正文
4.1 word2vec 的改进 1
对于 CBOW 模型,在处理大规模语料库时,就会出现问题。
假设词汇量有 100 万个,CBOW 模型的中间层神经元有 100 个,输入层和输出层存在 100 万个神经元。在如此多的神经 元的情况下,中间的计算过程需要很长时间。
出现问题:
-
输入层的 one-hot 表示和权重矩阵 的乘积
- 在词汇量有 100 万个的情况下,仅 one-hot 表示本身就需要占用 100 万个元素的内存大小。此外,还需要计算 one-hot 表示和权重矩阵 的乘积,这也要花费大量的计算资源。
- 通过引入新的 Embedding 层来解决
- 在词汇量有 100 万个的情况下,仅 one-hot 表示本身就需要占用 100 万个元素的内存大小。此外,还需要计算 one-hot 表示和权重矩阵 的乘积,这也要花费大量的计算资源。
-
中间层和权重矩阵 的乘积以及 Softmax 层的计算
-
中间层和权重矩阵 的乘积需要大量的计算。其次,随着词汇量的增加,Softmax 层的计算量也会增加
- 引入新的损失函数 Negative Sampling 来解决
-
4.1.1 Embedding 层
如果语料库的词汇量有 100 万个,则单词的 one-hot 表示的维数也会是 100 万,我们需要计算这个巨大向量和权重矩阵的乘积。
直觉上将单词转化为 one-hot 向量的处理和 MatMul 层中的矩阵乘法似乎没有必要。
创建一个从权重参数中抽取“单词 ID 对应行(向量)”的层,这里我们称之为 Embedding 层。
这个 Embedding 层存放词嵌入(分布式表示)。
在自然语言处理领域,单词的密集向量表示称为词嵌入(word embedding)或者单词的分布式表示(distributed representation)。
4.1.2 Embedding 层的实现
从矩阵中取出某一行的处理是很容易实现的。这里,假设权重 W 是 NumPy 的二维数组。如果要从这个权重中取出某个特定的行,只需写 W[2]
或者 W[5]。
import numpy as np
W = np.arange(21).reshape(7, 3)
Warray([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17],
[18, 19, 20]])
W[2]array([[ 6, 7, 8],
[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17],
[18, 19, 20]])
从权重 W 中一次性提取多行的处理也很简单。只需通过数组指定行号即可。
idx = np.array([1, 0, 3, 0])
W[idx]array([[ 3, 4, 5],
[ 0, 1, 2],
[ 9, 10, 11],
[ 0, 1, 2]])
实现 Embedding 层的 forward() 和 backward()方法:
class Embedding:
def __init__(self, W):
"""
使用 params 和 grads 作为成员变量
"""
self.params = [W]
self.grads = [np.zeros_like(W)]
self.idx = None
def forward(self, idx):
"""
在成员变量 idx 中以数组的形式保存需要提取的行的索引(单词 ID)
在反向传播时,从上一层(输出侧的层)传过来的梯度将原样传给下一层(输入侧的层)。
不过,从上一层传来的梯度会被应用到权重梯度 dW 的特定行(idx)
"""
W, = self.params
self.idx = idx
out = W[idx]
return out
def backward(self, dout):
dW, = self.grads
dW[...] = 0
"""
dW[self.idx] = dout 是不太好的方式,存在一个问题,
这一问题发生在 idx 的元素出现重复时,其中某个值就会被覆盖掉。
"""
for i, word_id in enumerate(self.idx):
dW[word_id] += dout[i]
# 或者
# np.add.at(dW, self.idx, dout)
return None4.2 word2vec 的改进 2
采用名为负采样(negative sampling)的方法作为解决方案。使用 Negative Sampling 替代 Softmax,无论词汇量有多大,都可以使计算量保持较低或恒定。
4.2.1 中间层之后的计算问题
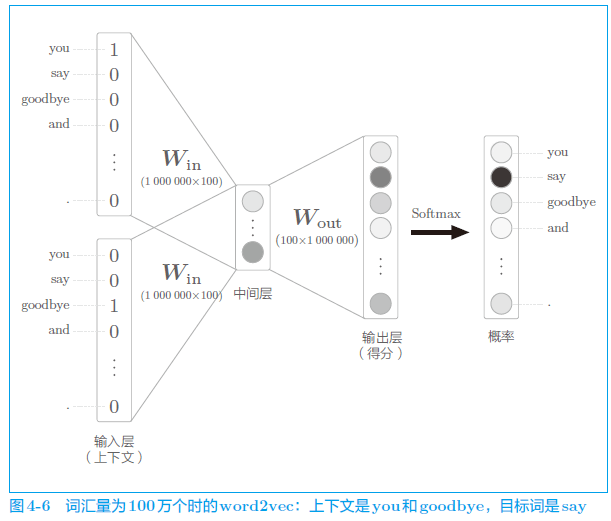
输入层和输出层有 100 万个神经元。在上一节中,通过引入 Embedding 层,节省了输入层中不必要的计算。剩下的问题就是中间层之后的处理。此时,在以下两个地方需要很多计算时间。
-
中间层的神经元和权重矩阵()的乘积
- 问题在于巨大的矩阵乘积计算。在上面的例子中,中间层向量的大小是 100,权重矩阵的大小是 100 × 1 000 000 万,如此巨大的矩阵乘积计算需要大量时间(也需要大量内存)。此外,因为反向传播时也要进行同样的计算,所以很有必要将矩阵乘积计算“轻量化”。
-
Softmax 层的计算
- 随着词汇量的增加,Softmax 的计算量也会增加,这个计算量与词汇量成正比。
4.2.2 从多分类到二分类
现在,我们来考虑如何将多分类问题转化为二分类问题。为此,我们先考察一个可以用“Yes/No”来回答的问题。比如,让神经网络来回答“当上下文是 you 和 goodbye 时,目标词是 say 吗?”这个问题,这时输出层只需要一个神经元即可。可以认为输出层的神经元输出的是 say 的得分。
输出层的神经元仅有一个。因此,要计算中间层和输出侧的权重矩阵的乘积,只需要提取 say 对应的列(单词向量),并用它与中间层的神经元计算内积即可。
4.2.3sigmoid 函数和交叉熵误差
在多分类的情况下,输出层使用 Softmax 函数将得分转化为概率,损失函数使用交叉熵误差。在二分类的情况下,输出层使用 sigmoid 函数,损失函数也使用交叉熵误差。
通过 sigmoid 函数得到概率 后,可以由概率 计算损失。与多分类一样,用于 sigmoid 函数的损失函数也是交叉熵误差,其数学式如下所示:
其中, 是 sigmoid 函数的输出, 是正确解标签,取值为 0 或 1;取值为 1 时表示正确解是“Yes”;取值为 0 时表示正确解是“No”。因此,当 为 1 时,输出 ;当 为 0 时,输出 。
4.2.4 多分类到二分类的实现
引入 Embedding Dot 层,该层将 Embedding 层和 dot 运算(内积)合并起来处理。
class EmbeddingDot:
def __init__(self, W):
"""
params: 保存参数
grads: 保存梯度
embed: 保存 Embedding 层作为缓存
cache: 保存正向传播时的计算结果
"""
self.embed = Embedding(W)
self.params = self.embed.params
self.grads = self.embed.grads
self.cache = None
def forward(self, h, idx):
target_W = self.embed.forward(idx)
out = np.sum(target_W * h, axis=1)
self.cache = (h, target_W)
return out
def backward(self, dout):
h, target_W = self.cache
dout = dout.reshape(dout.shape[0], 1)
dtarget_W = dout * h
self.embed.backward(dtarget_W)
dh = dout * target_W
return dh4.2.5 负采样
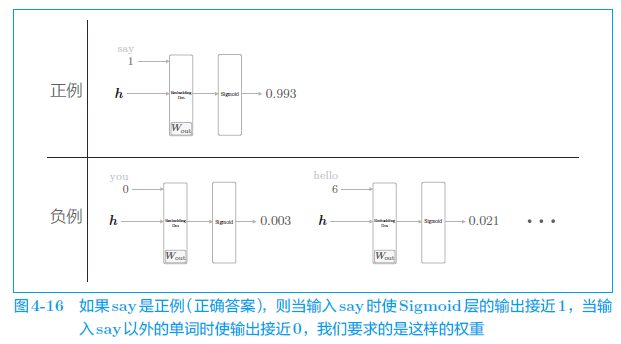
我们目前仅学习了正例(正确答案),还不确定负例(错误答案)会有怎样的结果。
当前的神经网络只是学习了正例 say,但是对 say 之外的负例一无所知。
而我们真正要做的事情是,对于正例(say),使 Sigmoid 层的输出接近 1;对于负例(say 以外的单词),使 Sigmoid 层的输出接近 0。
那么,我们需要以所有的负例为对象进行学习吗?答案显然是“No”。如果以所有的负例为对象,词汇量将暴增至无法处理(更何况本章的目的本来就是解决词汇量增加的问题)。为此,作为一种近似方法,我们将选择若干个(5 个或者 10 个)负例(如何选择将在下文介绍)。也就是说,只使用少数负例。这就是负采样方法的含义。
4.2.6 负采样的采样方法
基于语料库中各个单词的出现次数求出概率分布后,只需根据这个概率分布进行采样就可以了。通过根据概率分布进行采样,语料库中经常出现的单词将容易被抽到,而“稀有单词”将难以被抽到。
使用 Python 来说明基于概率分布的采样:
# 从 0 到 9 的数字中随机选择一个数字
np.random.choice(10)4
# 从 words 列表中随机选择一个元素
words = ['you', 'say', 'goodbye', 'I', 'hello', '.']
np.random.choice(words)'goodbye'
# 有放回采样 5 次
np.random.choice(words, size=5)array(['you', '.', 'say', 'hello', 'say'], dtype='<U7')
# 无放回采样 5 次
np.random.choice(words, size=5, replace=False)array(['goodbye', 'I', 'say', 'you', 'hello'], dtype='<U7')
# 基于概率分布进行采样
p = [0.5, 0.1, 0.05, 0.2, 0.05, 0.1]
np.random.choice(words, p=p)'I'
word2vec 中提出的负采样对刚才的概率分布增加了一个步骤。如下式所示,对原来的概率分布取 0.75 次方。
为了防止低频单词被忽略。更准确地说,通过取 0.75 次方,低频单词的概率将稍微变高。
p = [0.7, 0.29, 0.01]
new_p = np.power(p, 0.75)
new_p /= np.sum(new_p)
print(new_p)[0.64196878 0.33150408 0.02652714]
根据这个例子,变换前概率为 0.01(1%)的元素,变换后为 0.026...(2.6...%)。通过这种方式,取 0.75 次方作为一种补救措施,使得低频单词稍微更容易被抽到。
此外,0.75 这个值并没有什么理论依据,也可以设置成 0.75 以外的值。
corpus = np.array([0, 1, 2, 3, 4, 1, 2, 3])
power = 0.75
sample_size = 2
# 该方法以参数 target 指定的单词 ID 为正例,对其他的单词 ID 进行采样。
sampler = UnigramSampler(corpus, power, sample_size)
target = np.array([1, 3, 0])
negative_sample = sampler.get_negative_sample(target)
print(negative_sample)4.2.7 负采样的实现
class NegativeSamplingLoss:
def __init__(self, W, corpus, power=0.75, sample_size=5):
self.sample_size = sample_size
self.sampler = UnigramSampler(corpus, power, sample_size)
self.loss_layers = [SigmoidWithLoss() for _ in range(sample_size + 1)]
self.embed_dot_layers = [EmbeddingDot(W) for _ in range(sample_size + 1)]
self.params, self.grads = [], []
for layer in self.embed_dot_layers:
self.params += layer.params
self.grads += layer.grads
def forward(self, h, target):
"""
h: 中间层的神经元
target: 正例目标
"""
batch_size = target.shape[0]
# 使用 self.sampler 采样负例,并设为 negative_sample
negative_sample = self.sampler.get_negative_sample(target)
# 正例的正向传播
score = self.embed_dot_layers[0].forward(h, target)
correct_label = np.ones(batch_size, dtype=np.int32) # 正例的正确解标签为 1
loss = self.loss_layers[0].forward(score, correct_label)
# 负例的正向传播
negative_label = np.zeros(batch_size, dtype=np.int32) # 负例的正确解标签为 0
for i in range(self.sample_size):
negative_target = negative_sample[:, i]
score = self.embed_dot_layers[1 + i].forward(h, negative_target)
loss += self.loss_layers[1 + i].forward(score, negative_label)
return loss
def backward(self, dout=1):
dh = 0
for l0, l1 in zip(self.loss_layers, self.embed_dot_layers):
"""
与正向传播相反的顺序调用各层的 backward() 函数即可
"""
dscore = l0.backward(dout)
dh += l1.backward(dscore)
return dh4.3 改进版 word2vec 的学习
4.3.1 CBOW 模型的实现
import sys
sys.path.append('..')
from common.np import * # import numpy as np
from common.layers import Embedding
from ch04.negative_sampling_layer import NegativeSamplingLoss
class CBOW:
def __init__(self, vocab_size, hidden_size, window_size, corpus):
V, H = vocab_size, hidden_size
# 初始化权重
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(V, H).astype('f')
# 生成层
self.in_layers = []
for i in range(2 * window_size):
layer = Embedding(W_in) # 使用 Embedding 层
self.in_layers.append(layer)
self.ns_loss = NegativeSamplingLoss(W_out, corpus, power=0.75, sample_size=5)
# 将所有的权重和梯度整理到列表中
layers = self.in_layers + [self.ns_loss]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
# 将单词的分布式表示设置为成员变量
self.word_vecs = W_in
def forward(self, contexts, target):
h = 0
for i, layer in enumerate(self.in_layers):
h += layer.forward(contexts[:, i])
h *= 1 / len(self.in_layers)
loss = self.ns_loss.forward(h, target)
return loss
def backward(self, dout=1):
dout = self.ns_loss.backward(dout)
dout *= 1 / len(self.in_layers)
for layer in self.in_layers:
layer.backward(dout)
return None
4.3.2 CBOW 模型的学习代码
import sys
sys.path.append('..')
import numpy as np
from common import config
# 在用 GPU 运行时,请打开下面的注释(需要 cupy)
# ===============================================
config.GPU = True
# ===============================================
import pickle
from common.trainer import Trainer
from common.optimizer import Adam
from common.util import create_contexts_target, to_cpu, to_gpu
from dataset import ptb
# 设定超参数
window_size = 5
hidden_size = 100
batch_size = 100
max_epoch = 10
# 读入数据
corpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
contexts, target = create_contexts_target(corpus, window_size)
if config.GPU:
contexts, target = to_gpu(contexts), to_gpu(target)
# 生成模型等
model = CBOW(vocab_size, hidden_size, window_size, corpus)
optimizer = Adam()
trainer = Trainer(model, optimizer)
# 开始学习
trainer.fit(contexts, target, max_epoch, batch_size)
trainer.plot()
# 保存必要数据,以便后续使用
word_vecs = model.word_vecs
if config.GPU:
word_vecs = to_cpu(word_vecs)
params = {}
params['word_vecs'] = word_vecs.astype(np.float16)
params['word_to_id'] = word_to_id
params['id_to_word'] = id_to_word
pkl_file = 'cbow_params.pkl'
with open(pkl_file, 'wb') as f:
pickle.dump(params, f, -1)4.3.3 CBOW 模型的评价
import sys
sys.path.append('..')
from common.util import most_similar
import pickle
pkl_file = 'cbow_params.pkl'
with open(pkl_file, 'rb') as f:
params = pickle.load(f)
word_vecs = params['word_vecs']
word_to_id = params['word_to_id']
id_to_word = params['id_to_word']
querys = ['you', 'year', 'car', 'toyota']
for query in querys:
most_similar(query, word_to_id, id_to_word, word_vecs, top=5)4.4 word2vec 相关的其他话题
4.4.1 word2vec 的应用例
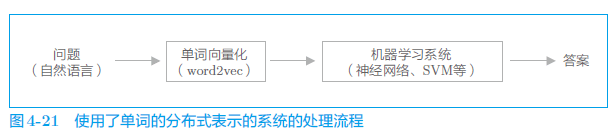
在自然语言处理领域,单词的分布式表示之所以重要,原因就在于迁移学习(transfer learning)。迁移学习是指在某个领域学到的知识可以被应用于其他领域。
将单词和文档转化为固定长度的向量是非常重要的。因为如果可以将自然语言转化为向量,就可以使用常规的机器学习方法(神经网络、SVM 等)
4.4.2 单词向量的评价方法
单词相似度的评价通常使用人工创建的单词相似度评价集来评估。比如,cat 和 animal 的相似度是 8,cat 和 car 的相似度是 2……类似这样,用 0~10 的分数人工地对单词之间的相似度打分。然后,比较人给出的分数和 word2vec 给出的余弦相似度,考察它们之间的相关性。
4.5 小结
-
Embedding 层保存单词的分布式表示,在正向传播时,提取单词 ID 对应的向量
-
因为 word2vec 的计算量会随着词汇量的增加而成比例地增加,所以最好使用近似计算来加速
-
负采样技术采样若干负例,使用这一方法可以将多分类问题转化为二分类问题进行处理
-
基于 word2vec 获得的单词的分布式表示内嵌了单词含义,在相似的上下文中使用的单词在单词向量空间上处于相近的位置
-
word2vec 的单词的分布式表示的一个特性是可以基于向量的加减法运算来求解类推问题
-
word2vec 的迁移学习能力非常重要,它的单词的分布式表示可以应用于各种各样的自然语言处理任务