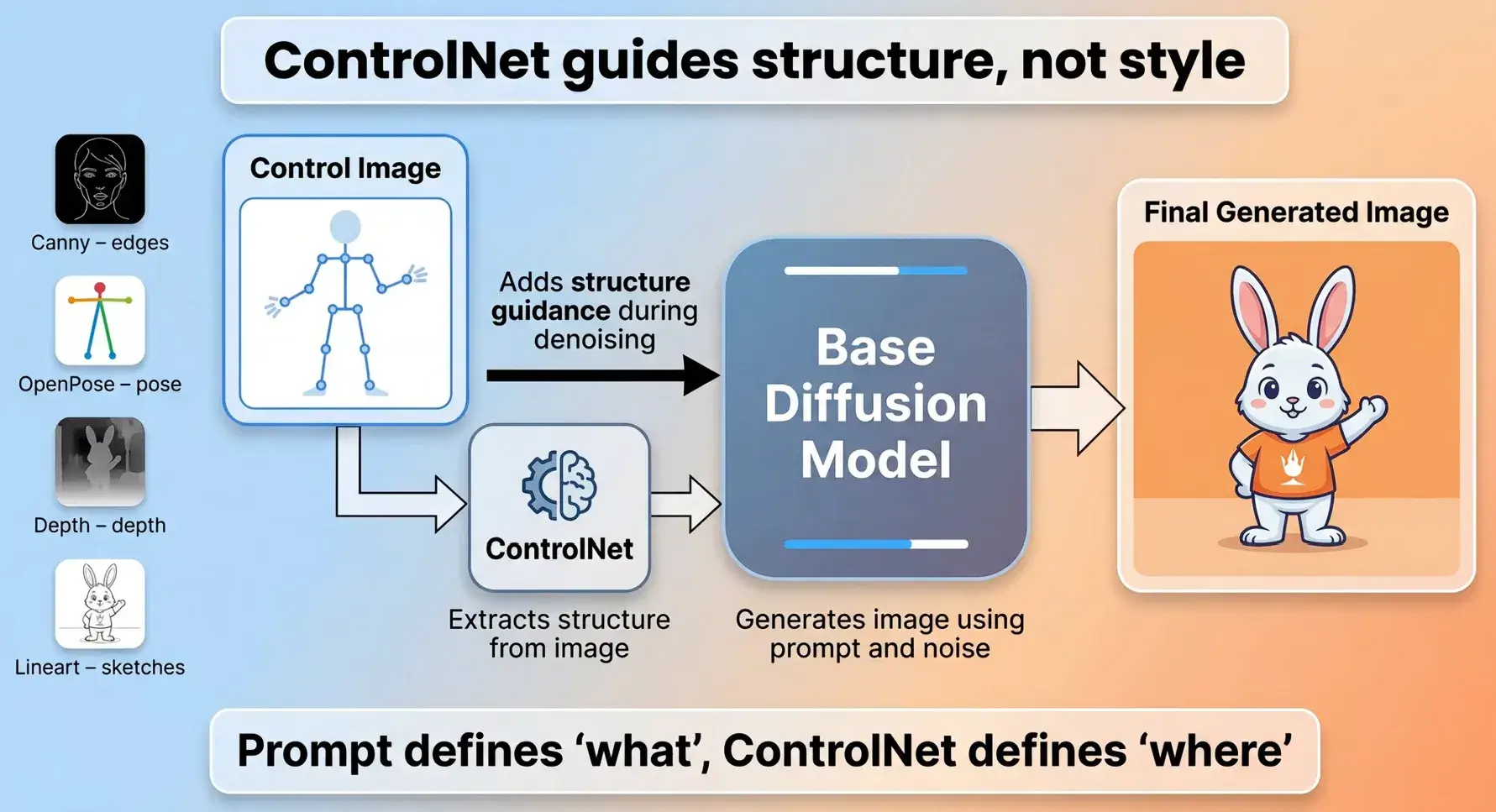
第 14 章 – ControlNet 基础
提示
ControlNet 是扩散模型中的一种条件控制技术(Conditional Control),它的作用是:在不改变模型画风和绘画能力的前提下,精确控制图片的结构、姿势、边缘、深度、构图等信息。
如果说:
- Checkpoint 决定"画家是谁";
- LoRA 决定"画家学会了什么新技能";
- ControlNet 决定"画家必须按照哪张草图来画"。

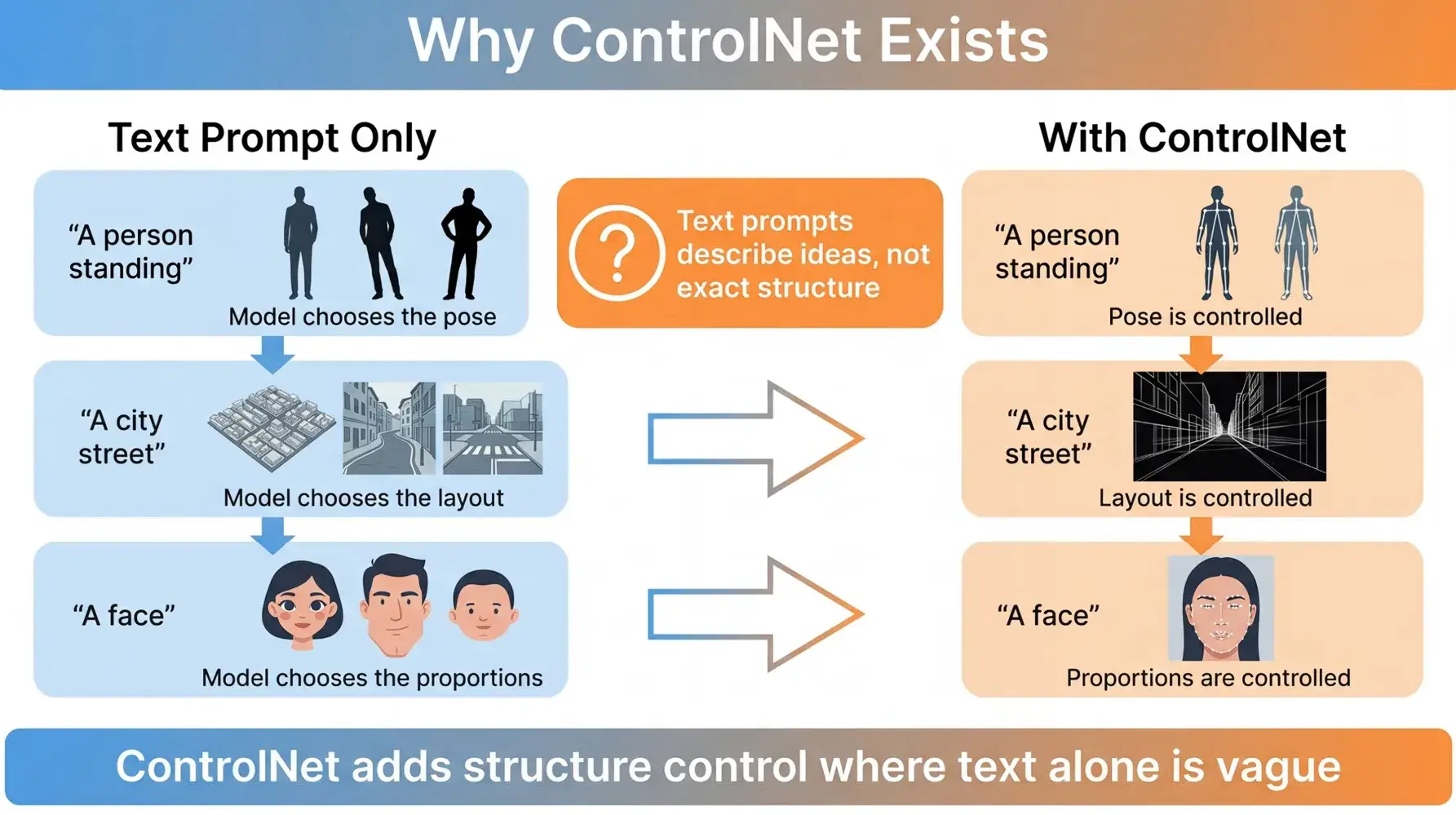
用文字描述想法可能不是很精确,ControlNet 引入了图像作提示。
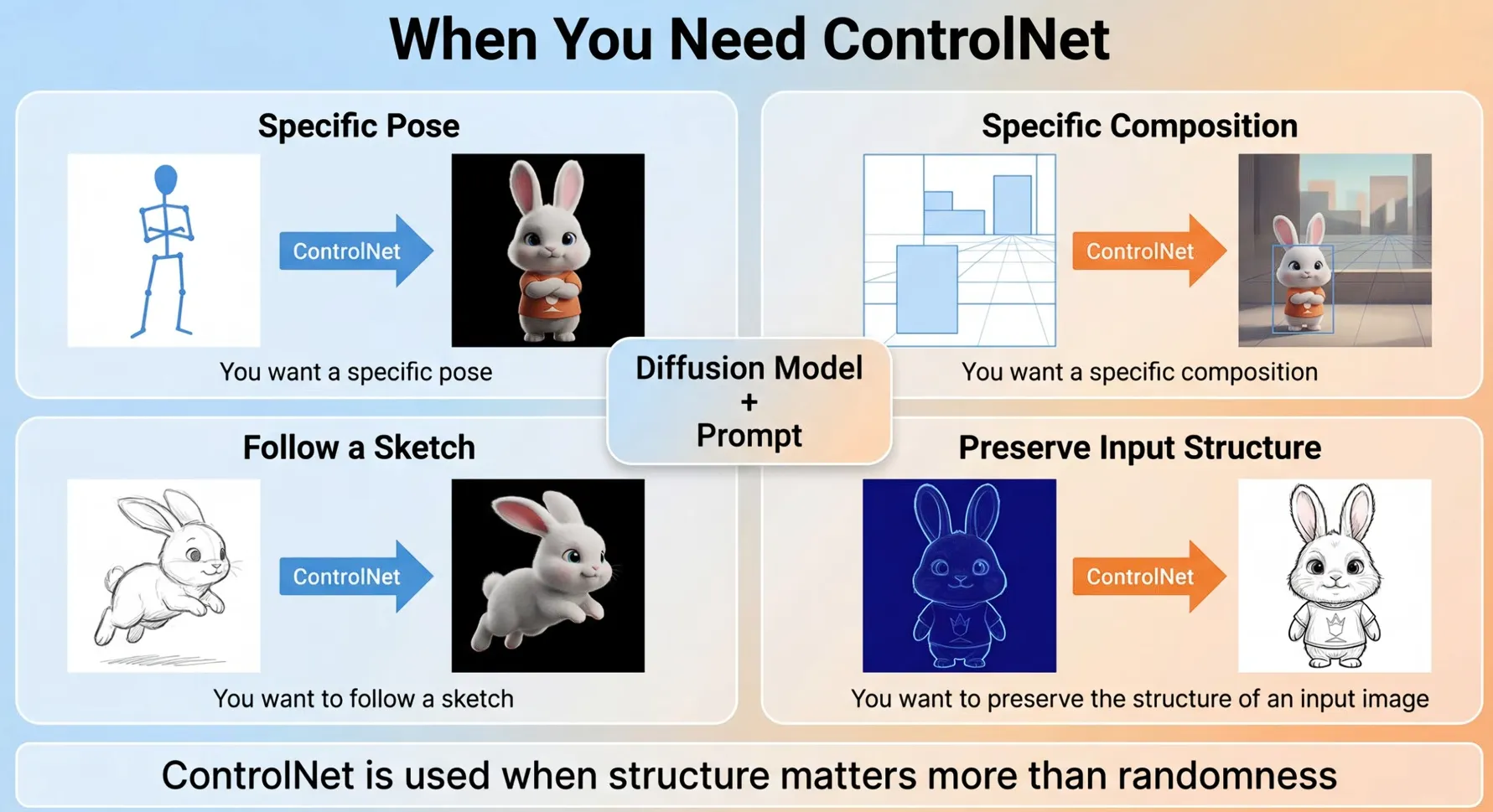
提示
| 输入 | ControlNet 提供的信息 |
|---|---|
| Canny | 边缘 |
| Depth | 深度 |
| OpenPose | 人体姿势 |
| Lineart | 线稿 |
| Scribble | 草图 |
| Seg | 分割图 |
加载 4 Juggernaut Reborn txt2img + ControlNet.json,按照提示下载
control_v11f1p_sd15_depth_fp16.safetensors、control_v11p_sd15_canny_fp16.safetensors和control_v11p_sd15_openpose_fp16.safetensors
放置在 Comfy-Desktop/ComfyUI-Installs/ComfyUI/ComfyUI/models/loras/sd15 中。
还要再装扩展节点 comfyui_controlnet_aux。
工作流中看到在 CLIP 后加上了 Apply ControlNet 节点。随便搜一张兔子的线稿图然后开跑:
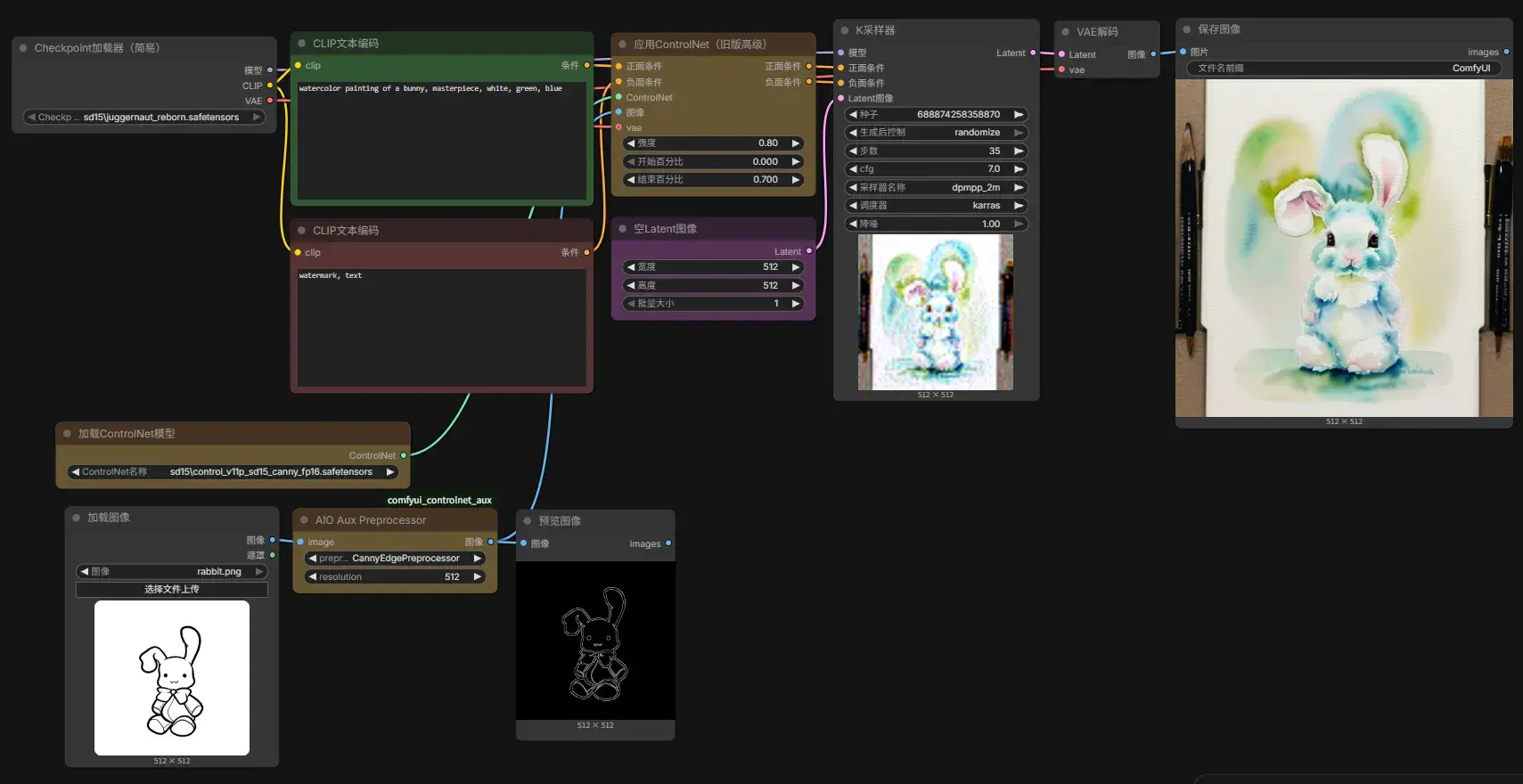
提示
在早期的 ComfyUI 中,如果你想使用不同的 ControlNet,需要分别使用不同的节点(Canny Edge、OpenPose Estimator、Depth Estimator 等)。后来,ComfyUI 的 comfyui_controlnet_aux 插件提供了 AIO Aux Preprocessor,把这些节点全部整合到了一起。
| ControlNet 模型 | 控制类型 | 推荐预处理器(AIO Aux Preprocessor 中) | 输入 | 输出 |
|---|---|---|---|---|
control_v11f1p_sd15_depth_fp16.safetensors | 深度(Depth) | Depth (MiDaS)(首选)、Depth (ZoE)、Depth (LeReS) | 普通图片 | 深度图(灰度) |
control_v11p_sd15_canny_fp16.safetensors | 边缘(Canny) | Canny | 普通图片 | Canny 边缘图 |
control_v11p_sd15_openpose_fp16.safetensors | 人体姿态(Pose) | OpenPose、OpenPose Full、DWPose(推荐) | 人物图片 | 骨架图(关键点) |
更换 ControlNet 模型为 control_v11f1p_sd15_depth_fp16.safetensors,改为使用 DepthAnythingPreprocessor(这会请求下载额外的模型,遇到网络问题了,西八),先 pending。
Apply ControlNet 节点参数:
| 参数 | 含义 | 取值范围 | 数值越大意味着 | 常见推荐值 |
|---|---|---|---|---|
| Strength | ControlNet 对生成结果的影响强度 | 一般 0~2(可更高) | 对控制图的遵循越严格,Prompt 的影响相对减弱 | 0.6~1.0(OpenPose 常用 0.8~1.2) |
| Start Percent | ControlNet 从采样过程的哪个百分比开始生效 | 0.0~1.0 | 越晚开始介入,前期越让模型自由生成 | 通常 0.0 |
| End Percent | ControlNet 在采样过程的哪个百分比停止生效 | 0.0~1.0 | 越晚停止,对整个生成过程影响越久 | 0.7~1.0(OpenPose 常用 1.0) |
使用 ControlNet 非预期的常见原因:

第 15 章 – 检查点、AIO 模型与 Z-Image 工作流
扩散模型也有不同的类别,它们并不改变模型已有的知识,而是知识的调度不同:
提示
| 名称 | 属于什么 | 含义 | 是否影响画质 | 是否节省显存 |
|---|---|---|---|---|
| AIO | 节点/模型封装 | All-In-One,将多个功能整合到一个节点或模型 | ❌ | ❌ |
| FP32 | 权重精度 | 32 位浮点 | 最高 | ❌(最大) |
| FP16 | 权重精度 | 16 位浮点,目前最常见 | 几乎无损 | ✅ |
| BF16 | 权重精度 | Brain Float16,新 GPU 常用 | 几乎无损 | ✅ |
| FP8 | 权重精度 | 8 位浮点 | 略有损失 | ✅✅ |
| GGUF | 模型格式 | llama.cpp 使用的统一模型格式,可包含量化 | 视量化等级而定 | ✅✅✅ |
| INT8 / INT4 | 量化方式 | 整数精度量化 | 有一定损失 | ✅✅✅ |
打开 5a Z-Image Turbo Fp8 AIO txt2img.json,加载比先前更大的模型 z-image-turbo-fp8-aio.safetensors (z-image-turbo-fp8-aio.safetensors · SeeSee21/Z-Image-Turbo-AIO at main,9.6 GB)和 z_image_turbo_bf16.safetensors(split_files/diffusion_models/z_image_turbo_bf16.safetensors · Comfy-Org/z_image_turbo at main,11.5 GB)至 Comfy-Desktop/ComfyUI-Installs/ComfyUI/models/checkpoints/z-image。
提示
| 功能 | 前一个(SD1.5) | 当前(Z-Image Turbo) | 原因 |
|---|---|---|---|
| 模型 | Juggernaut Reborn(SD1.5) | Z-Image Turbo AIO | 底层模型完全不同 |
| Positive Prompt | 一个 CLIPTextEncode | 一个 CLIPTextEncode | 相同 |
| Negative Prompt | 单独一个 CLIPTextEncode | 没有单独 Negative Prompt | Turbo 模型不需要传统 Negative Prompt |
| Latent | EmptyLatentImage | EmptySD3LatentImage | SD3/AuraFlow 专用 Latent |
| Sampling | KSampler | KSampler | 相同 |
| Decode | VAEDecode | VAEDecode | 相同 |
| Save | SaveImage | SaveImage | 相同 |
| 新增节点 | 无 | ModelSamplingAuraFlow | AuraFlow 专用采样配置 |
| 新增节点 | 无 | ConditioningZeroOut | 构造空 Negative Conditioning |
可以借助 LLM 获得更好的 CLIP 提示词。
z-image-turbo-fp8-aio.safetensors 这个模型生成的图像不受 512 x 512 大小的限制,细节也更多。
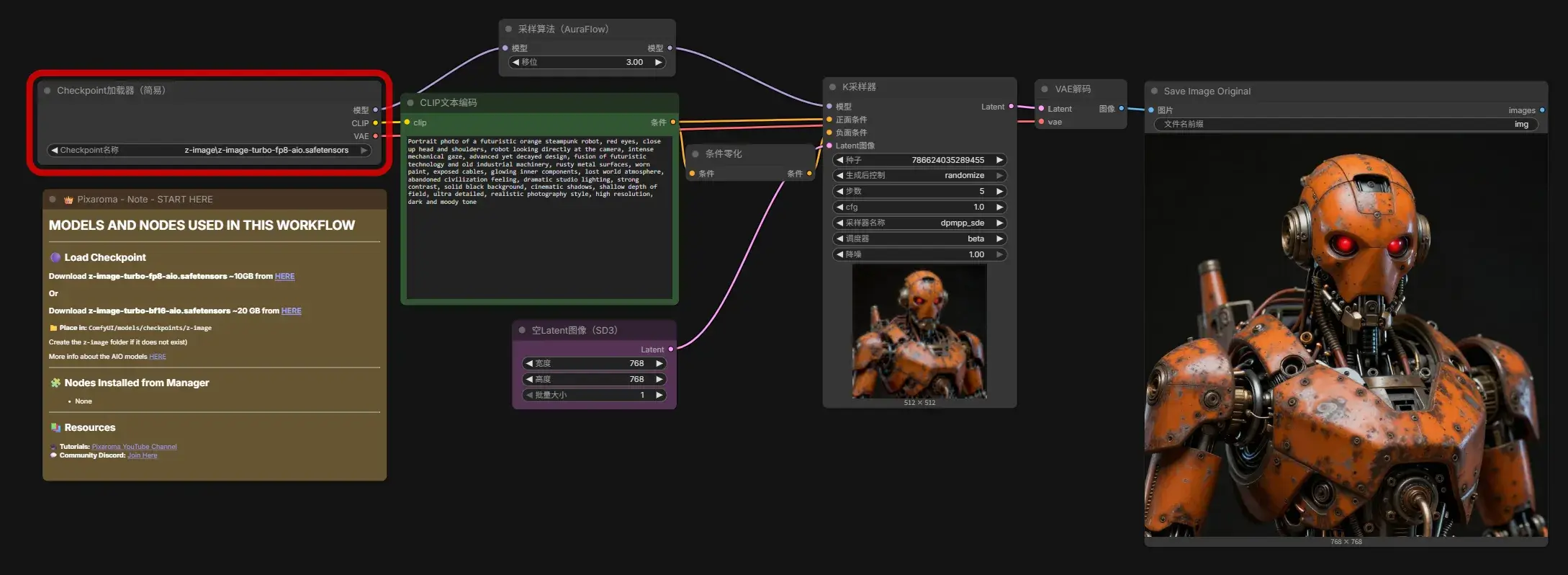
第 16 章 – 使用扩散模型(FP8 或 FP16)
之前的模型是 AIO 模型,它将 UNet(扩散模型),CLIP 和 VAE 都集成在了一个文件中,方便开箱即用但是不灵活。
提示
| 医学分割 UNet | 扩散模型 UNet | |
|---|---|---|
| 输入 | 图片 | 带噪声的 Latent(或 Pixel)+ 时间步 + 文本条件 |
| 输出 | 每个像素属于哪个类别 | 每个位置的噪声预测值 |
| 损失函数 | Segmentation Loss | Noise Prediction Loss |
| 用途 | 图像分割 | 图像生成 |
打开 5b Z-Image Turbo Fp8 txt2img.json,继续下载模型到相应位置……
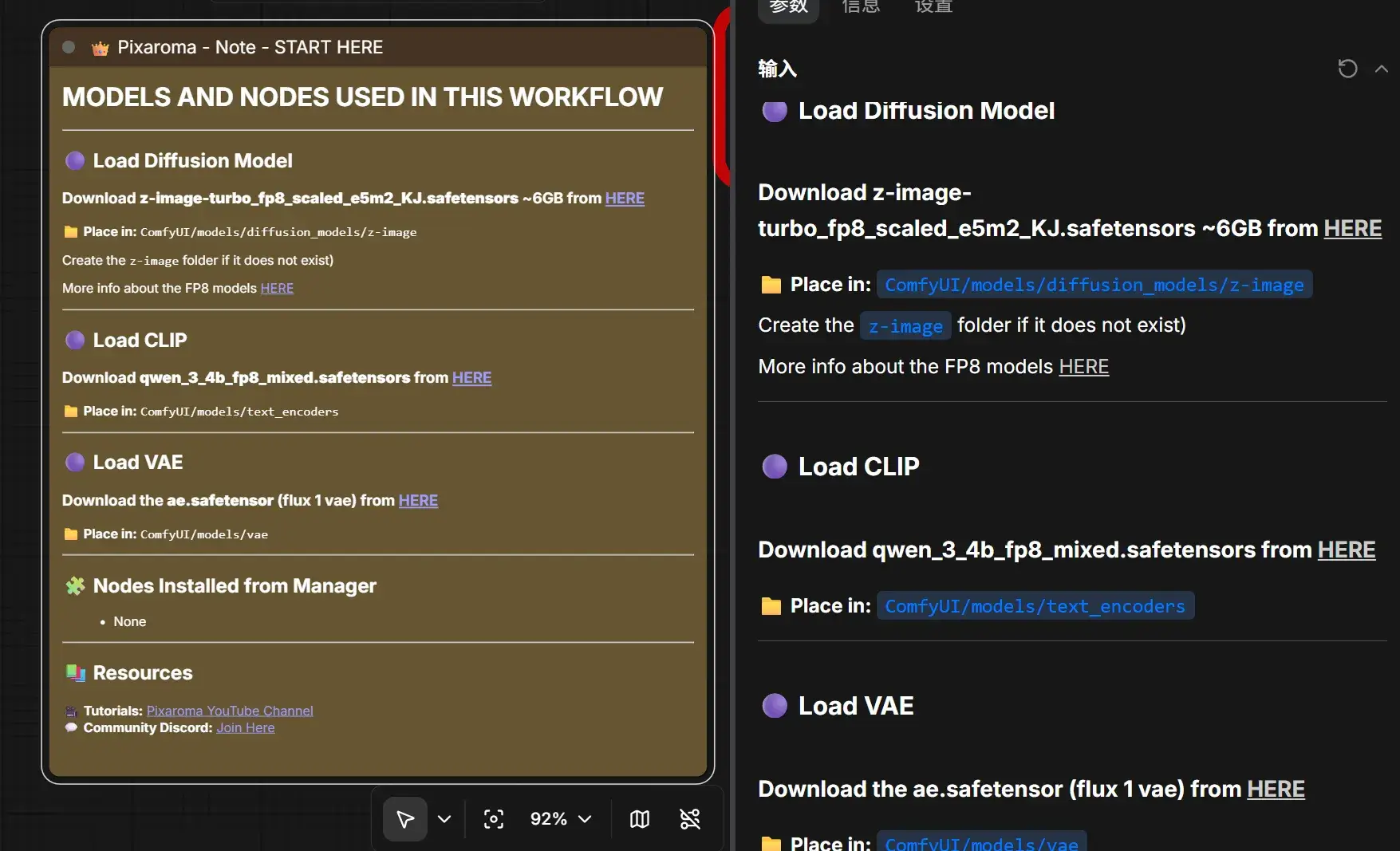
提示
| 文件名 | 大小 | 下载地址 | 拆解 | 含义 |
|---|---|---|---|---|
z-image-turbo_fp8_scaled_e5m2_KJ.safetensors | 6.16 GB | Kijai/Z-Image_comfy_fp8_scaled at main | z-image + turbo + fp8 + scaled + e5m2 + KJ | Z-Image Turbo 扩散模型,FP8 精度,经过缩放(scaled),采用 E5M2 FP8 格式,由 Kijai 转换 |
qwen_3_4b_fp8_mixed.safetensors | 5.63 GB | Comfy-Org/z_image_turbo at main | qwen + 3 + 4b + fp8 + mixed | Qwen3 4B 文本编码器,FP8 混合精度版本 |
ae.safetensors | 335 MB | Comfy-Org/z_image_turbo at main | ae | AutoEncoder(VAE)模型 |
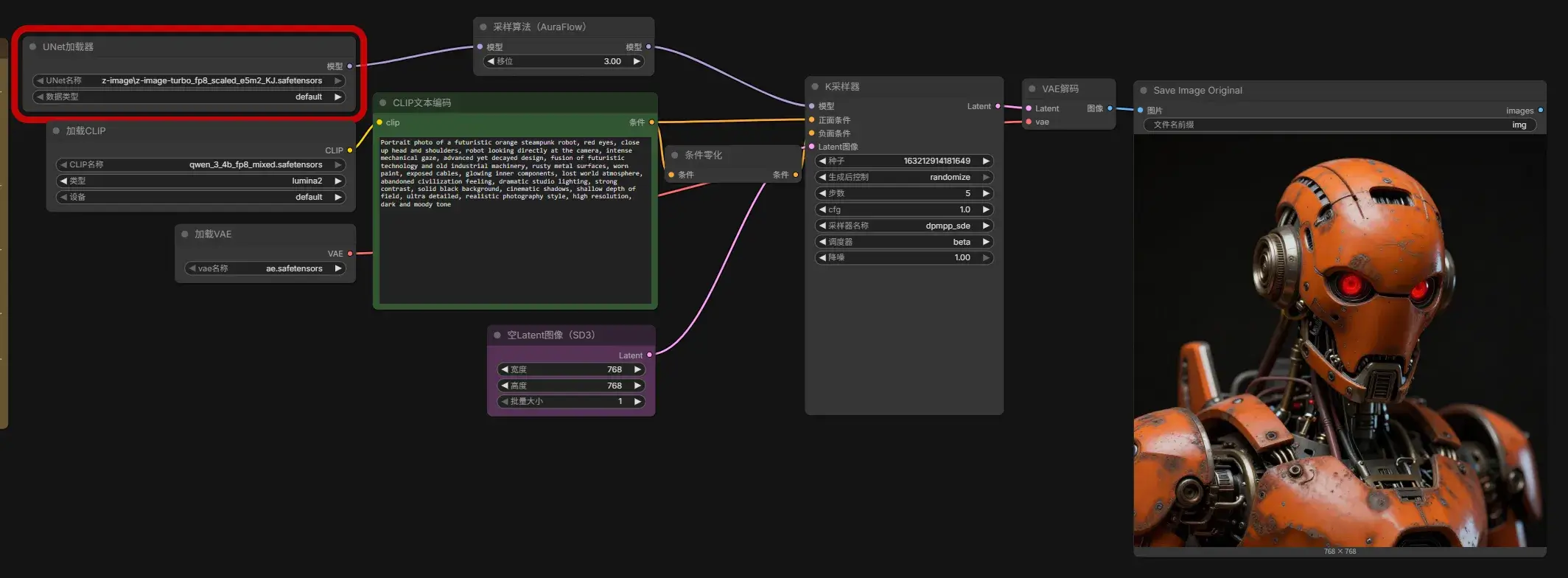
可以根据当前电脑的配置找到最适合自己电脑的模型。
第 17 章 – 使用 GGUF 模型
提示
可以把 GGUF 理解成:一种把 AI 模型压缩并打包后的文件格式,目的是减少显存占用、提高本地运行效率。
打开 5c Z-Image Turbo GGUF txt2img.json,继续下载模型……
提示
| 文件名 | 大小 | 下载地址 | 拆解 | 含义 |
|---|---|---|---|---|
z-image-turbo-q4_k_s.gguf | 4.34 GB | https://huggingface.co/gguf-org/z-image-gguf/tree/main | z-image + turbo + q4_k_s + gguf | Z-Image Turbo 扩散模型,采用 GGUF 格式,Q4_K_S 四位 K-Quant 量化版本。 |
qwen-4b-zimage-heretic-q8.gguf | 4.28 GB | https://huggingface.co/Lockout/qwen3-4b-heretic-zimage/tree/main | qwen + 4b + zimage + heretic + q8 + gguf | 基于 Qwen3 4B 的 Z-Image 文本编码器,针对 Z-Image 工作流进行了 Heretic 社区适配,采用 GGUF 格式和 Q8(8-bit) 量化。 |
ae.safetensors | 335 MB | https://huggingface.co/Comfy-Org/z_image_turbo/tree/main/split_files/vae | ae | AutoEncoder(VAE)模型,负责图像空间(Pixel Space)与潜空间(Latent Space)之间的编码与解码,Z-Image 与 FLUX.1 共用该 AE。(上一节已安装) |
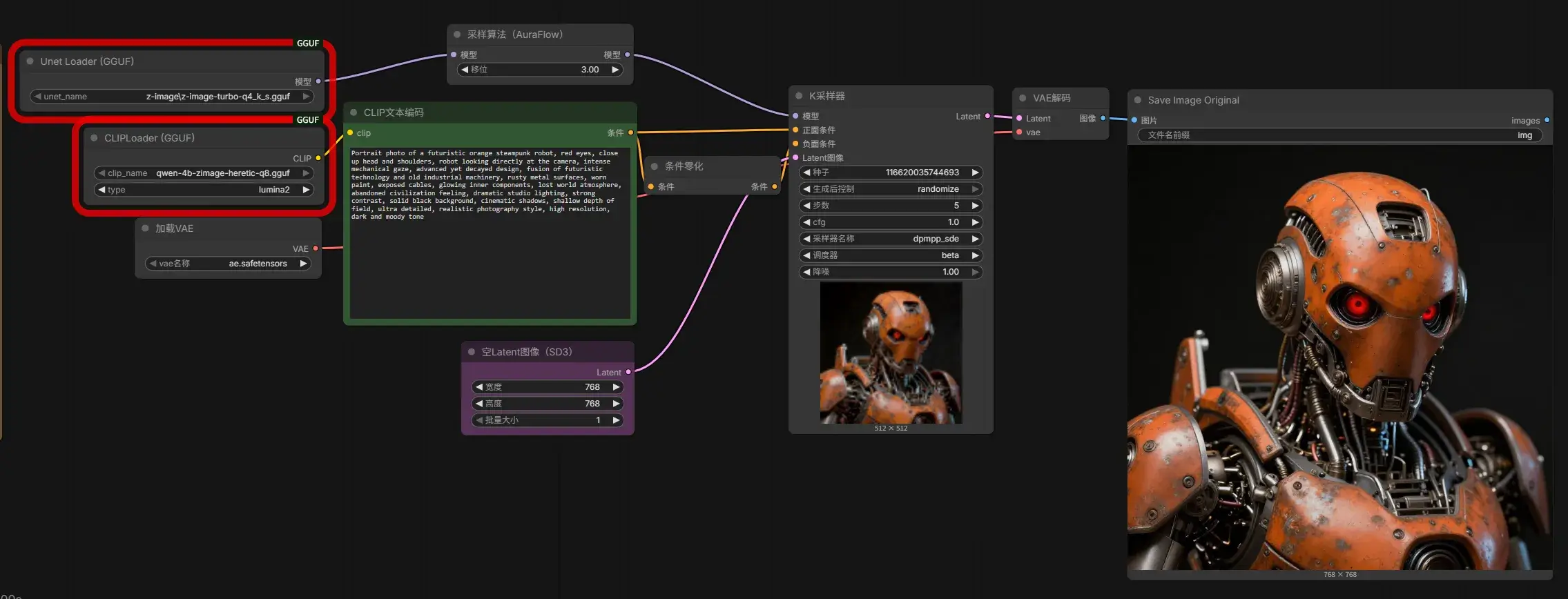
第 18 章 – 批量生成、风格与多重提示词
要一次性生成多张图片,可以改批量大小:
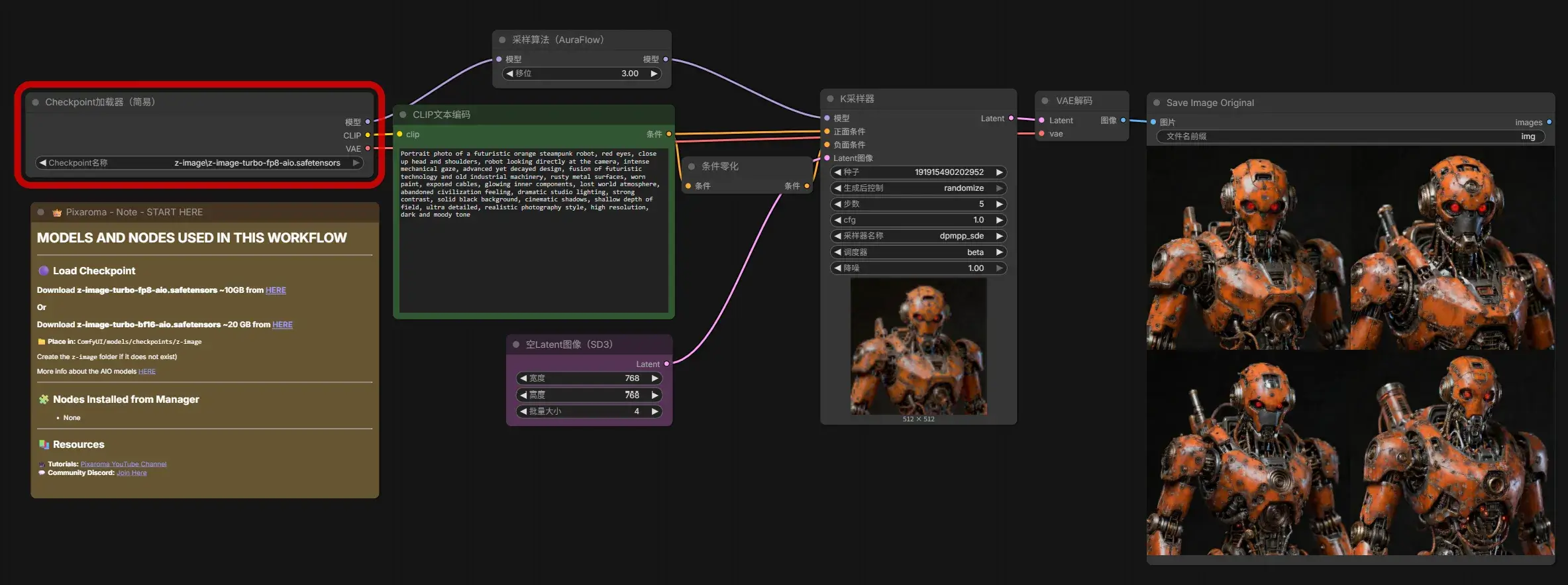
下载插件 comfyui-itools,解锁 iTools Line Loader 节点,替换掉 CLIP 原生节点中的提示词输入。
提示
iTools Line Loader 节点从一段多行文本中,根据指定的索引(Seed)取出其中的一行。
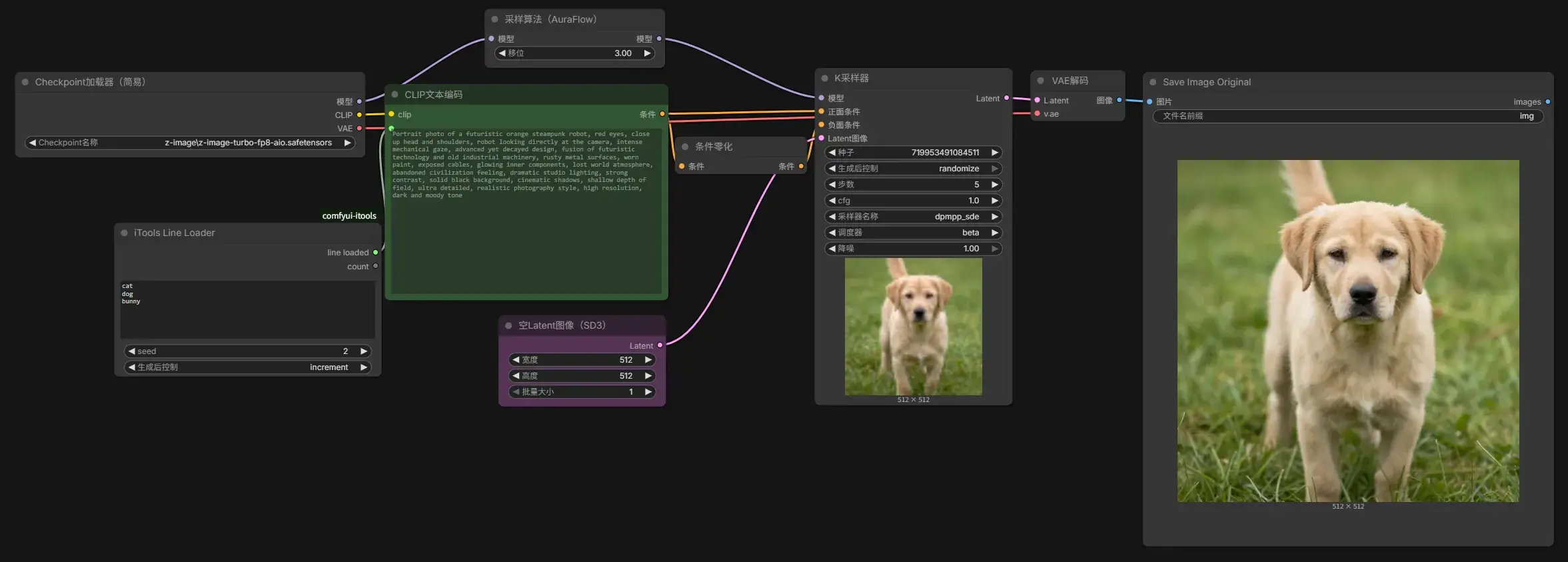
可以用 iTools Prompt Loader 节点将提示词来源指向至外部的文本文件。
可以用 iTools Prompt Styler 节点加载插件中预设的风格提示词(XXX.yaml),这样提示词的描写就只要集中于事物上了(这个不错,我喜欢)。
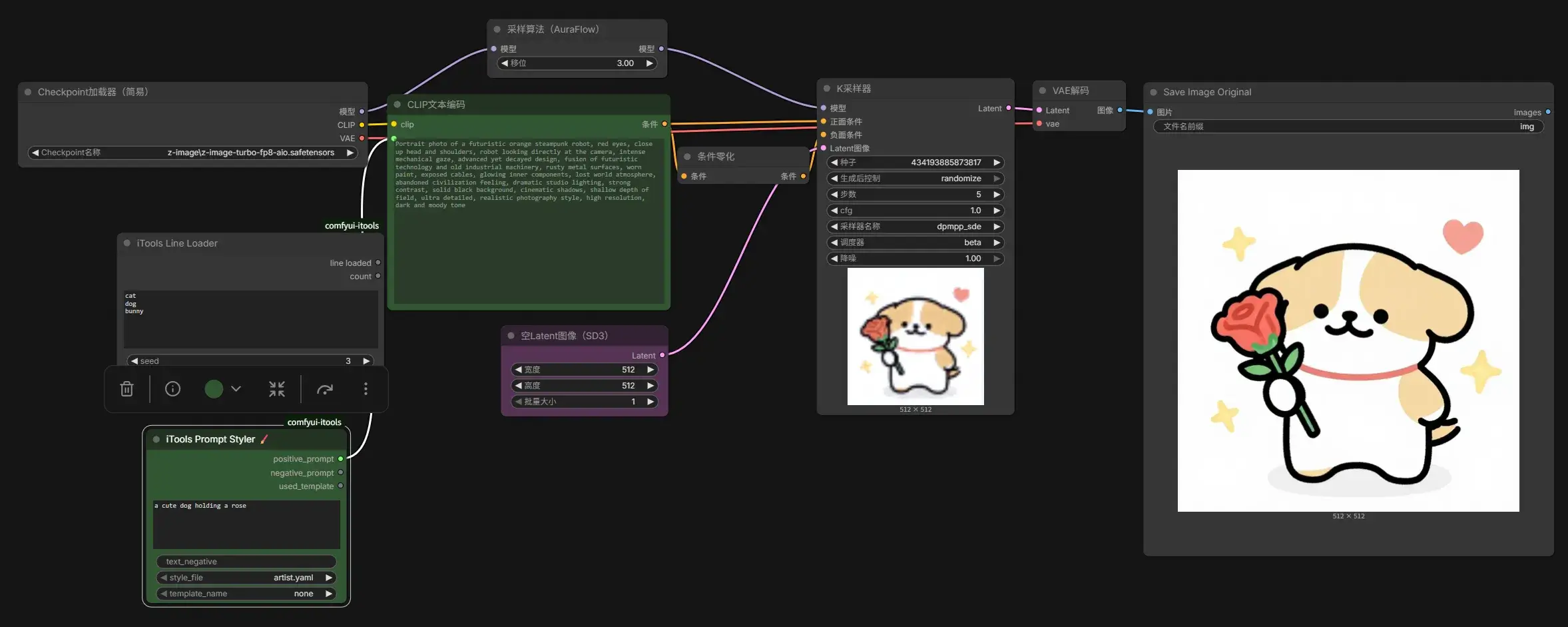
可以用 iTools Prompt Styler Extra 实现多重风格提示词(画出线条小狗了可还行):
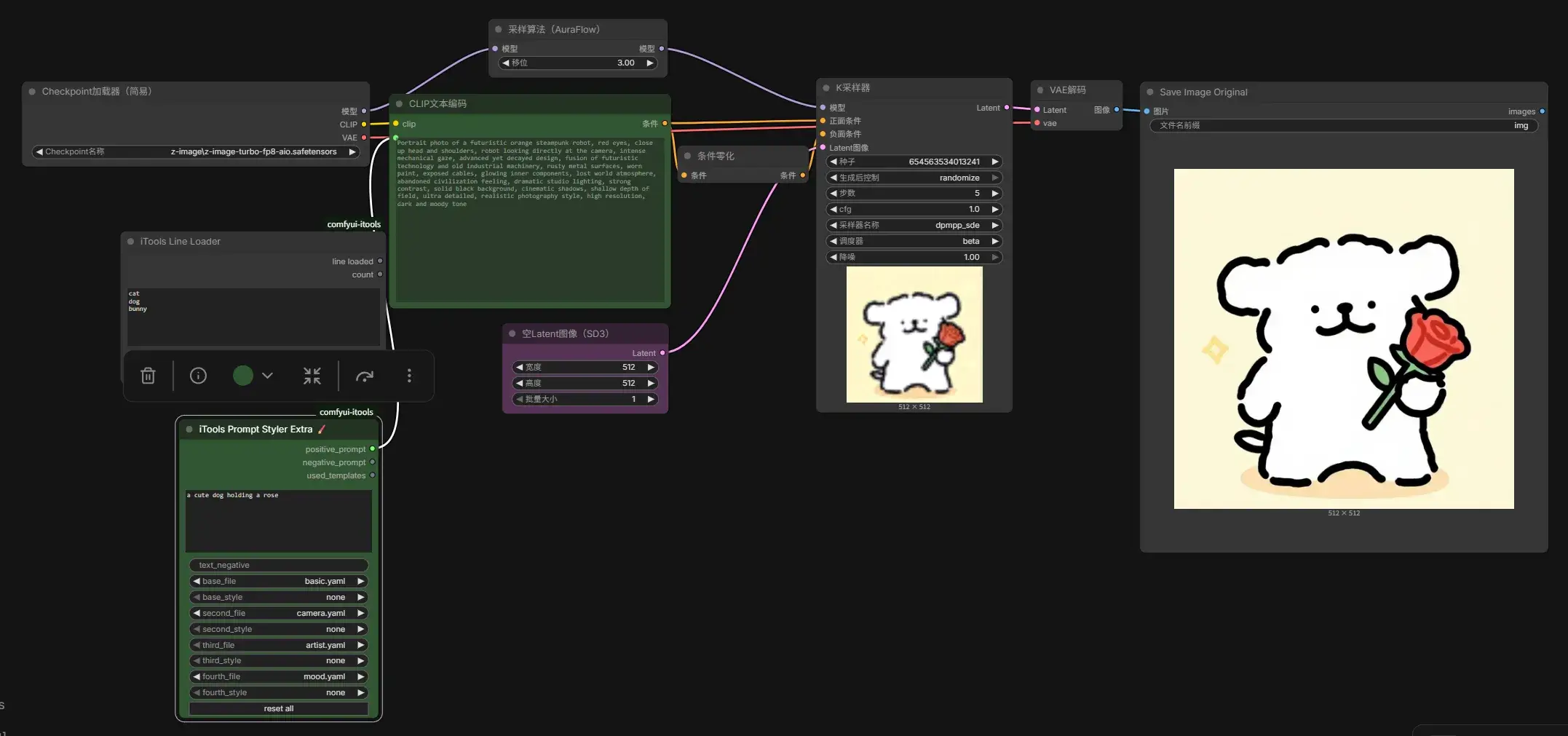
第 19 章 – 在 Z-Image Turbo 中使用 LoRAs
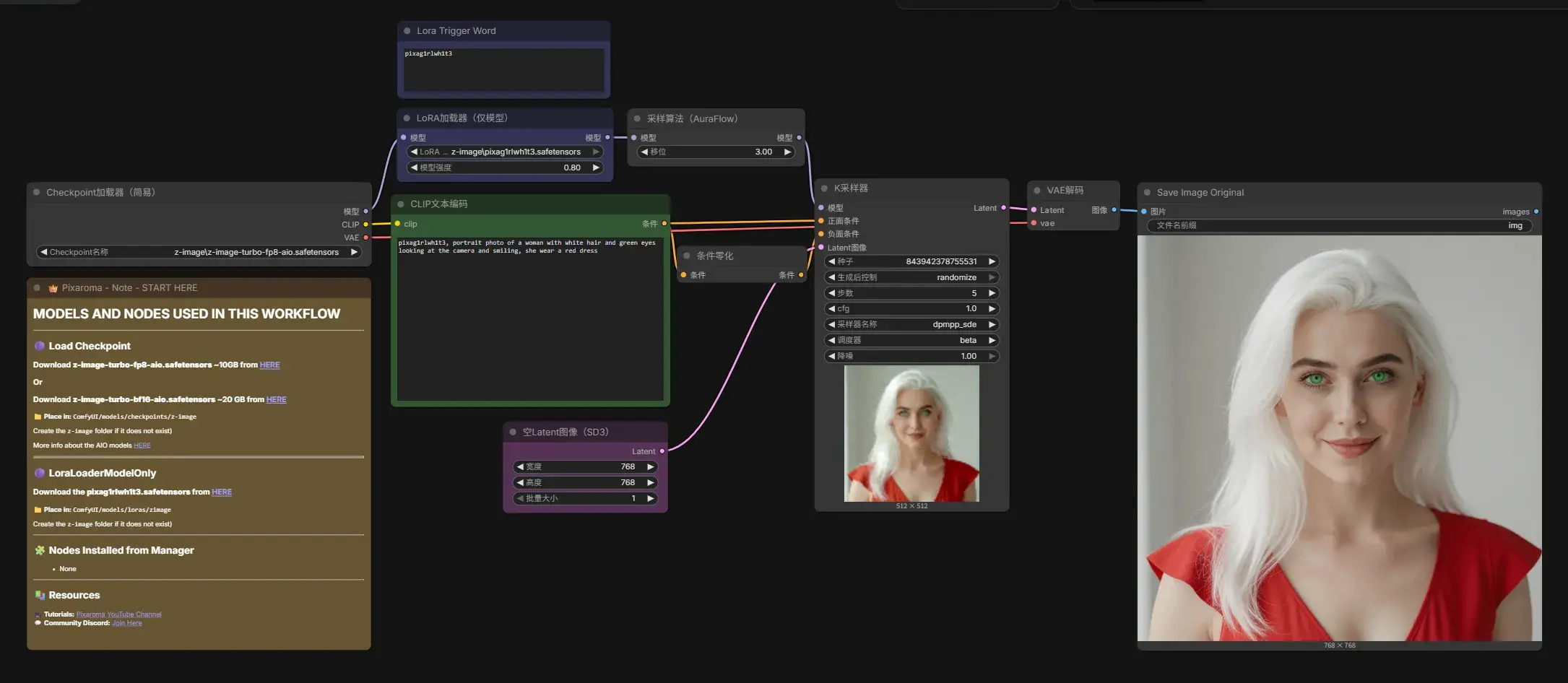
打开 6 Z-Image Turbo Fp8 AIO txt2img + Lora.json,继续下载 pixag1rlwh1t3.safetensors(Pixaroma/experimental_loras at main,83 MB)……让模型理解提示词 pixag1rlwh1t3。
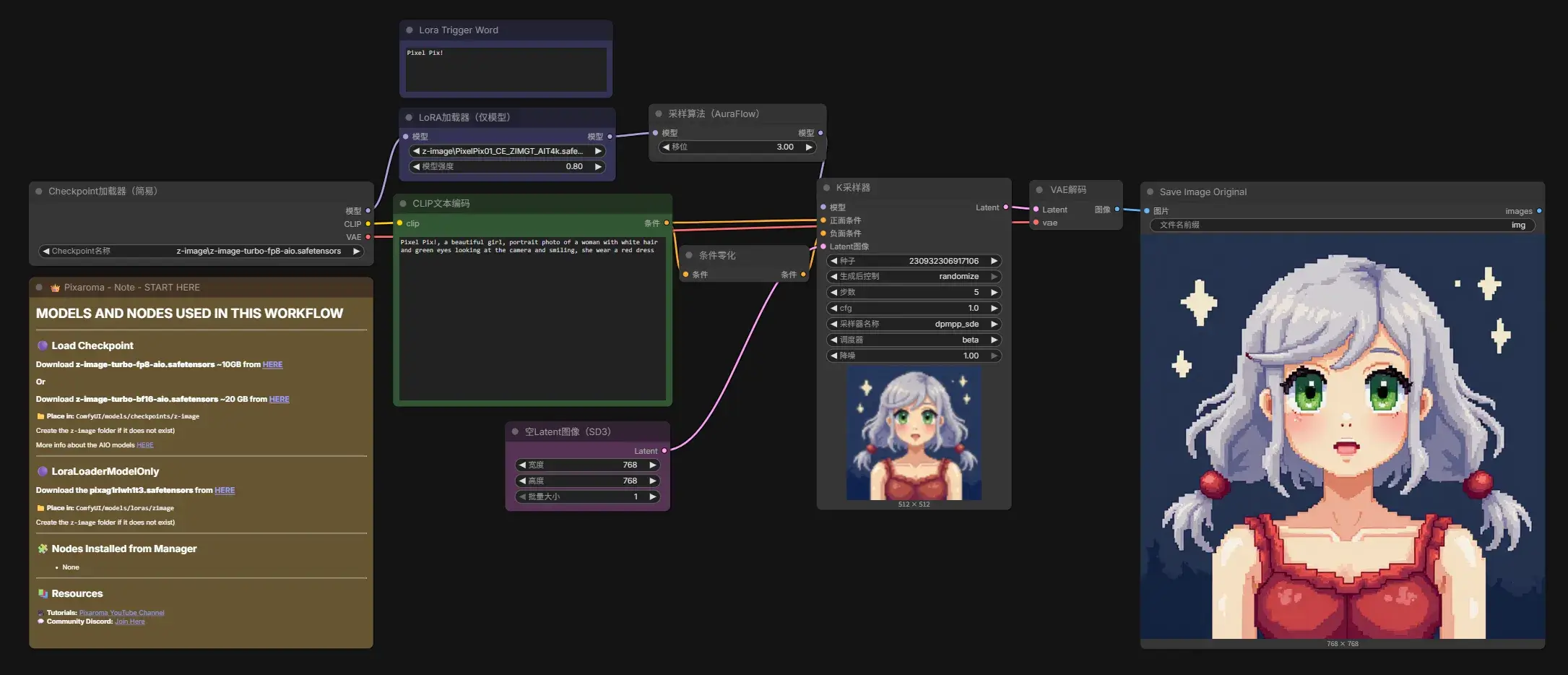
变身美爷,进入 AI Models | Civitai 查找更多 LoRA!找一个 Pixel Pix! - CE - V01a - Z-Image Turbo | ZImage LoRA | Civitai,确定模型类型匹配(ZmageTurbo),得到 PixelPix01_CE_ZIMGT_AIT4k.safetensors 让模型理解提示词 Pixel Pix!。
将 LoRA 对应的提示词用 Note 节点在旁边提示是一个好习惯。
第 20 章 – 在 Z-Image Turbo 中使用 ControlNet
打开 7 Z-Image Turbo Fp8 AIO txt2img + ControlNet.json,继续下载 Z-Image-Turbo-Fun-Controlnet-Union.safetensors(alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union at main,2.9 GB)……
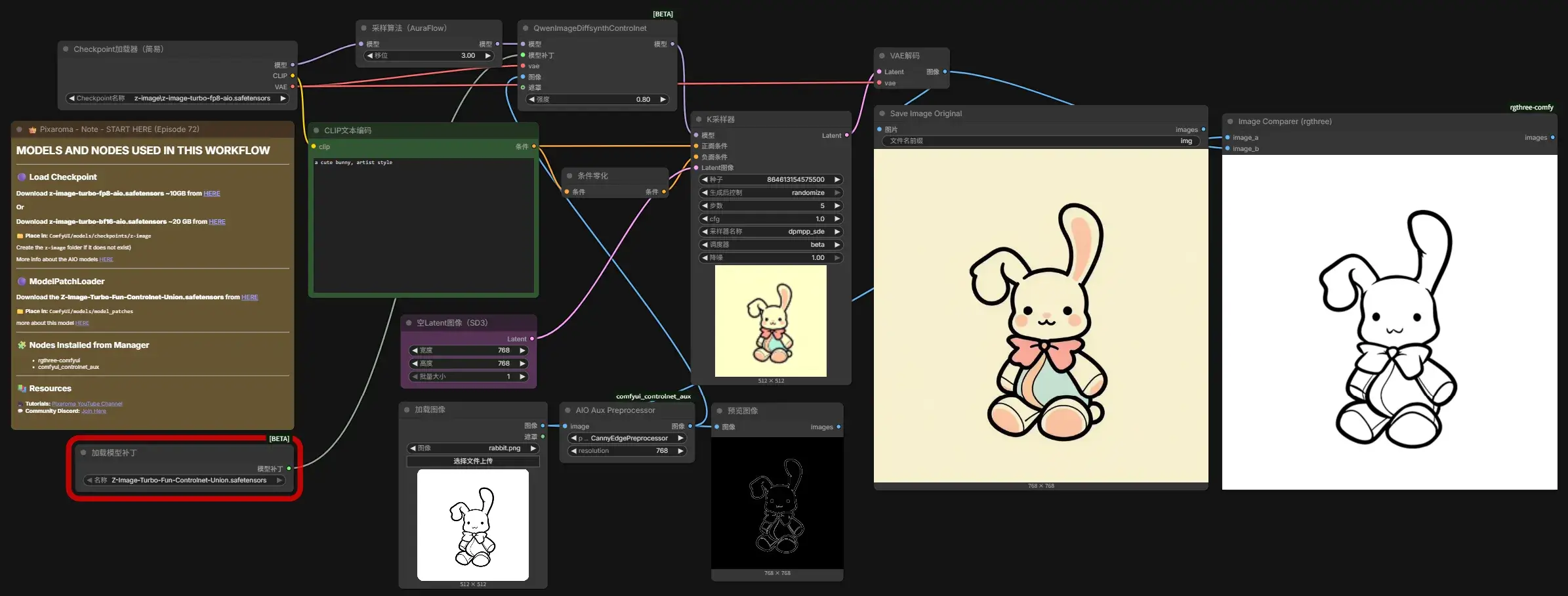
再来一张,但是没有达到想要的直接给场景迁移成雪景的效果……
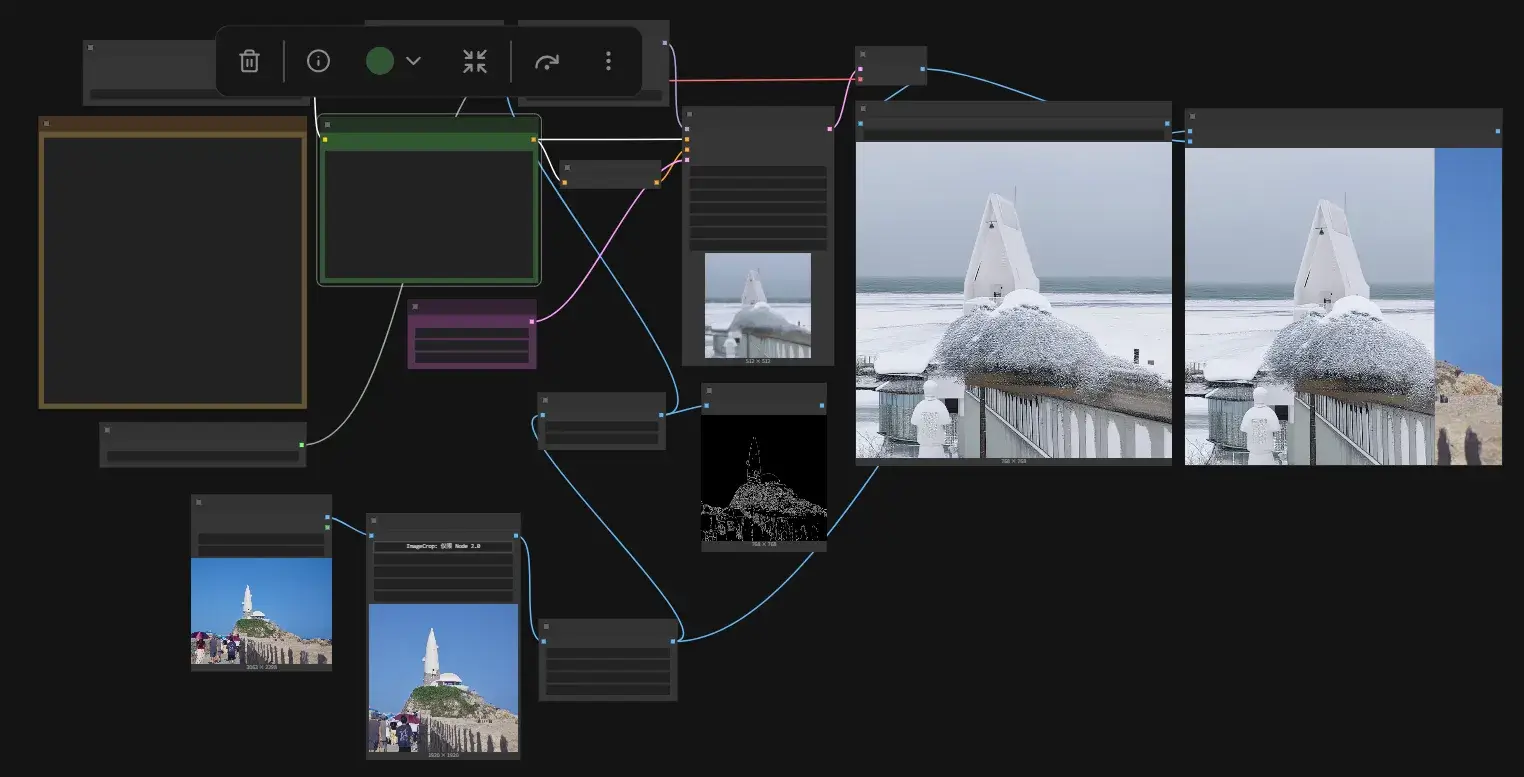
第 21 章 – API 节点
ComfyUI 也有个中转站,可以爆金币让绘图/创建提示词等调用模型的流程在云端上进行。
还能用支付宝/微信送钱,不够要求填写所在地址,不知道会不会因此让有些模型即使充了钱也不能访问到?
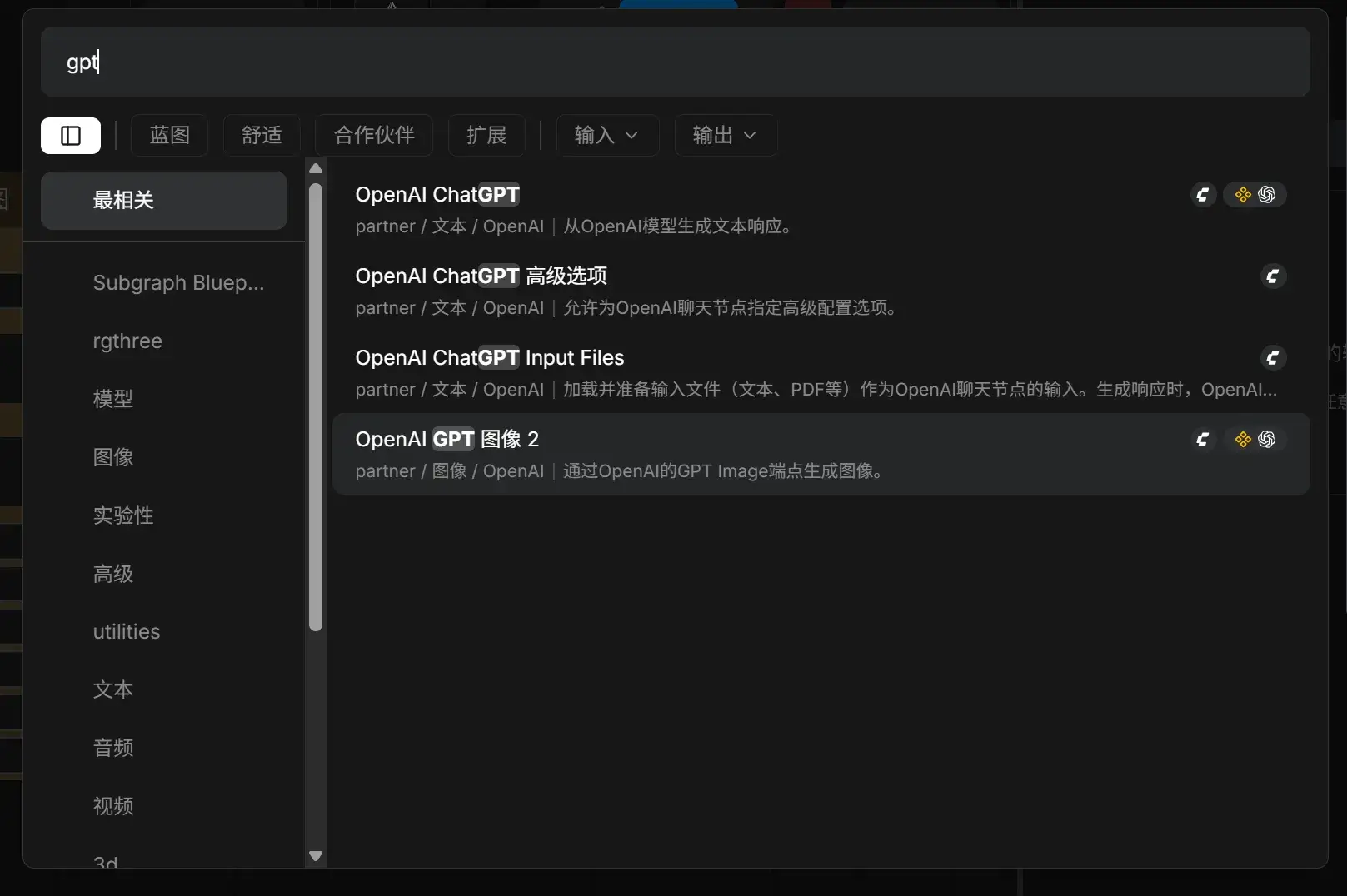
好吧,确实能跑 GPT-Image-2,不过价格不便宜,¥5 (1055 积分)跑不了几张:
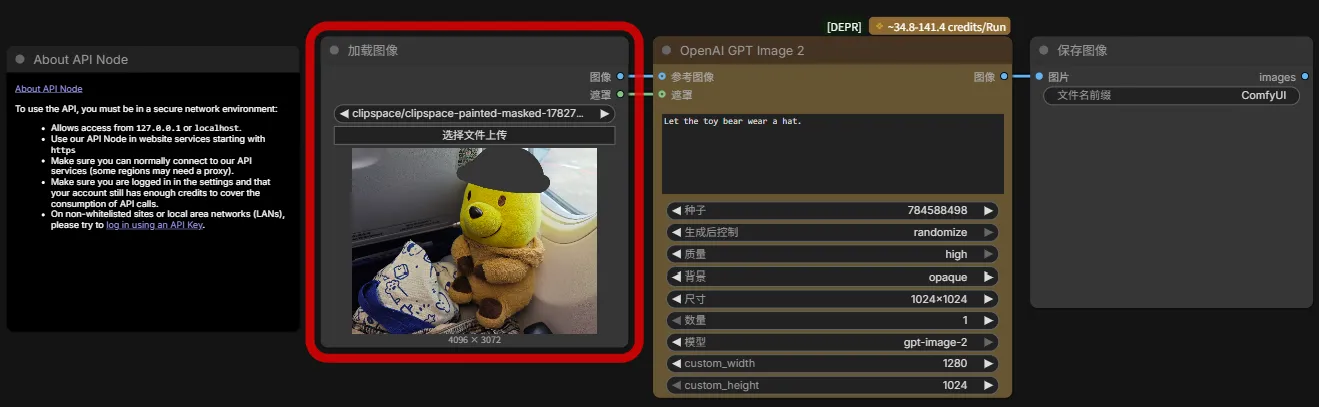

自行探索
安装 ComfyUI Skill
Hermes 内嵌了 ComfyUI Skill:Comfyui | Hermes Agent,可在任意 Agent 上使用如下命令把这个 Skill 扒下来:
"去 github.com/NousResearch/hermes-agent 把 skills/creative/comfyui 这个文件夹拉到 ~/.codex/skills/comfyui-skill。装完重启 Codex 让它发现新 skill。然后激活,连本地 127.0.0.1:8188 跑 ping 确认。"
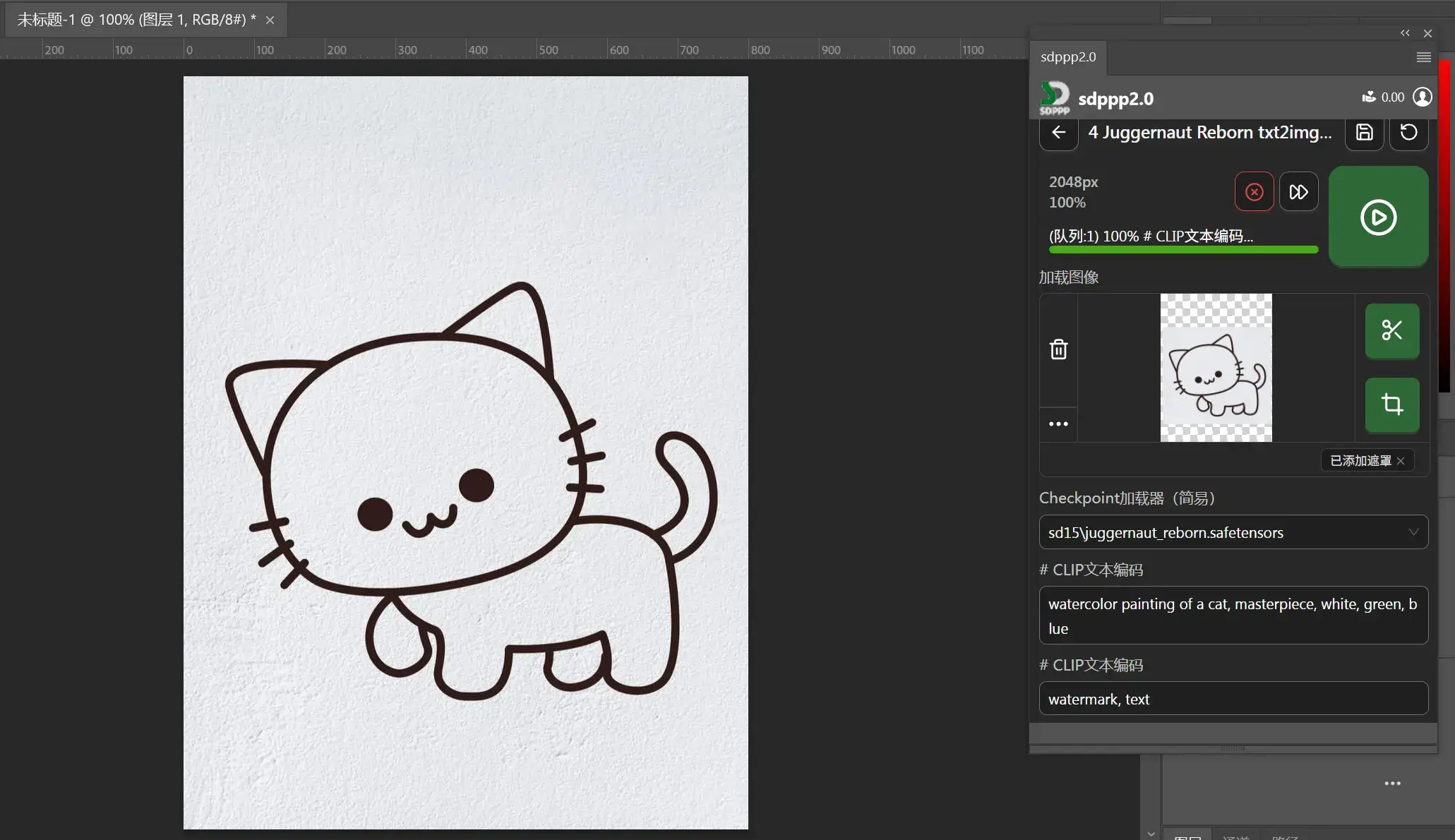
连接 ComfyUI 与 PS
按照 Photoshop 插件安装 | SD-PPP 的做法,下载 sd-ppp2_PS.zip 解压到 Adobe Photoshop 2025/Plug-ins 下:
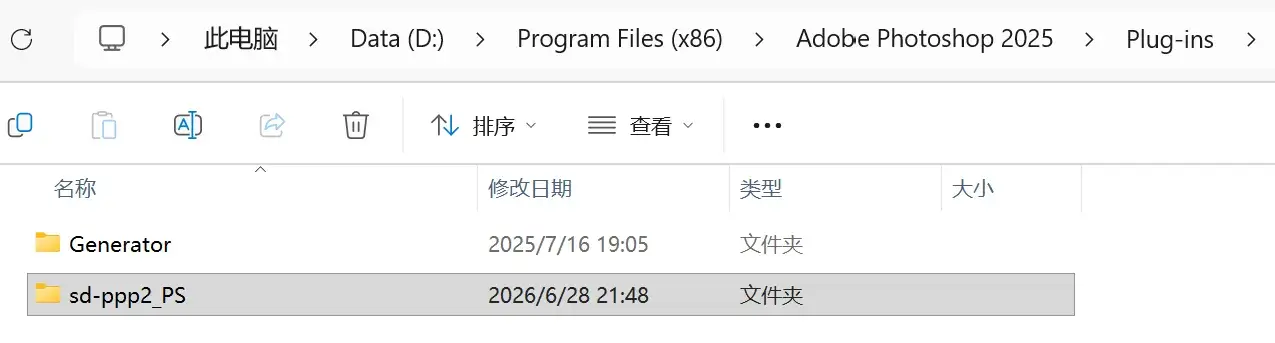
ComfyUI 侧安装 SD-PPP:
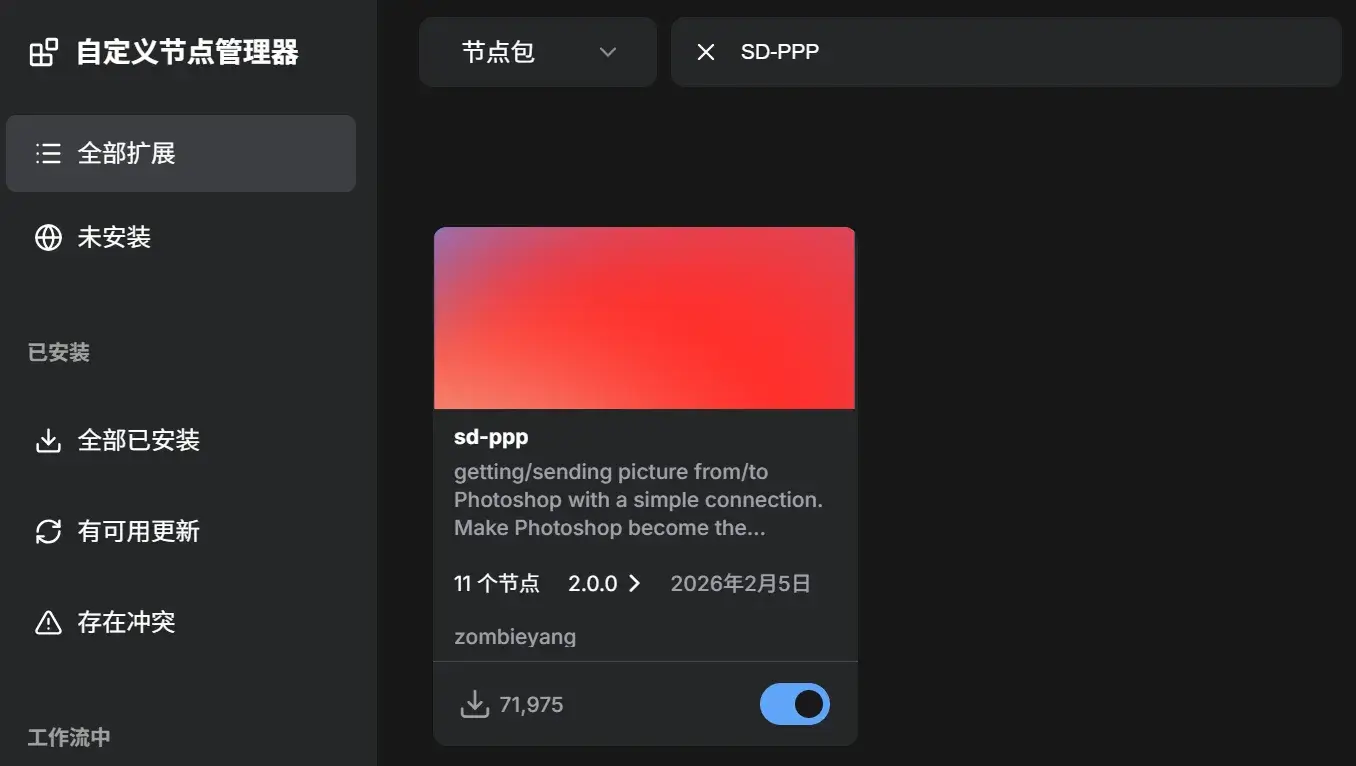
双边安装好后,PS 侧输入 ComfyUI 的地址 http://127.0.0.1:8188,即可看到目前 ComfyUI 的工作流:
参照 ComfyUI 节点命名规则 | SD-PPP,Load Image 节点自动传给 PS,如果想让 PS 给提示词,在节点名称前加上 # 符号。
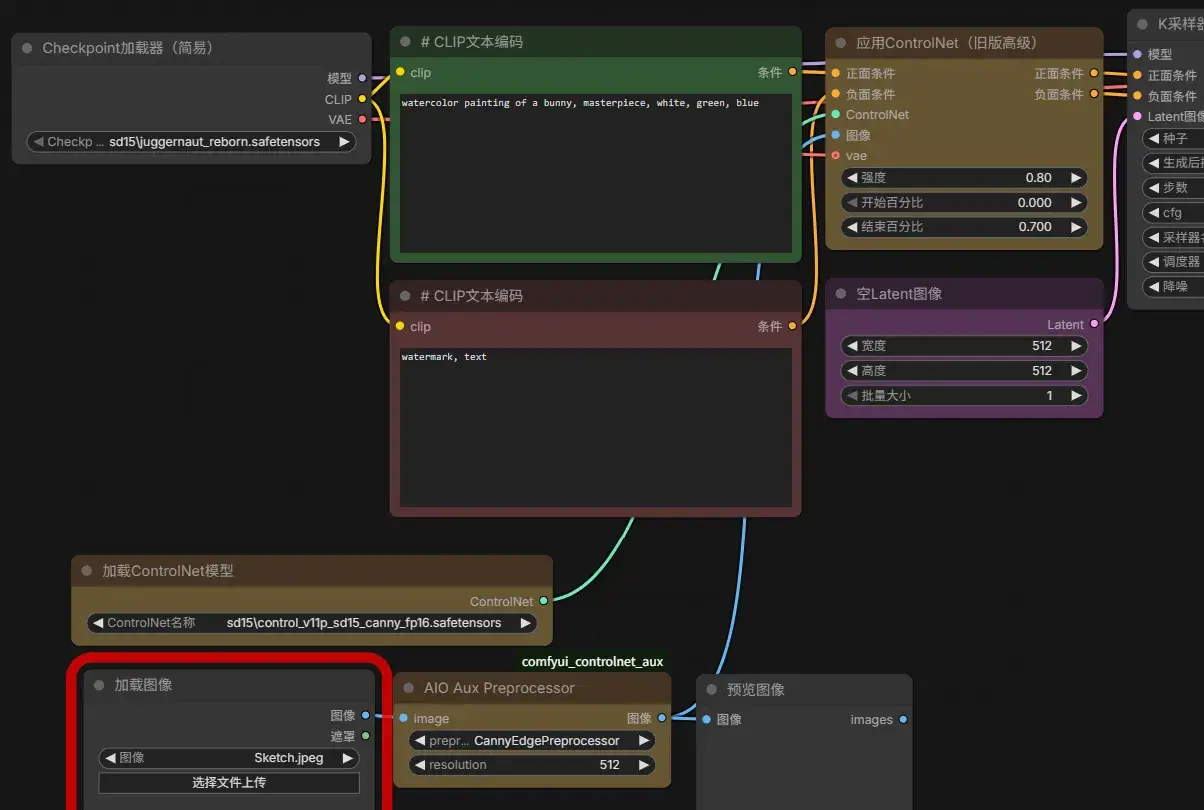
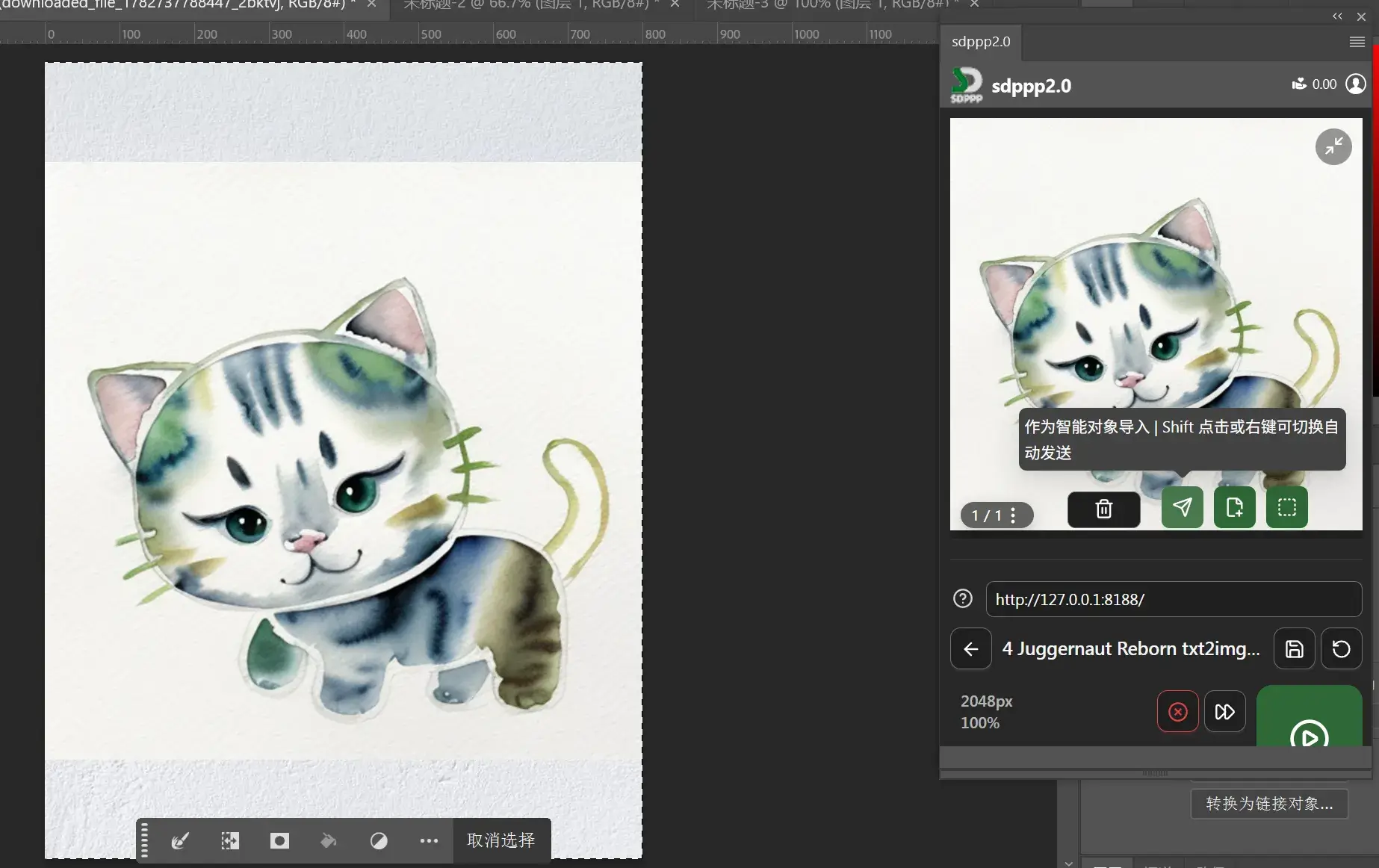
PS 传递好图片和提示词,开跑!
跑完后从 ComfyUI 中导出图像给 PS。
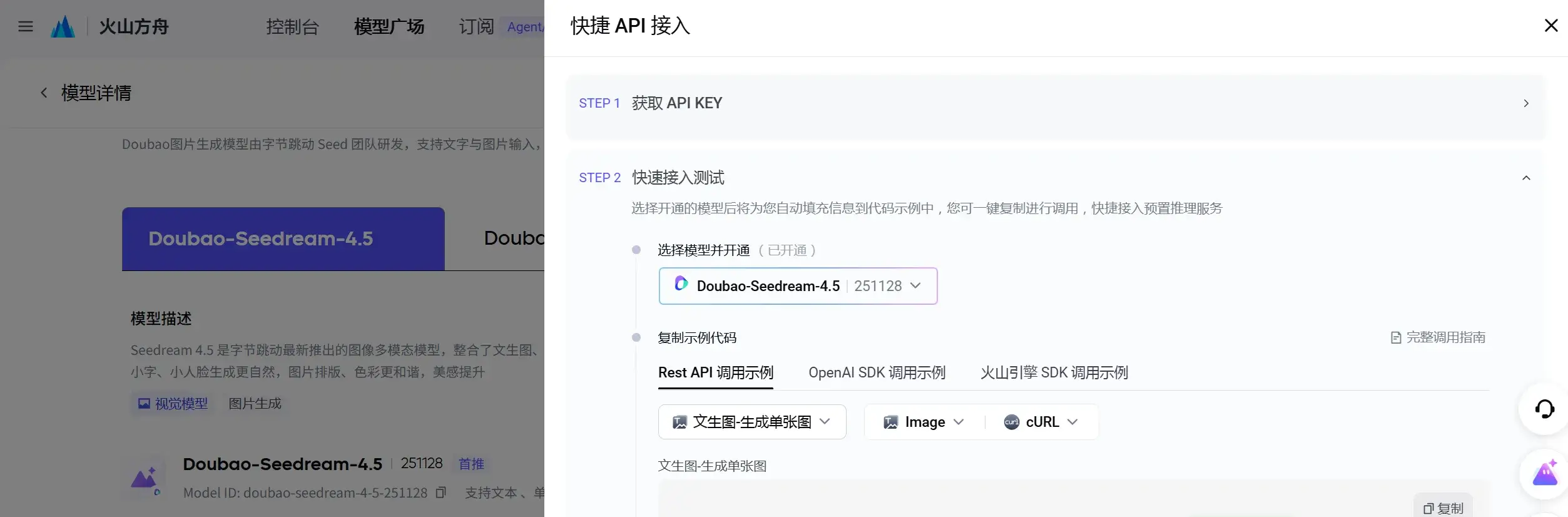
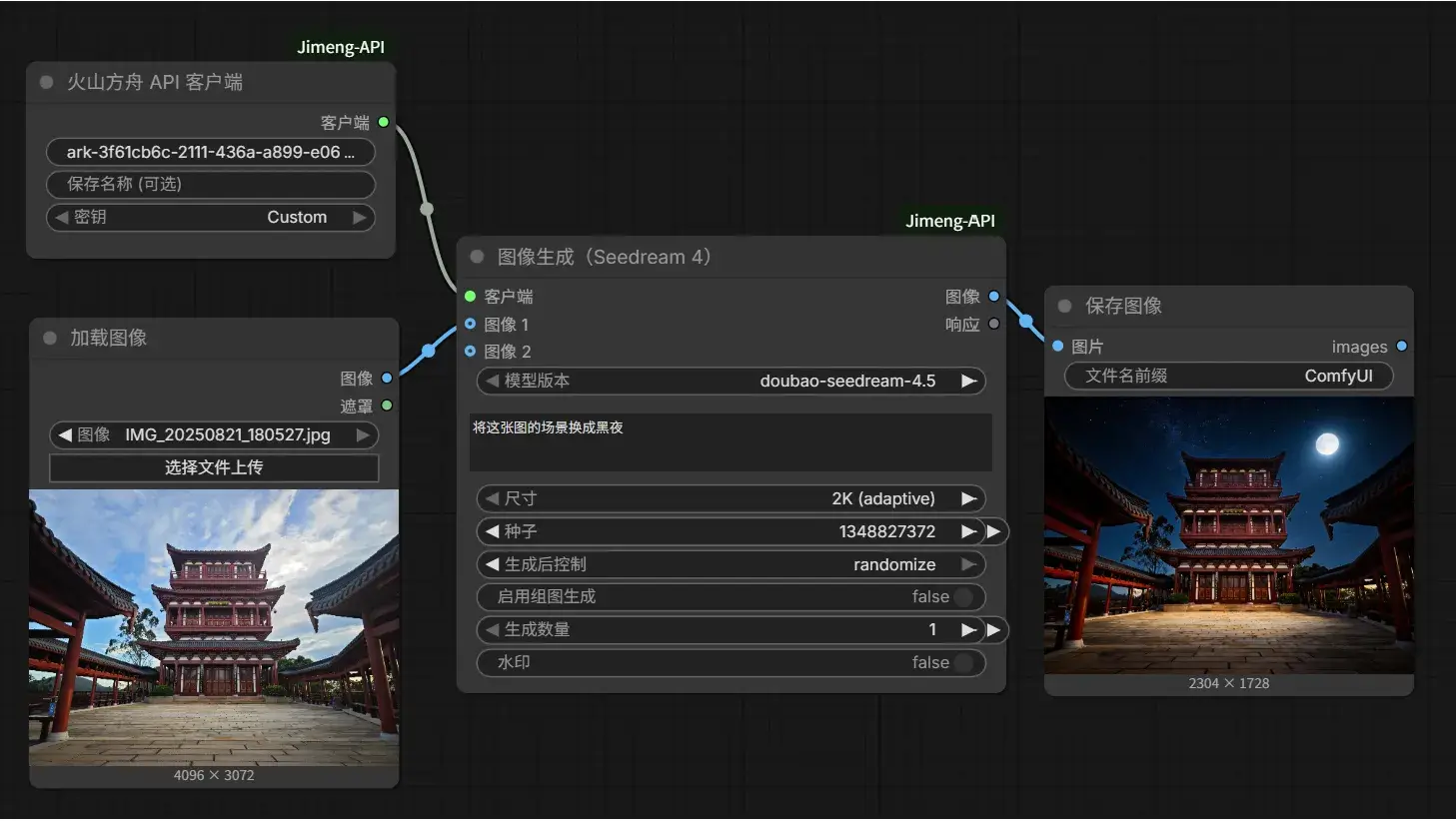
火山 API 调用
去 火山方舟 - 模型广场-模型详情 整一个 API Key。看起来有免费额度,真是太幸运了。
在客户端节点填上 API Key,简单搭一个工作流开跑,这个模型具体用法可见 Seedream 4.0-5.0 教程--火山方舟-火山引擎:
Qwen-Iamge-Edit
按照 Qwen-Image-Edit ComfyUI Native Workflow Example - ComfyUI 来,下好工作流和模型,然后开跑。
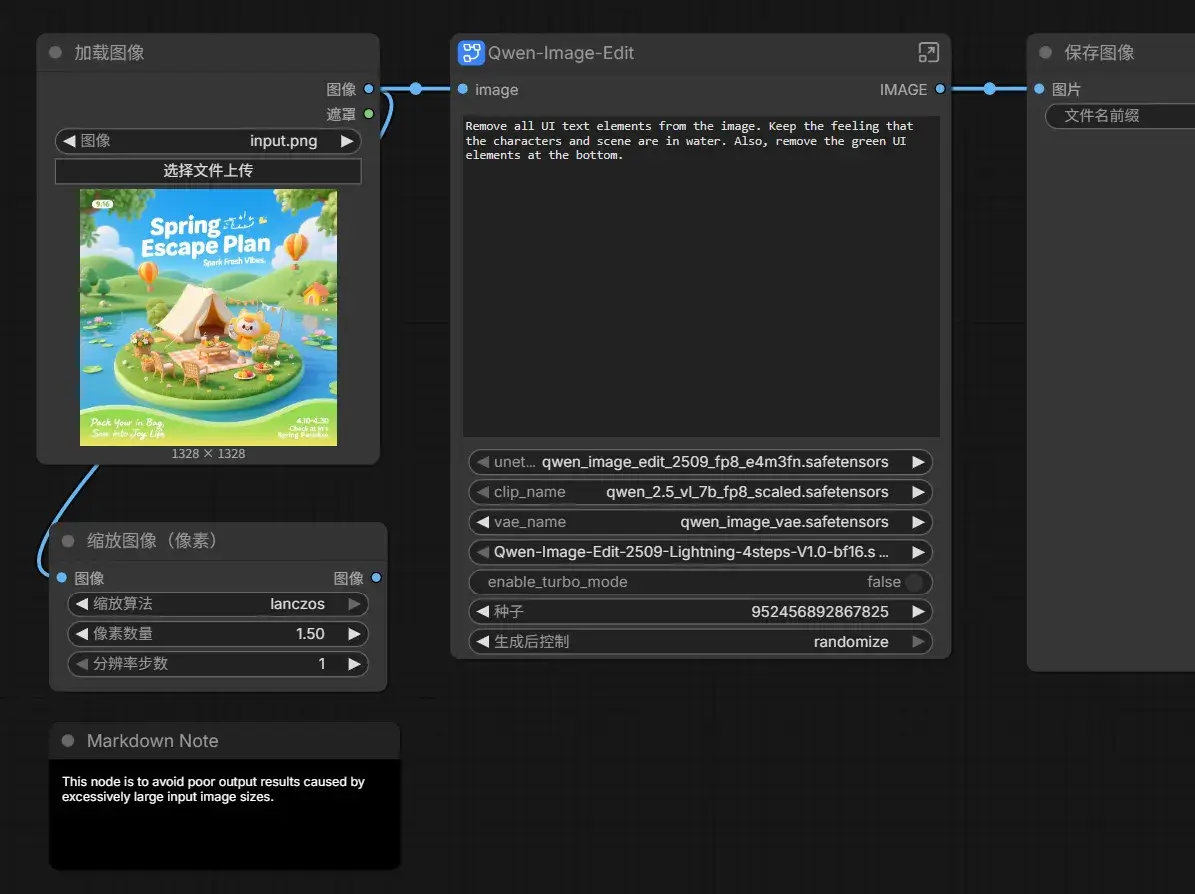
但是只能通过语言控制模型对图像进行重绘。
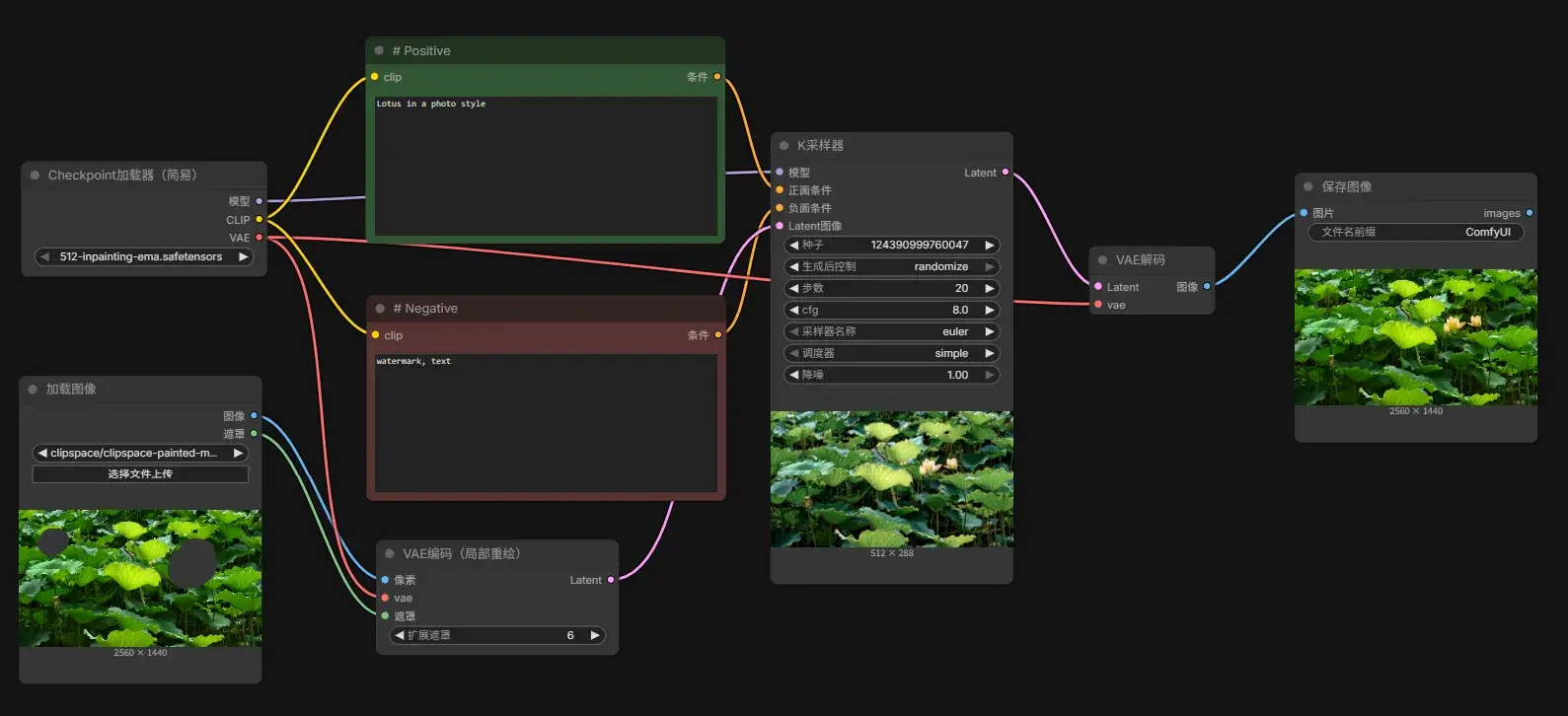
局部重绘
根据 ComfyUI_examples/inpaint at master · comfyanonymous/ComfyUI_examples 抄一个工作流。并下载模型 models/checkpoints/512-inpainting-ema.safetensors · Sean-Bradley/ComfyUI at main 512-inpainting-ema.safetensors
{
"id": "227b8873-8dc5-430d-b0ef-fd58e16667dc",
"revision": 0,
"last_node_id": 10,
"last_link_id": 16,
"nodes": [
{
"id": 1,
"type": "CheckpointLoaderSimple",
"pos": [
413.06602721927646,
-294.3242834773608
],
"size": [
273.4576171875,
98
],
"flags": {},
"order": 0,
"mode": 0,
"inputs": [],
"outputs": [
{
"name": "MODEL",
"type": "MODEL",
"links": [
5
]
},
{
"name": "CLIP",
"type": "CLIP",
"links": [
1,
2
]
},
{
"name": "VAE",
"type": "VAE",
"links": [
7,
13
]
}
],
"properties": {
"Node name for S&R": "CheckpointLoaderSimple"
},
"widgets_values": [
"512-inpainting-ema.safetensors"
]
},
{
"id": 9,
"type": "VAEEncodeForInpaint",
"pos": [
807.4724998882622,
127.69729991734646
],
"size": [
270,
98
],
"flags": {},
"order": 4,
"mode": 0,
"inputs": [
{
"name": "pixels",
"type": "IMAGE",
"link": 11
},
{
"name": "vae",
"type": "VAE",
"link": 13
},
{
"name": "mask",
"type": "MASK",
"link": 12
}
],
"outputs": [
{
"name": "LATENT",
"type": "LATENT",
"links": [
14
]
}
],
"properties": {
"Node name for S&R": "VAEEncodeForInpaint"
},
"widgets_values": [
6
]
},
{
"id": 4,
"type": "KSampler",
"pos": [
1245.9939625652576,
-327.1244245355592
],
"size": [
270,
474
],
"flags": {},
"order": 5,
"mode": 0,
"inputs": [
{
"name": "model",
"type": "MODEL",
"link": 5
},
{
"name": "positive",
"type": "CONDITIONING",
"link": 3
},
{
"name": "negative",
"type": "CONDITIONING",
"link": 4
},
{
"name": "latent_image",
"type": "LATENT",
"link": 14
}
],
"outputs": [
{
"name": "LATENT",
"type": "LATENT",
"links": [
6
]
}
],
"properties": {
"Node name for S&R": "KSampler"
},
"widgets_values": [
124390999760047,
"randomize",
20,
8,
"euler",
"simple",
1
]
},
{
"id": 5,
"type": "VAEDecode",
"pos": [
1600.1394985270624,
-199.912800390022
],
"size": [
140,
46
],
"flags": {},
"order": 6,
"mode": 0,
"inputs": [
{
"name": "samples",
"type": "LATENT",
"link": 6
},
{
"name": "vae",
"type": "VAE",
"link": 7
}
],
"outputs": [
{
"name": "IMAGE",
"type": "IMAGE",
"links": [
10
]
}
],
"properties": {
"Node name for S&R": "VAEDecode"
}
},
{
"id": 6,
"type": "LoadImage",
"pos": [
410.714176141669,
-56.06428450633375
],
"size": [
270,
314
],
"flags": {},
"order": 1,
"mode": 0,
"inputs": [],
"outputs": [
{
"name": "IMAGE",
"type": "IMAGE",
"links": [
11
]
},
{
"name": "MASK",
"type": "MASK",
"links": [
12
]
}
],
"properties": {
"Node name for S&R": "LoadImage",
"#sdppp_variant": "default",
"#sdppp_simple_content": "canvas",
"#sdppp_simple_mask": "canvas",
"#sdppp_simple_boundary": "canvas",
"#sdppp_label": "",
"image": "clipspace/clipspace-painted-masked-1782907270162.png [input]"
},
"widgets_values": [
"clipspace/clipspace-painted-masked-1782907270162.png [input]",
"image"
]
},
{
"id": 8,
"type": "SaveImage",
"pos": [
1828.602850783038,
-281.59018474836523
],
"size": [
270,
270
],
"flags": {},
"order": 7,
"mode": 0,
"inputs": [
{
"name": "images",
"type": "IMAGE",
"link": 10
}
],
"outputs": [
{
"name": "images",
"type": "IMAGE",
"links": null
}
],
"properties": {},
"widgets_values": [
"ComfyUI"
]
},
{
"id": 3,
"type": "CLIPTextEncode",
"pos": [
795.8296892828539,
-433.0249848890706
],
"size": [
400,
200
],
"flags": {},
"order": 2,
"mode": 0,
"inputs": [
{
"name": "clip",
"type": "CLIP",
"link": 1
}
],
"outputs": [
{
"name": "CONDITIONING",
"type": "CONDITIONING",
"links": [
3
]
}
],
"title": "# Positive",
"properties": {
"Node name for S&R": "CLIPTextEncode",
"sdppp_widgetable_title": "# Positive"
},
"widgets_values": [
"Lotus in a photo style"
],
"color": "#232",
"bgcolor": "#353"
},
{
"id": 2,
"type": "CLIPTextEncode",
"pos": [
796.8267675545898,
-145.91688143342552
],
"size": [
400,
200
],
"flags": {},
"order": 3,
"mode": 0,
"inputs": [
{
"name": "clip",
"type": "CLIP",
"link": 2
}
],
"outputs": [
{
"name": "CONDITIONING",
"type": "CONDITIONING",
"links": [
4
]
}
],
"title": "# Negative",
"properties": {
"Node name for S&R": "CLIPTextEncode",
"sdppp_widgetable_title": "# Negative"
},
"widgets_values": [
"watermark, text"
],
"color": "#322",
"bgcolor": "#533"
}
],
"links": [
[
1,
1,
1,
3,
0,
"CLIP"
],
[
2,
1,
1,
2,
0,
"CLIP"
],
[
3,
3,
0,
4,
1,
"CONDITIONING"
],
[
4,
2,
0,
4,
2,
"CONDITIONING"
],
[
5,
1,
0,
4,
0,
"MODEL"
],
[
6,
4,
0,
5,
0,
"LATENT"
],
[
7,
1,
2,
5,
1,
"VAE"
],
[
10,
5,
0,
8,
0,
"IMAGE"
],
[
11,
6,
0,
9,
0,
"IMAGE"
],
[
12,
6,
1,
9,
2,
"MASK"
],
[
13,
1,
2,
9,
1,
"VAE"
],
[
14,
9,
0,
4,
3,
"LATENT"
]
],
"groups": [],
"config": {},
"extra": {
"ds": {
"scale": 0.5209868481924379,
"offset": [
391.41739425667214,
743.0980180178185
]
},
"frontendVersion": "1.45.19"
},
"version": 0.4
}加载图片,绘制蒙版,让它画上荷花: