正文
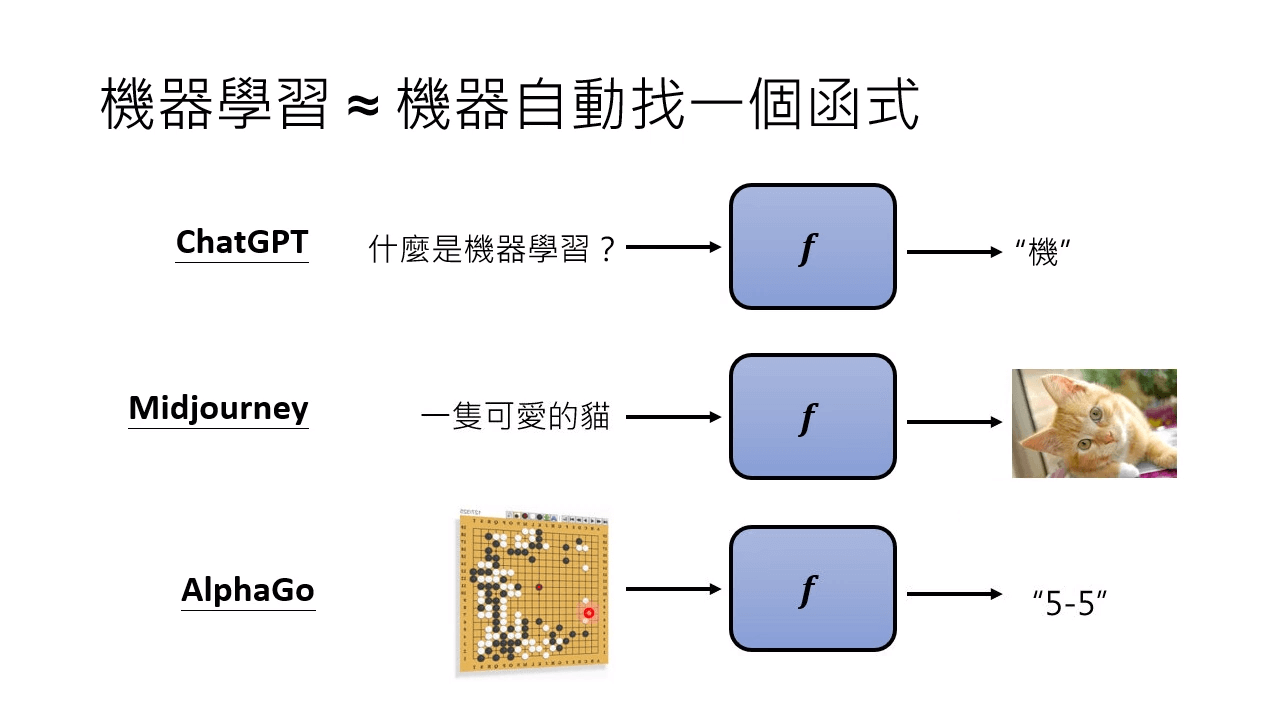
机器学习就是机器寻找一种函数,将输入转换为输出:
- ChatGPT 接受用户的输入,输出回答的答案
- Midjourney 接受用户的文本提示,输出画出的图片
- AlphaGo 接受当前的棋局状态,输出下一步下出的棋子
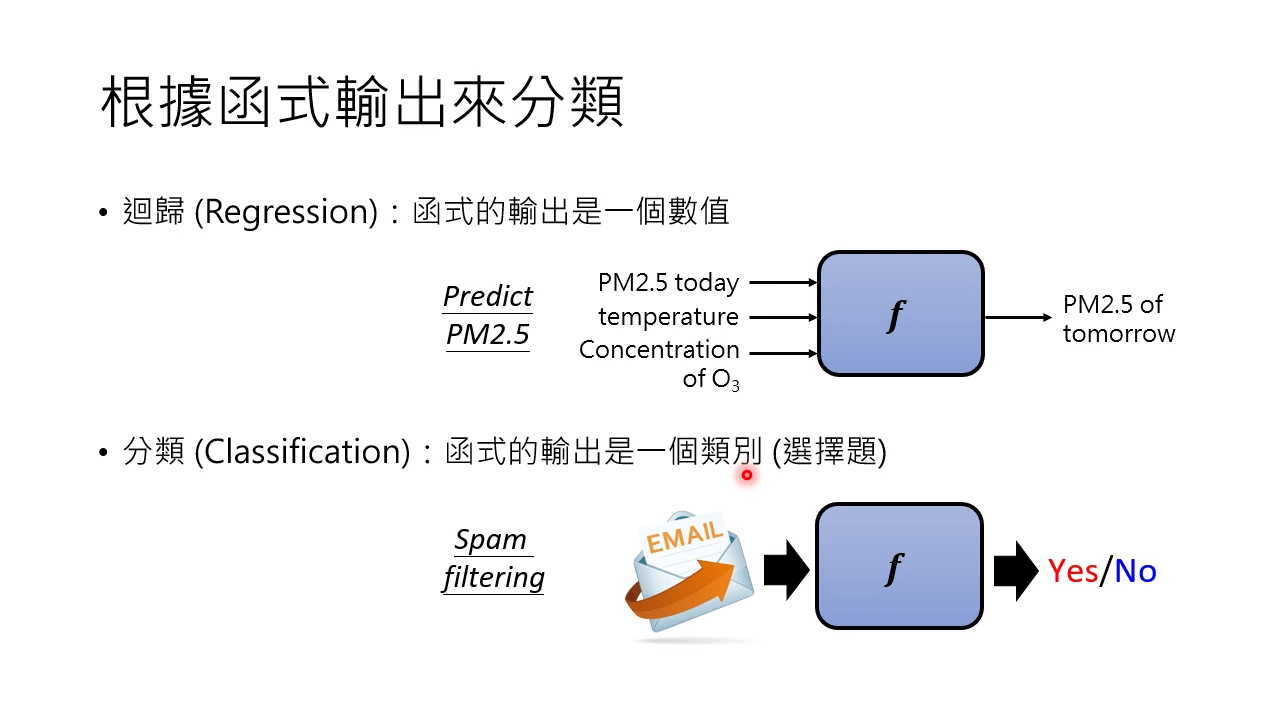
对于回归,输出的是一个数值。
对于分类,输出的是一个类别(让机器做选择题)。
之前的机器学习问题主要都是在 Regression 和 Classification 上。现在的一大热点是生成式学习(Generative Learning)。
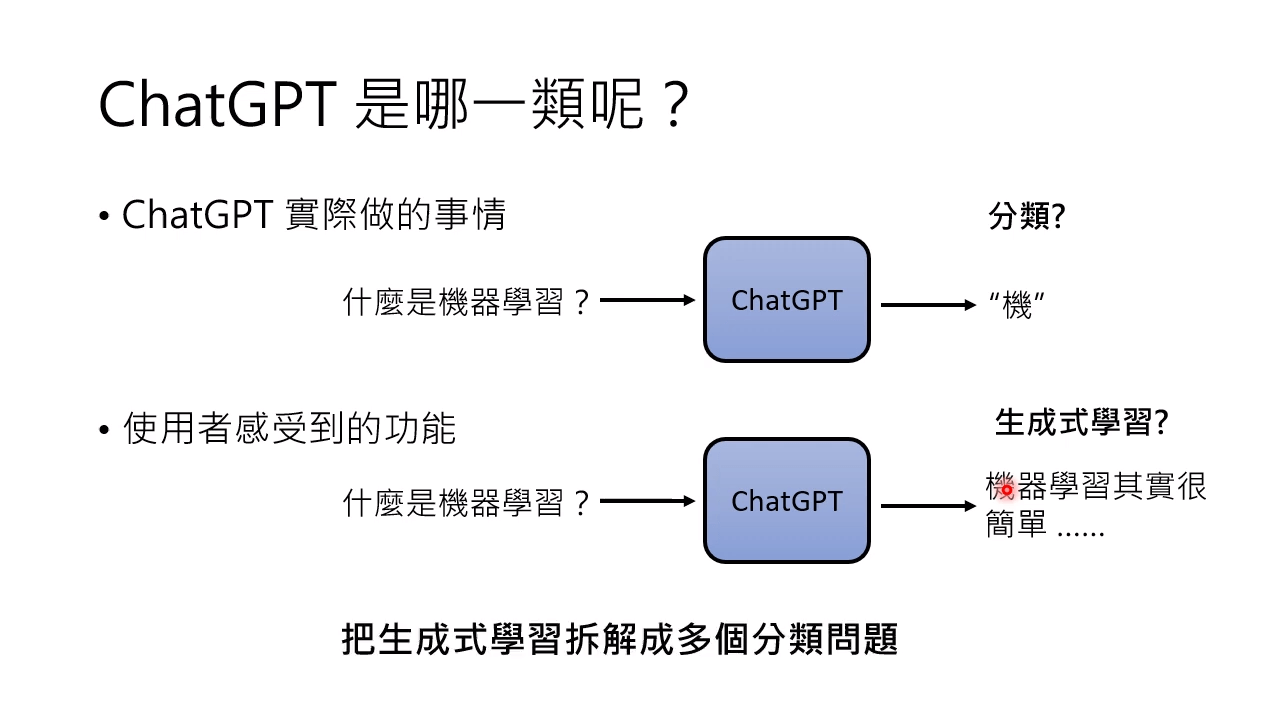
ChatGPT 的生成学习可以看作是多个分类问题,每次输出一个 token。
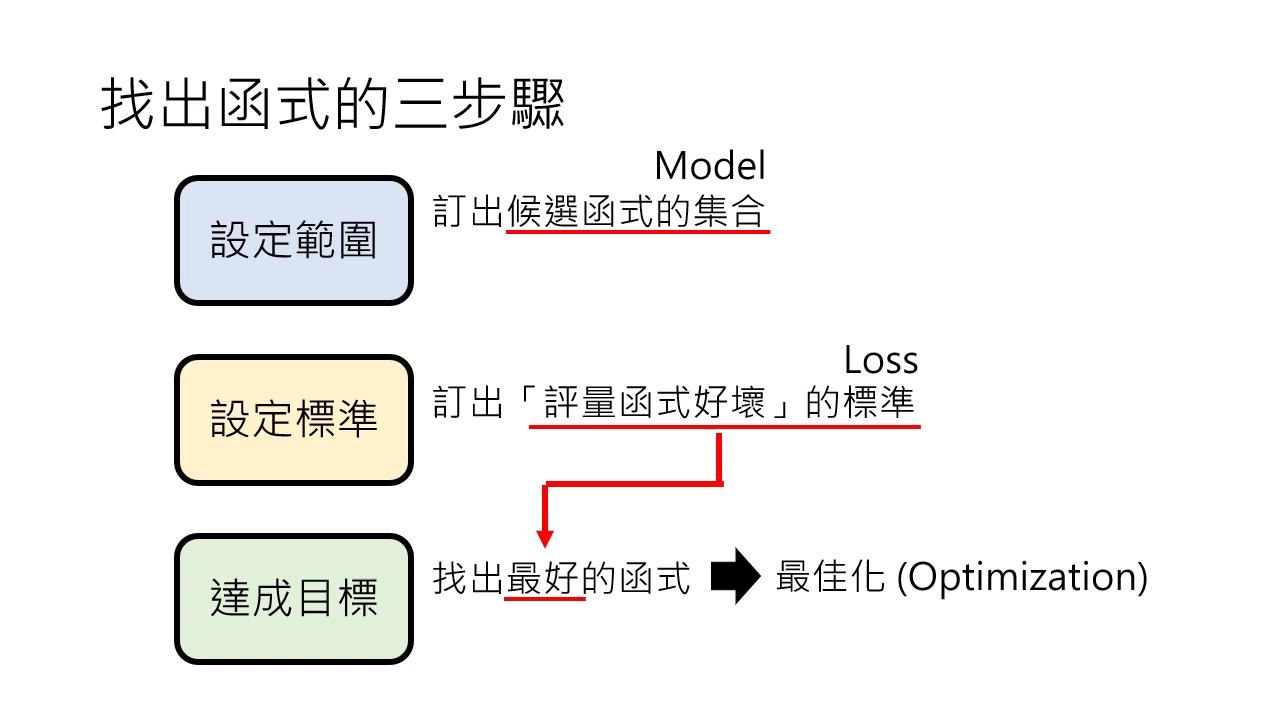
机器学习的三步骤:
- 设定范围:定出候选涵式的集合 Model
- 设定标准:订出 评量涵式好坏 的标准 Loss
- 达成目标:找出最好的涵式(Loss 最小)→ 最佳化 Optimization
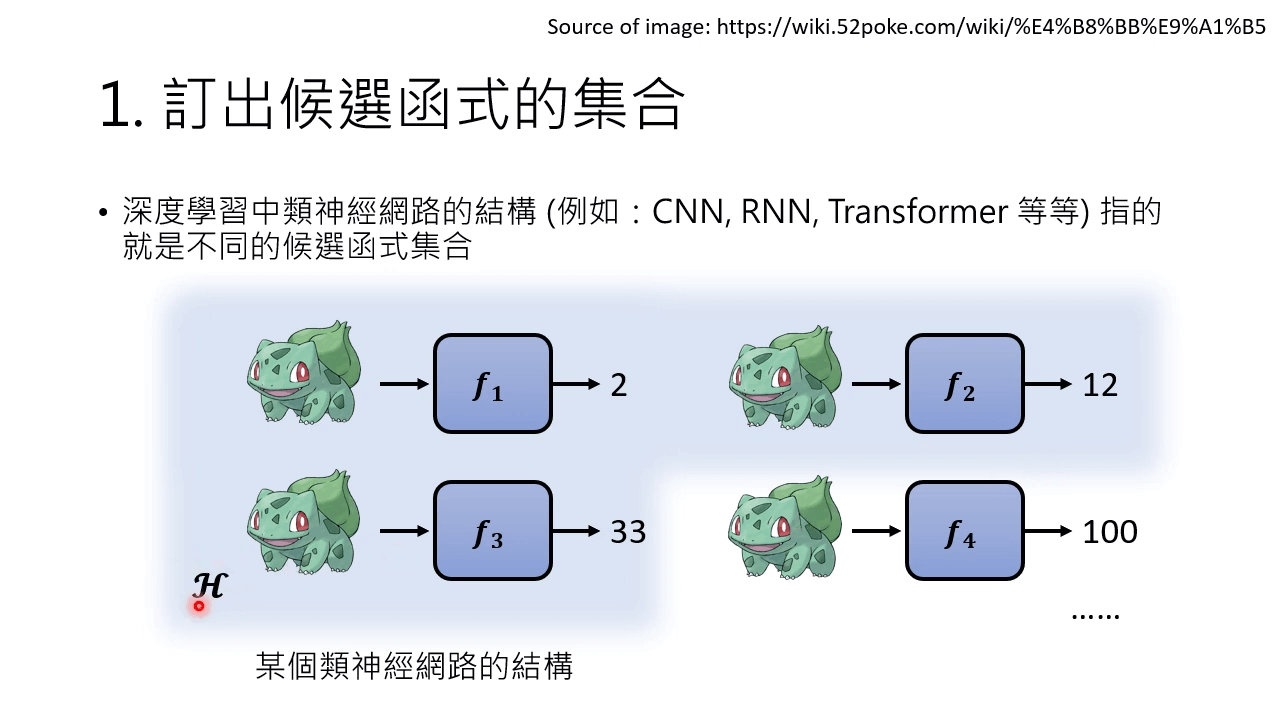
深度学习中各种神经网络架构的组合成一个 Model。
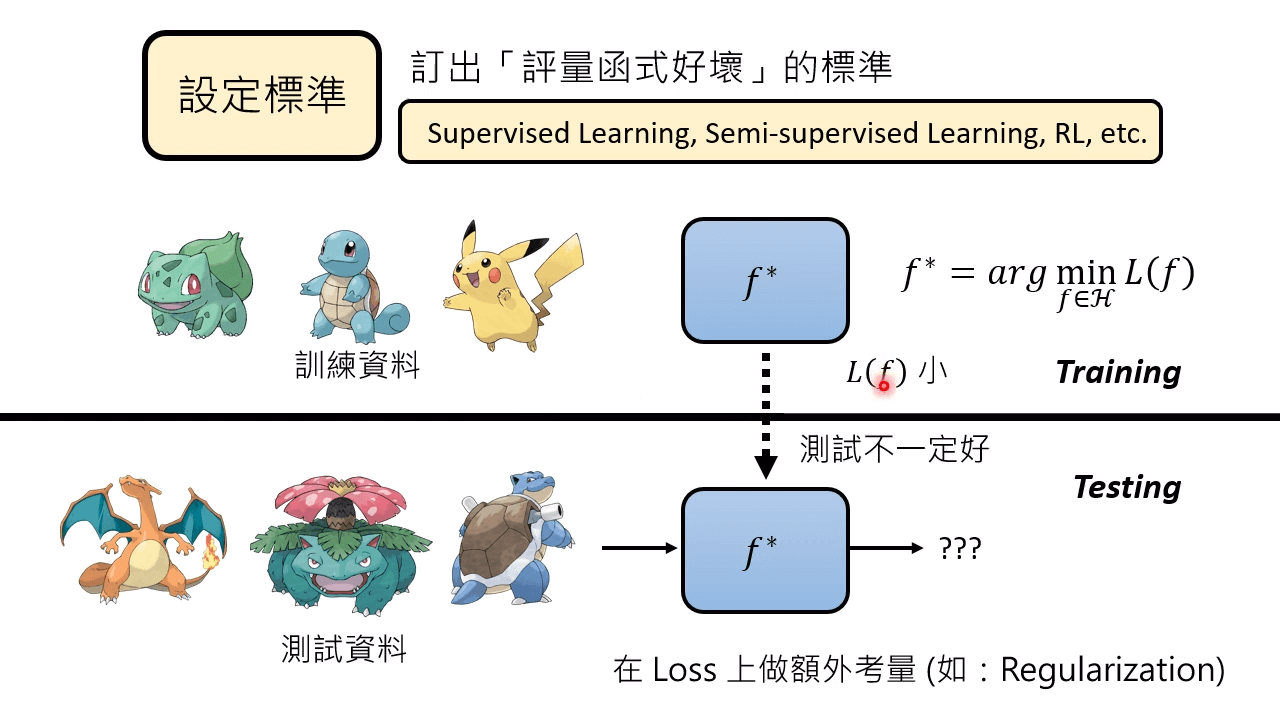
设定标准:订出 评量涵式好坏 的标准,用在有监督学习、半监督学习、强化学习等等。
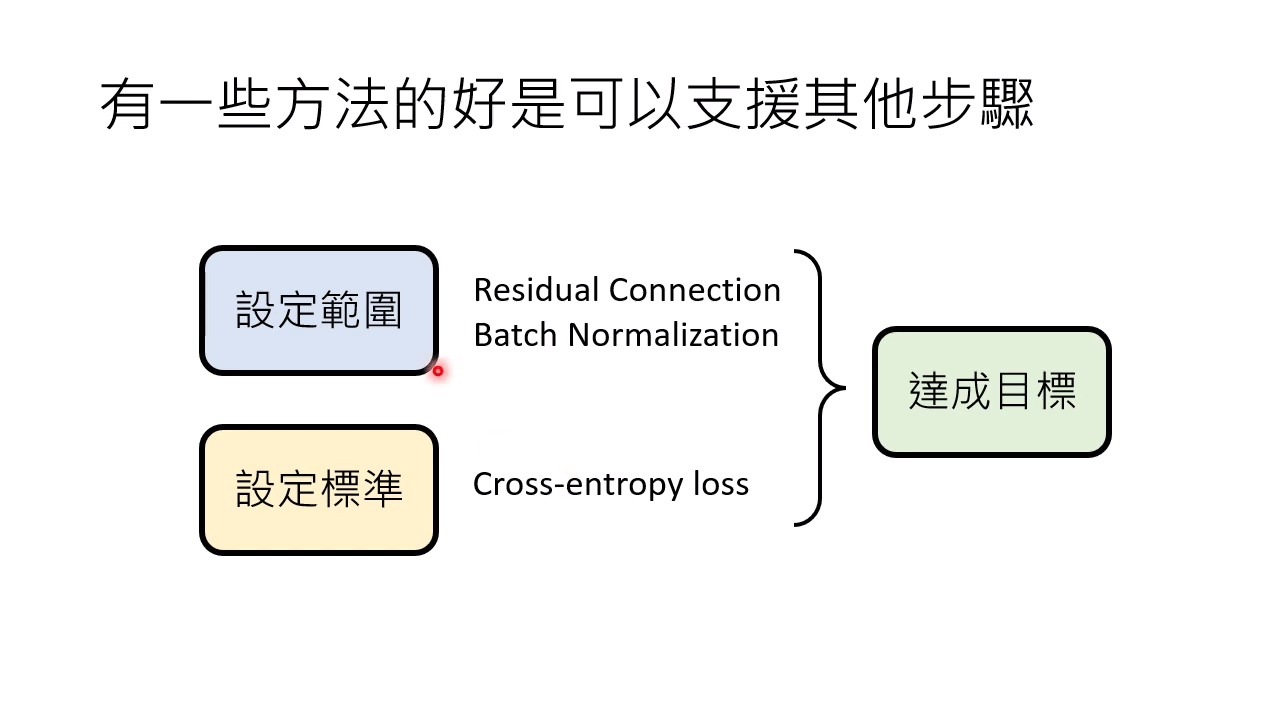
为了达成目标,在 Model 上可以做出:
- Residual Connection 残差连接
- Batch Normalization 批次正则化
Loss 函数选择 Cross-entropy loss 等。
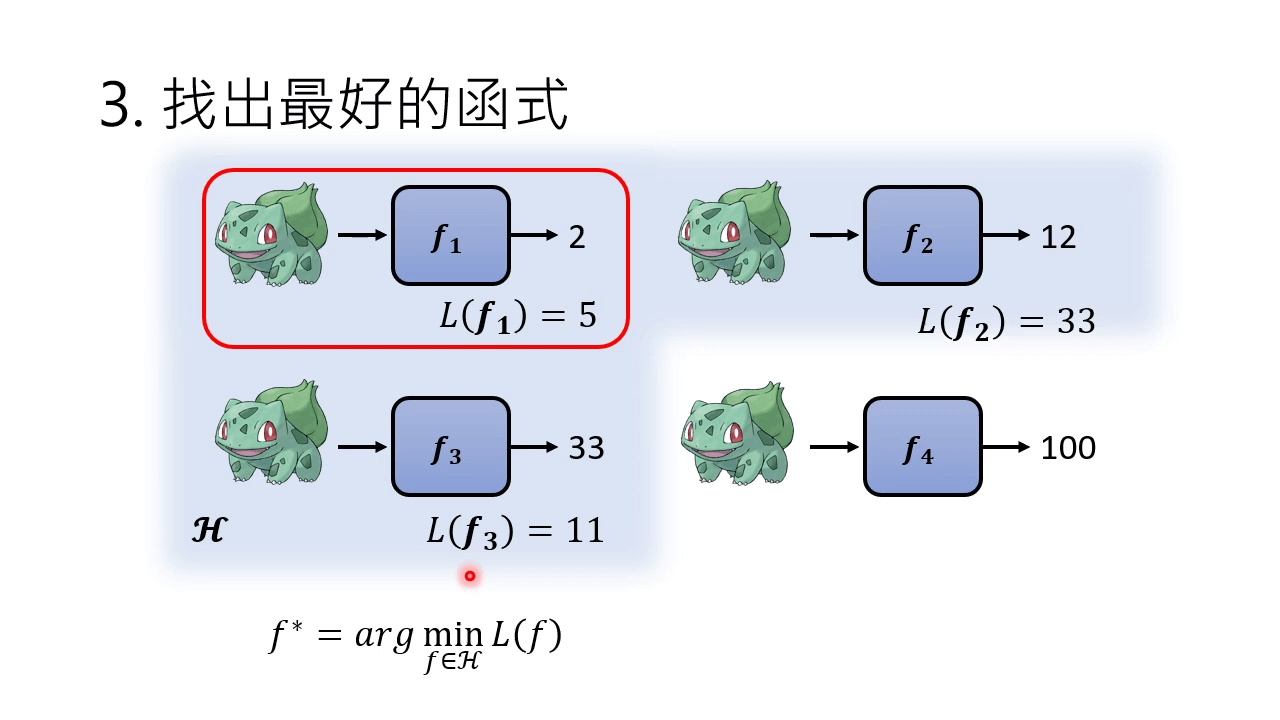
想办法使得损失函数的值变小,各种梯度下降。
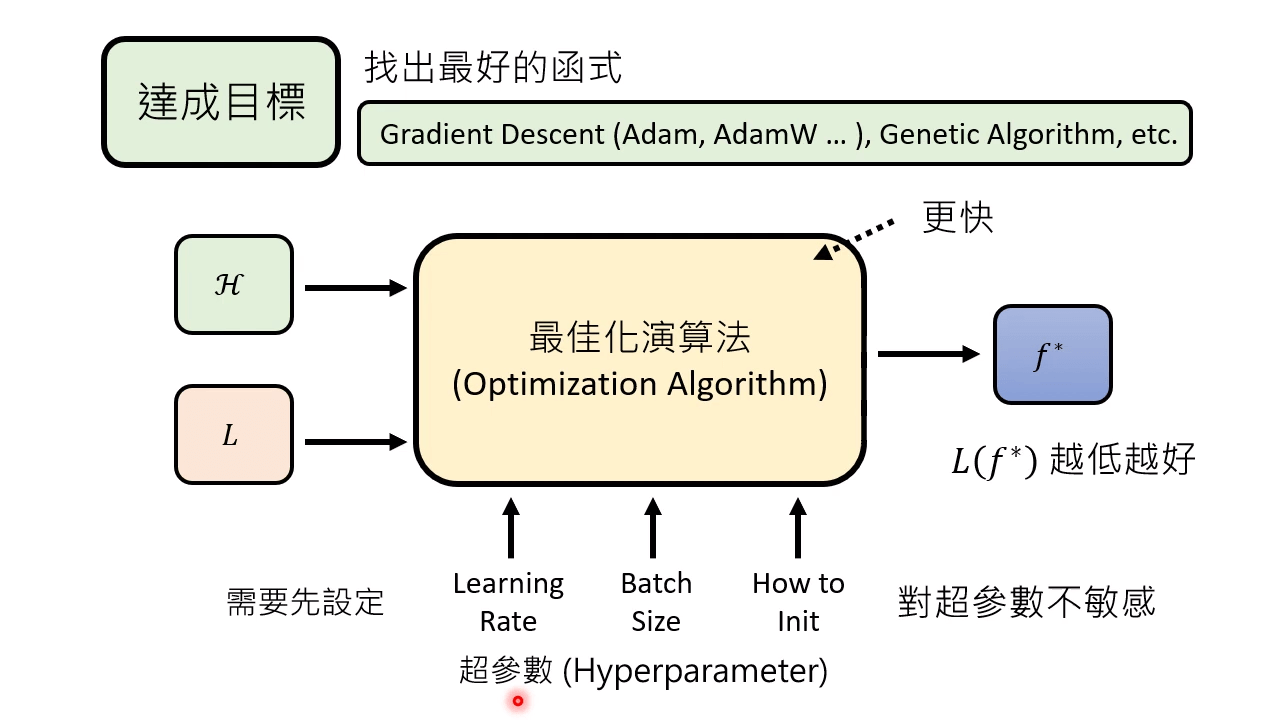
设置超参数也可使训练效果更好,好训练的模型对超参数不敏感。
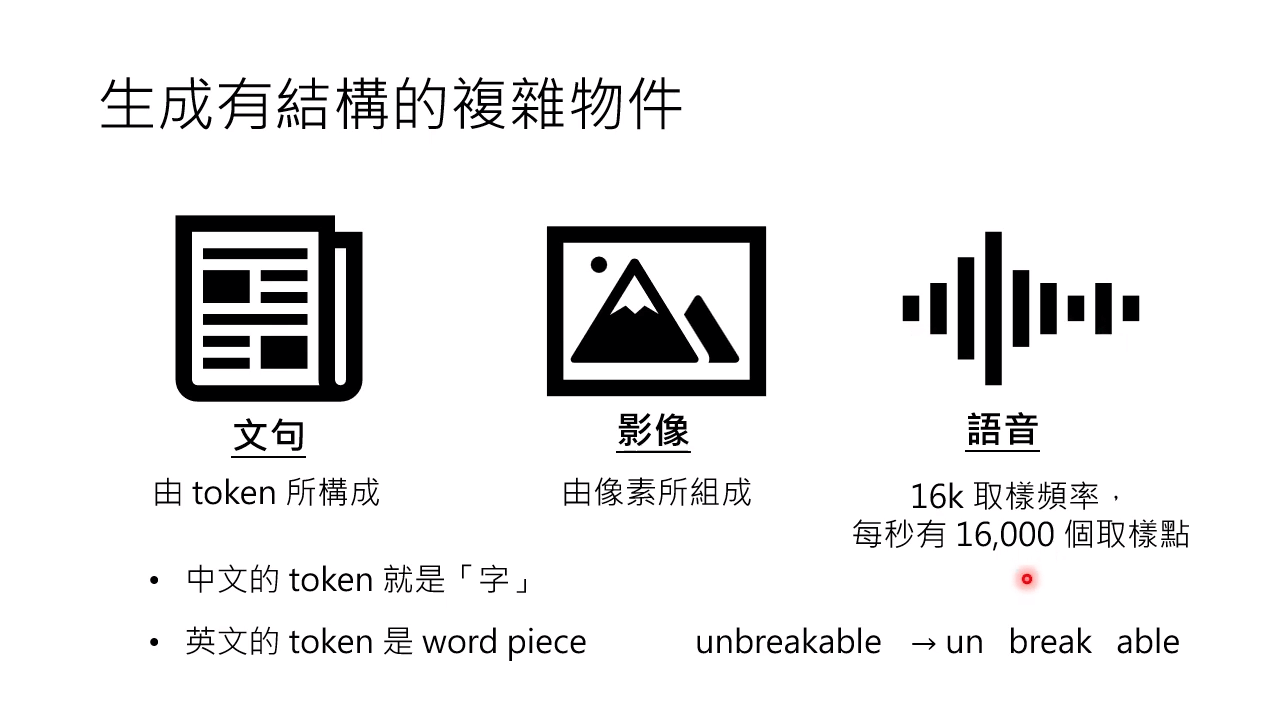
对于生成式网络,可以生成有结构的复杂物件:
- 文句:由 token 组成
- 影像:由像素组成
- 语音:由采样点组成
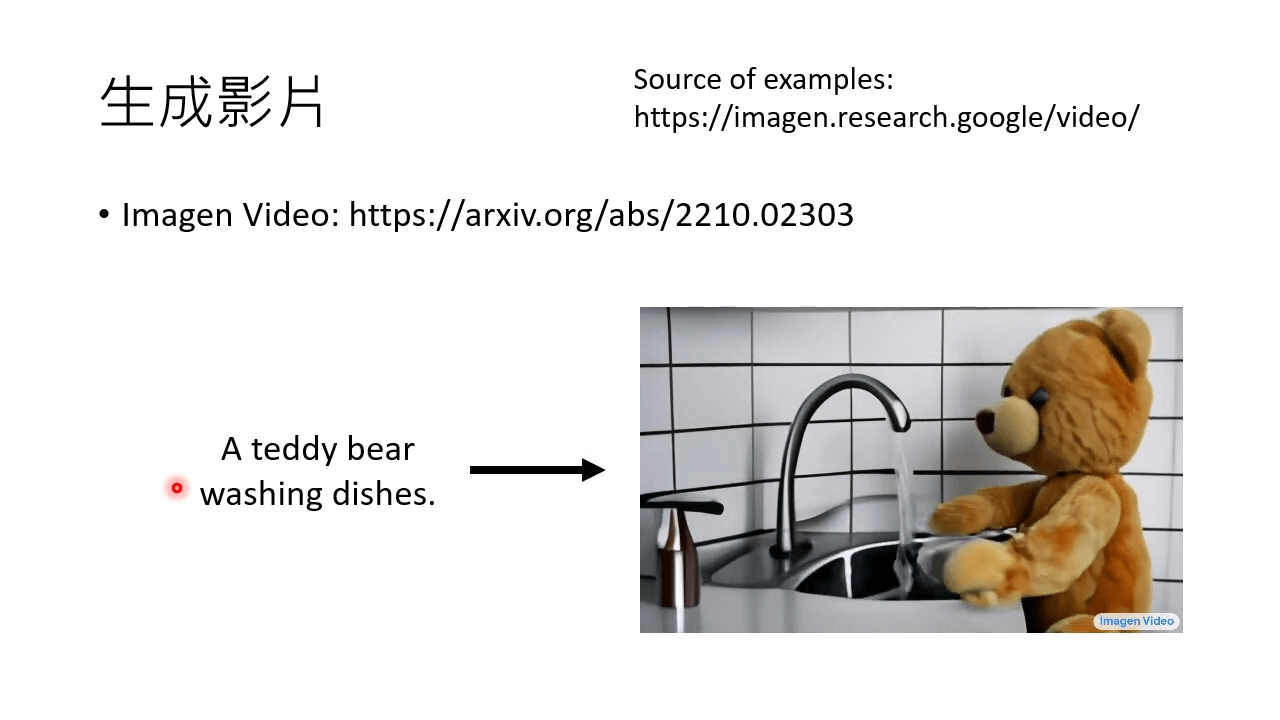
输入文本提示,生成影片:
演示:Imagen Video (research.google)
论文:[2210.02303] Imagen Video: High Definition Video Generation with Diffusion Models (arxiv.org)

根据文本提示的语境,生成不同声音。
演示:AudioLDM: Text-to-Audio Generation with Latent Diffusion Models - Speech Research
论文:[2301.12503] AudioLDM: Text-to-Audio Generation with Latent Diffusion Models (arxiv.org)
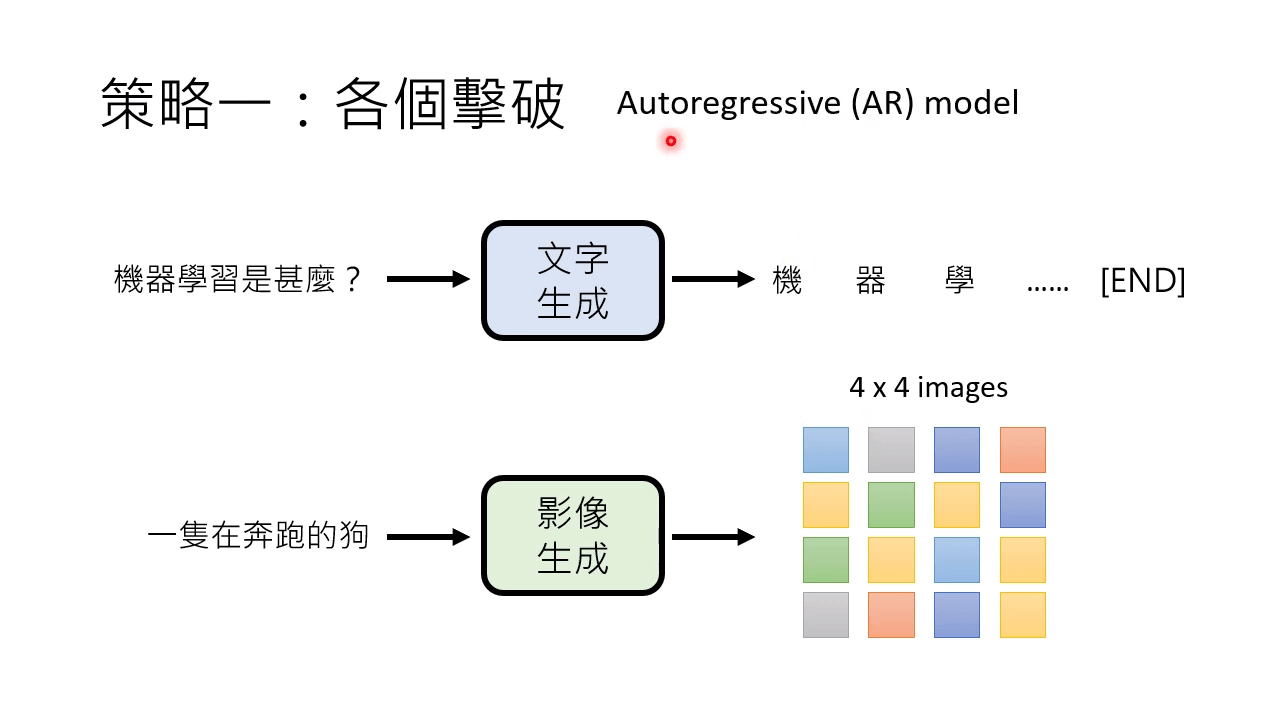
对于生成式模型,策略一,各个击破:Autoregressive (AR) model
生成文本:一个 token 一个 token 地生成
生成影像:一个像素一个像素地生成

用一次只生成一个像素的方式让机器自己画宝可梦。ML Lecture 17: Unsupervised Learning - Deep Generative Model (Part I) - YouTube
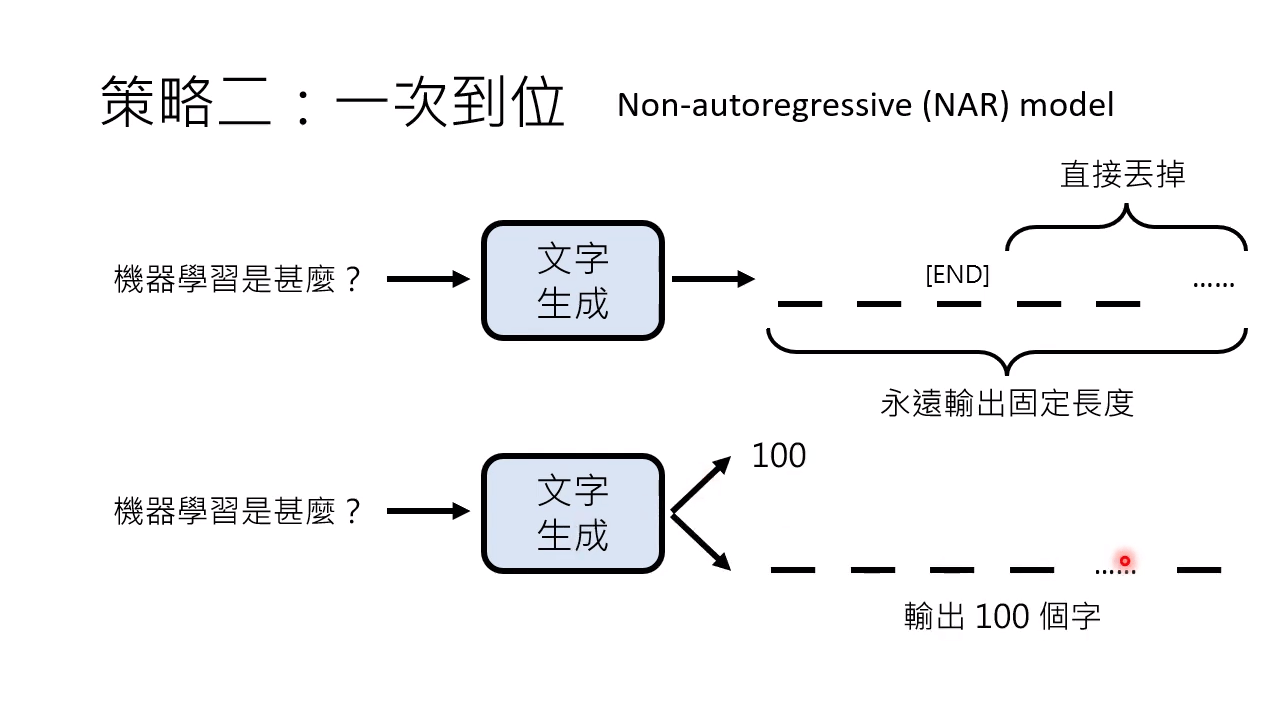
策略二:一次到位:Non-autoregressive (NAR) model
需要固定输出长度,要让输出长度不同,可以预先设定 [END] 标记。
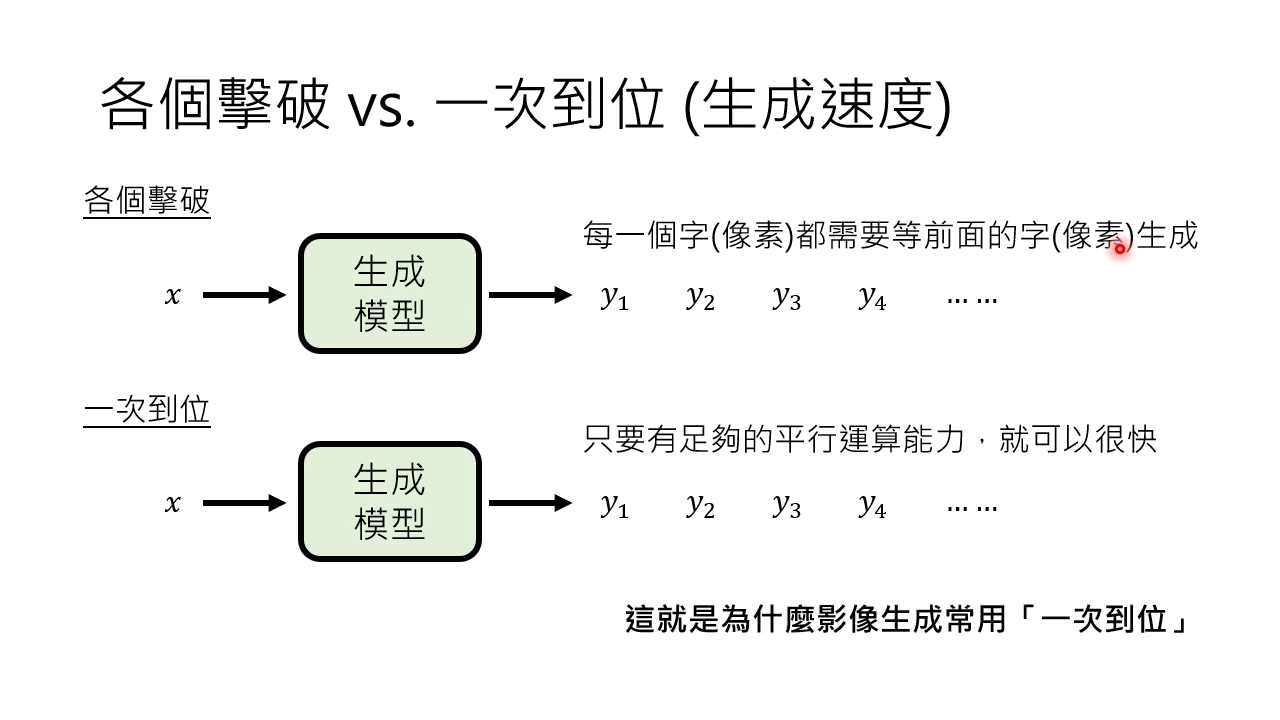
一次到位的生成速度要比各个击破快很多。
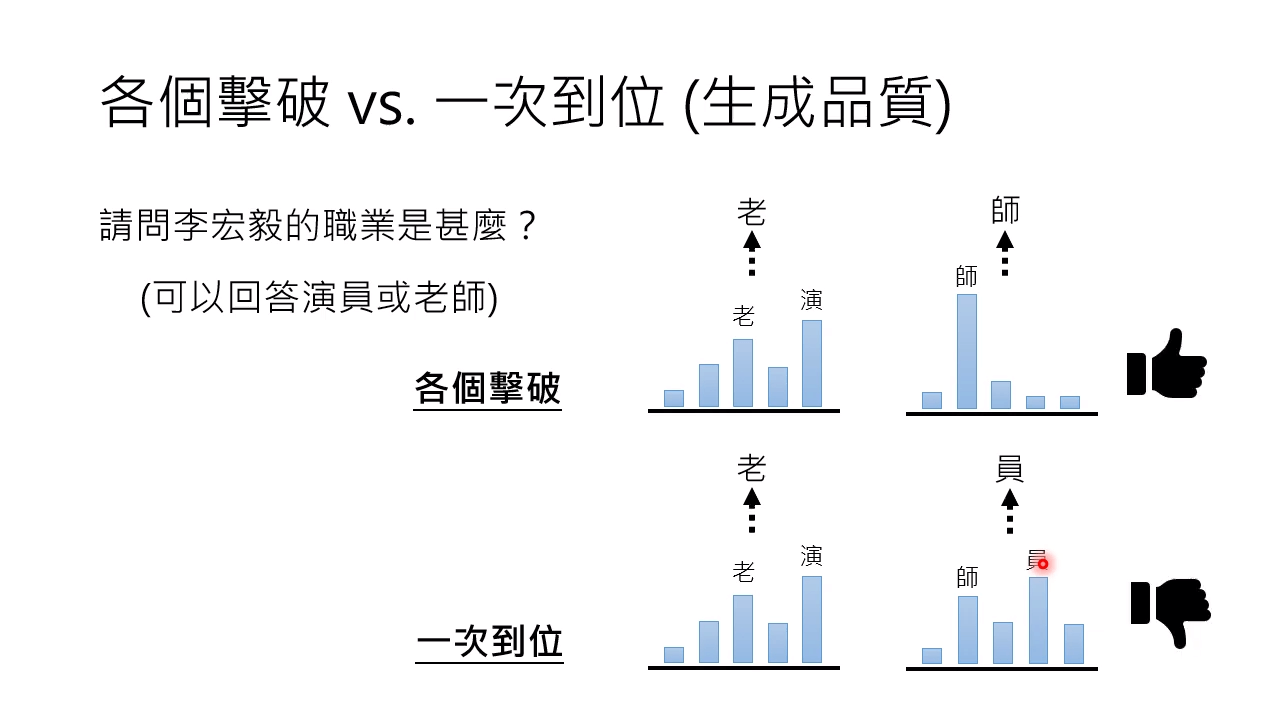
各个击破的生成品质要更好。对于一次到位,可能会出现多个分布杂揉起来的结果。

| 各个击破 (Autoregressive, AR) | 一次到位 (Non-autoregressive, NAR) | |
|---|---|---|
| 速度 | 胜 | |
| 品质 | 胜 | |
| 应用 | 常用于文字 | 常用于影像 |
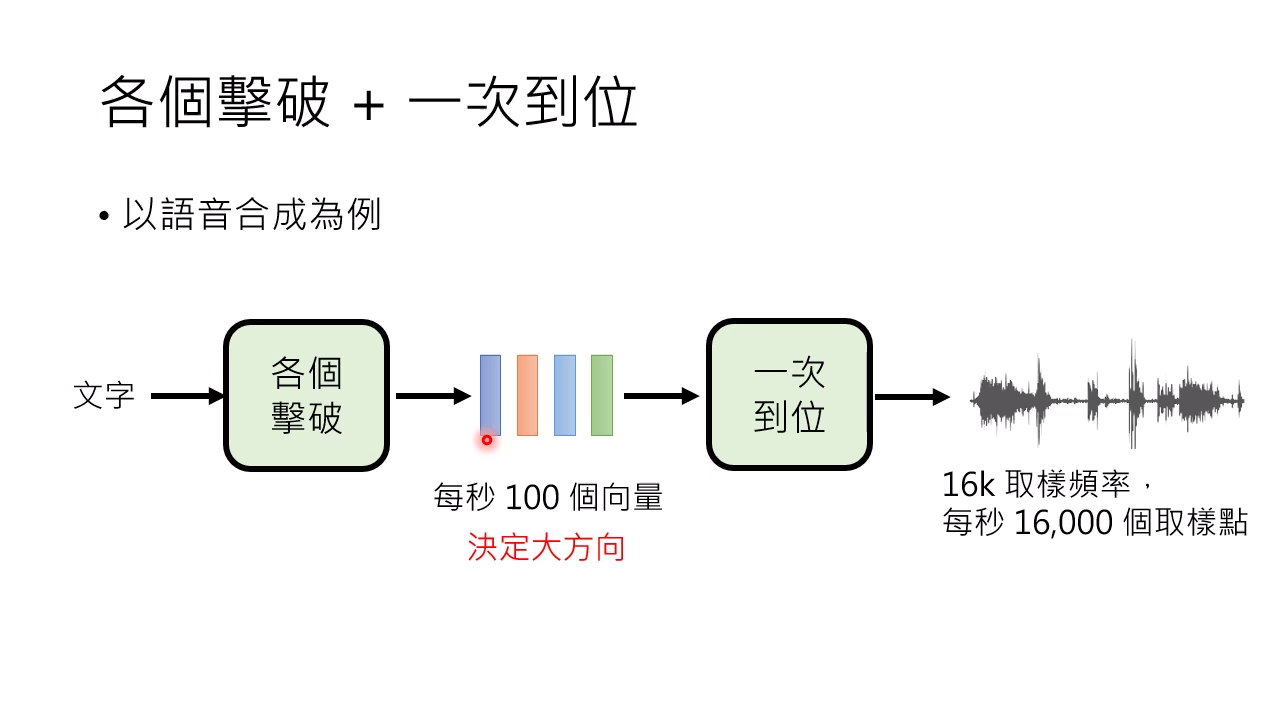
取各个击破和一次到位的优点。
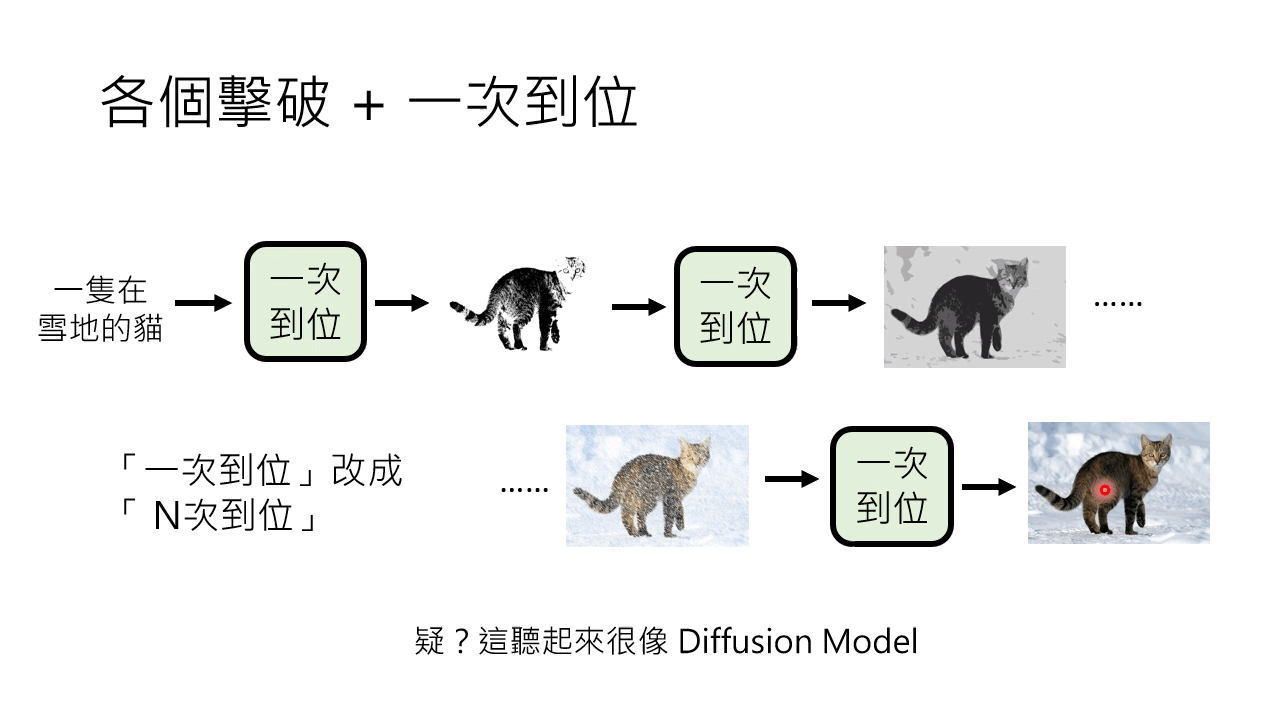
将一次到位改成多次到位,是扩散模型的思想。
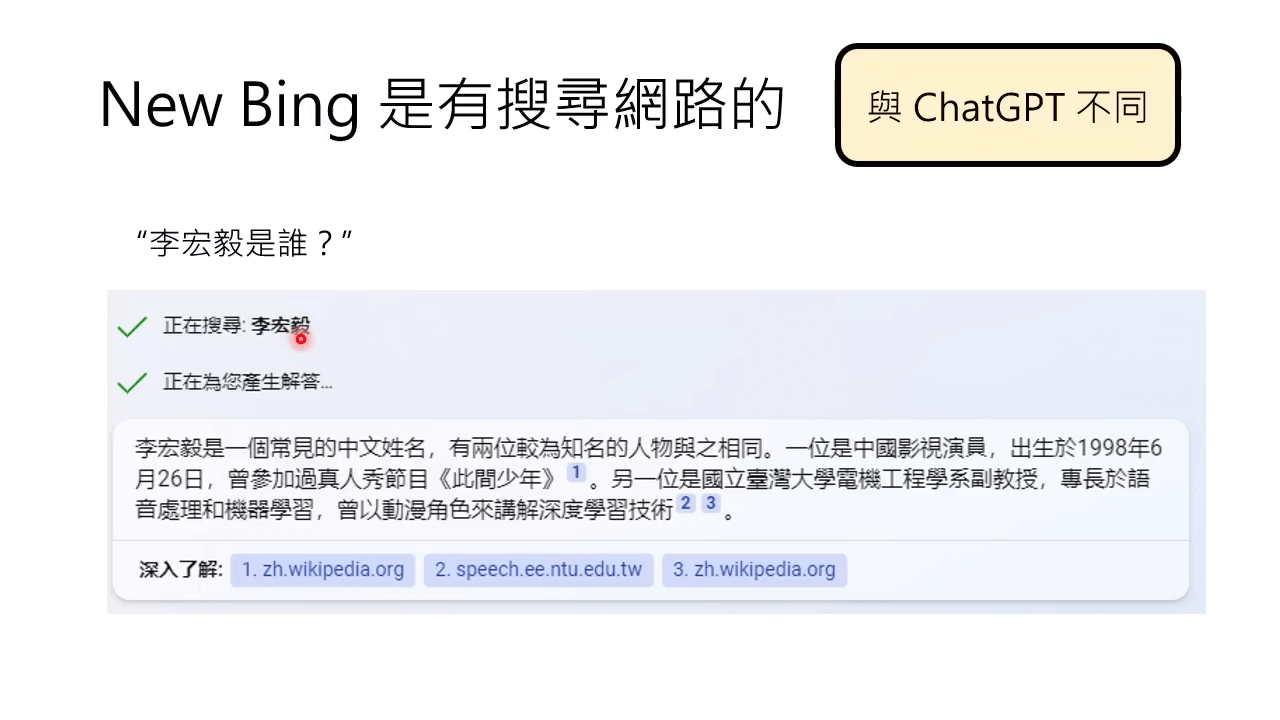
与 ChatGPT 不同,New Bing 可以从网上搜索知识。

但就是从网页中搜索知识,机器还是可能瞎编。
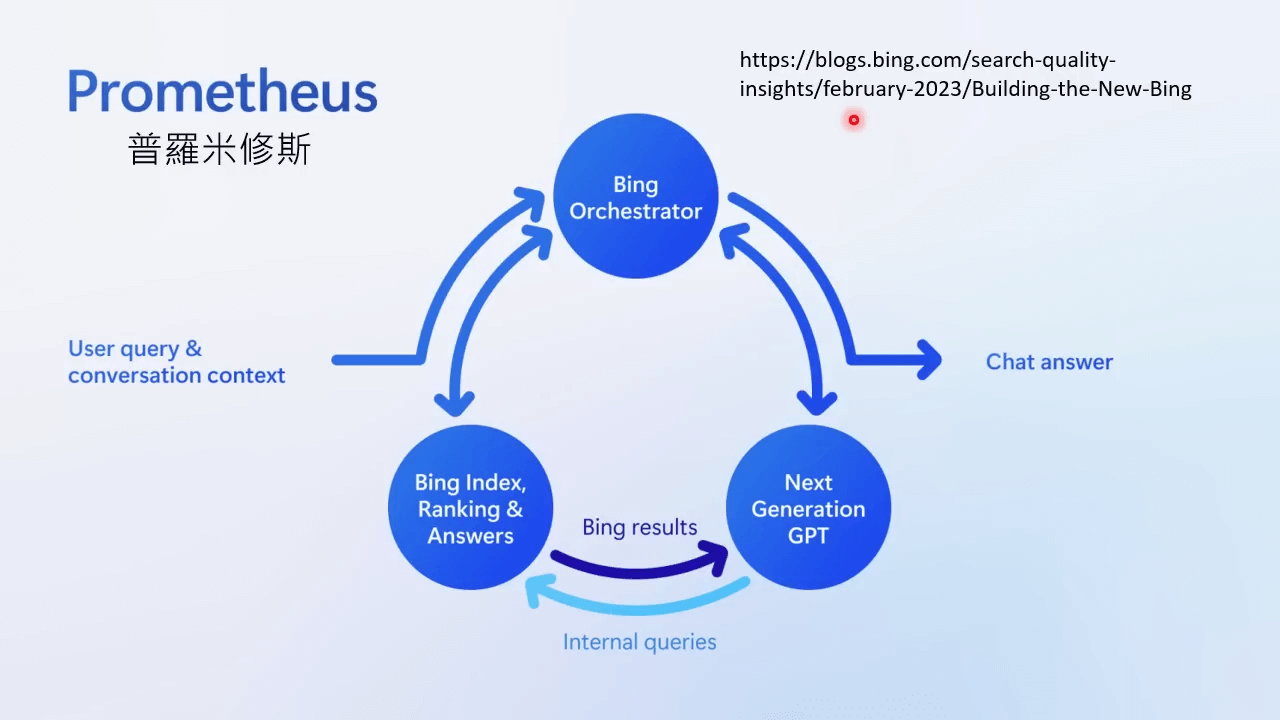
New Bing 原理的示意图,使用了定制的 GPT 模型。Building the New Bing | Search Quality Insights

New Bing 跟 WebGPT 很像,也可以使用搜索引擎来获取答案。
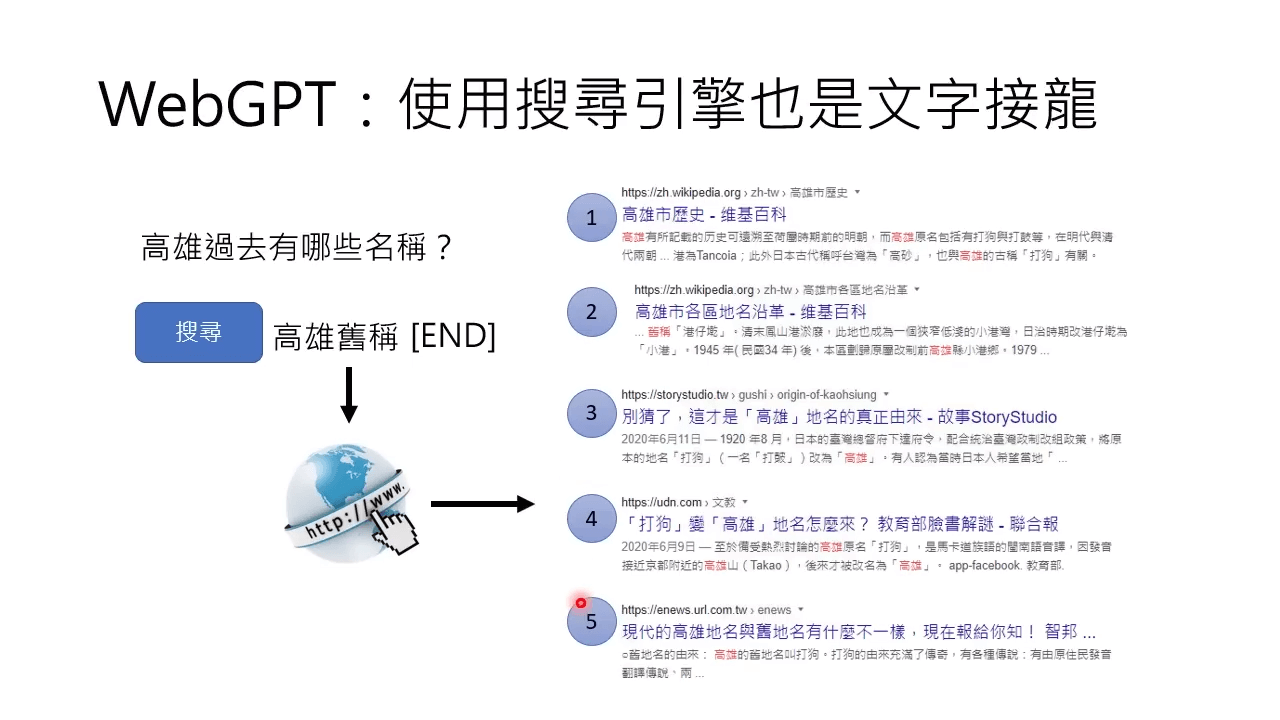
WebGPT 也在文字接龙。

自动爬取各大网站的信息。


搜索的策略也需要人类介入。
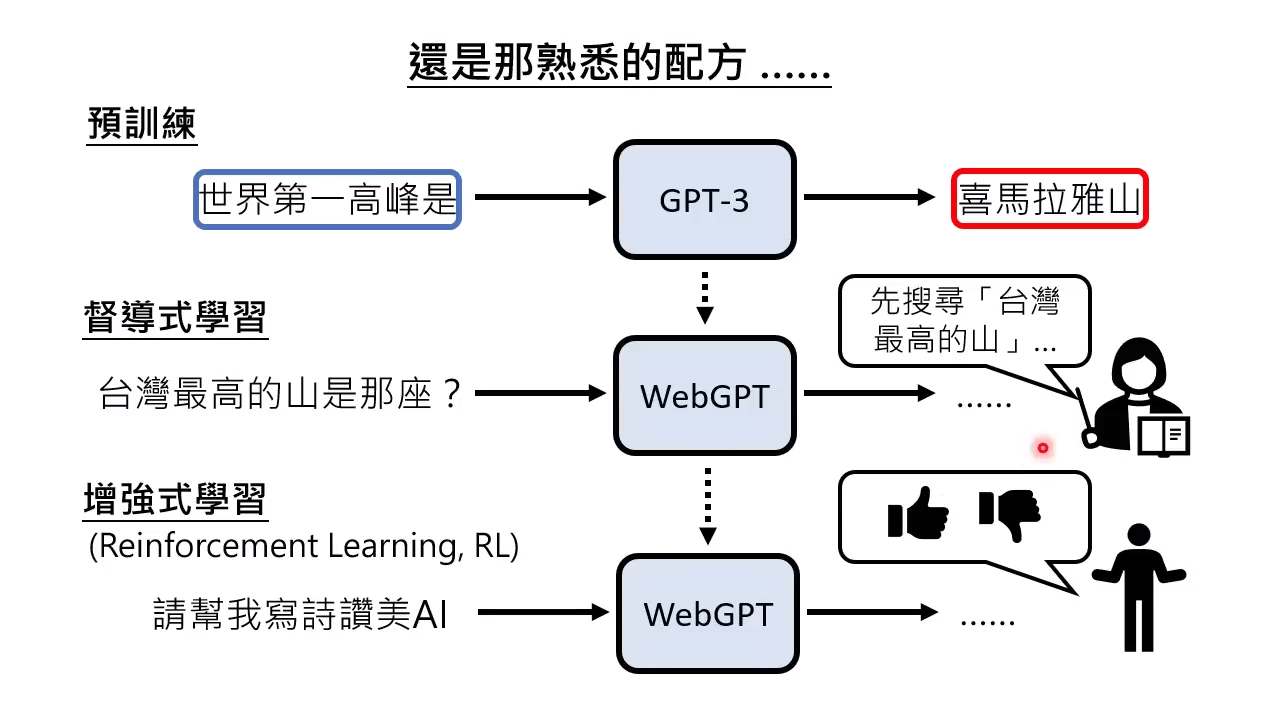
预训练-督导式学习-增强式学习

产生资料的方法:用另一个语言模型来产生
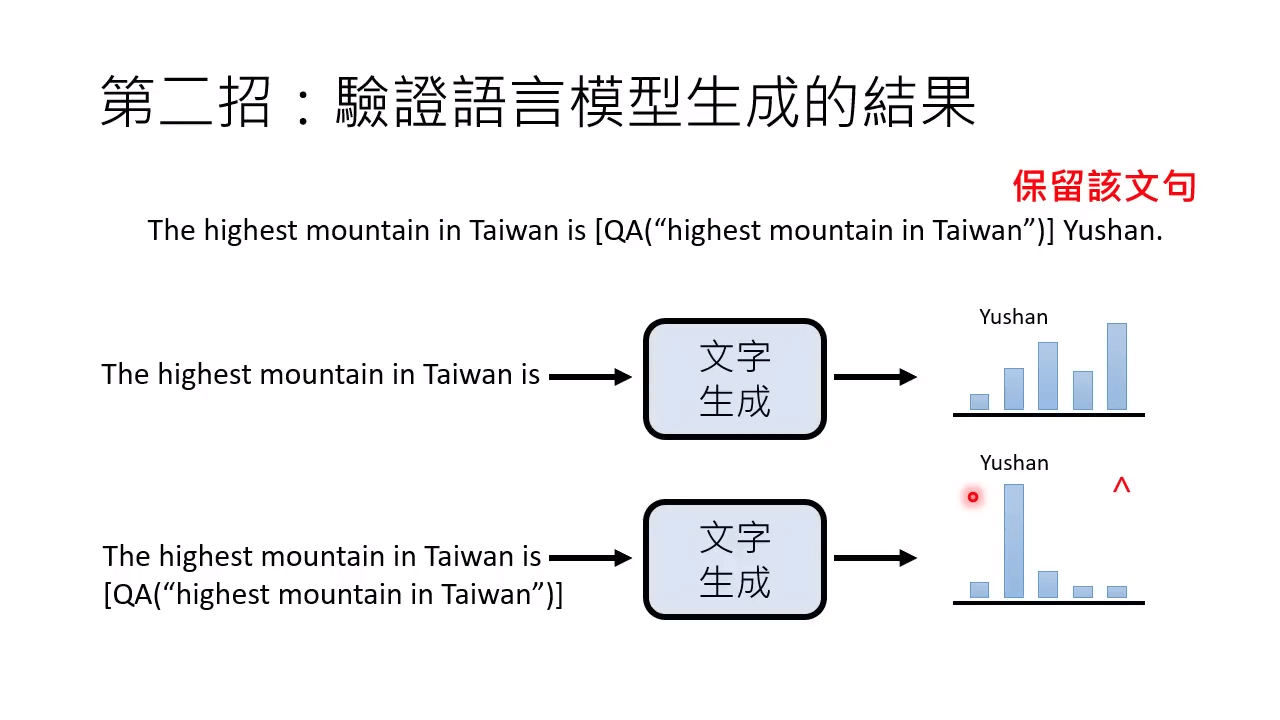
然后验证语言模型生成的结果是否有效。
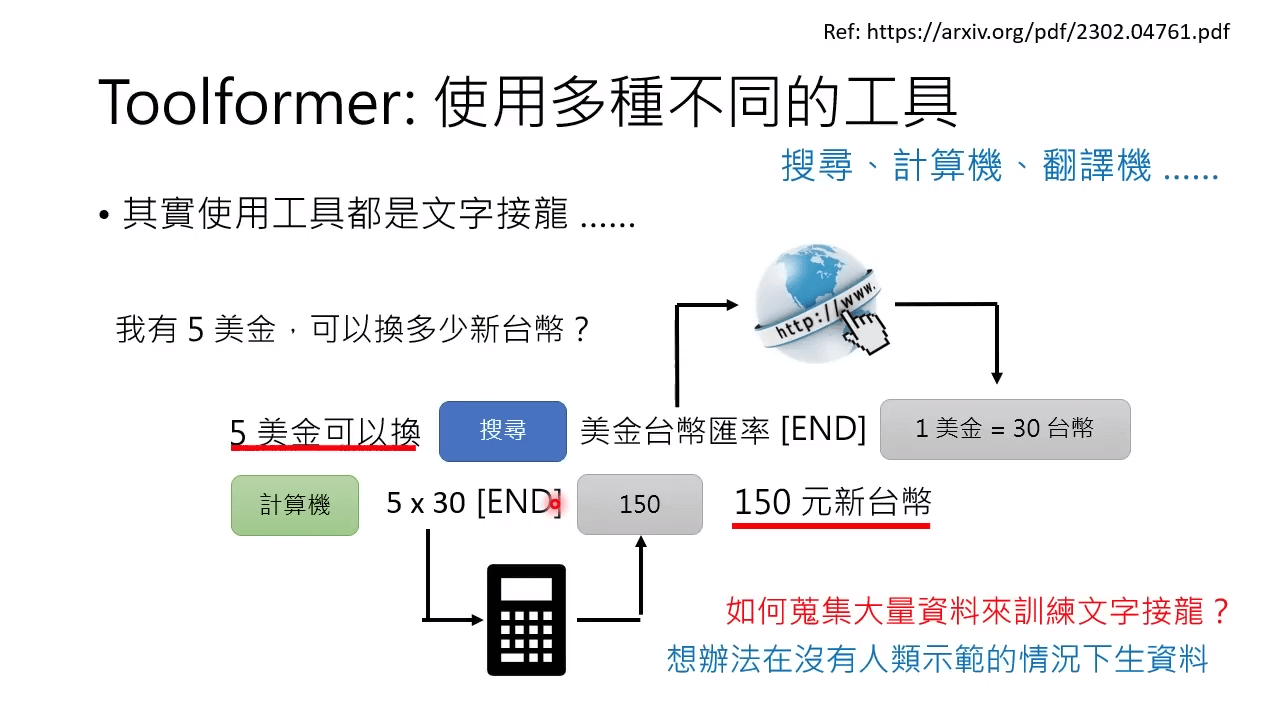
Toolformer 不仅可以使用网络搜索,还可以使用计算器、翻译器等:[2302.04761] Toolformer: Language Models Can Teach Themselves to Use Tools (arxiv.org)
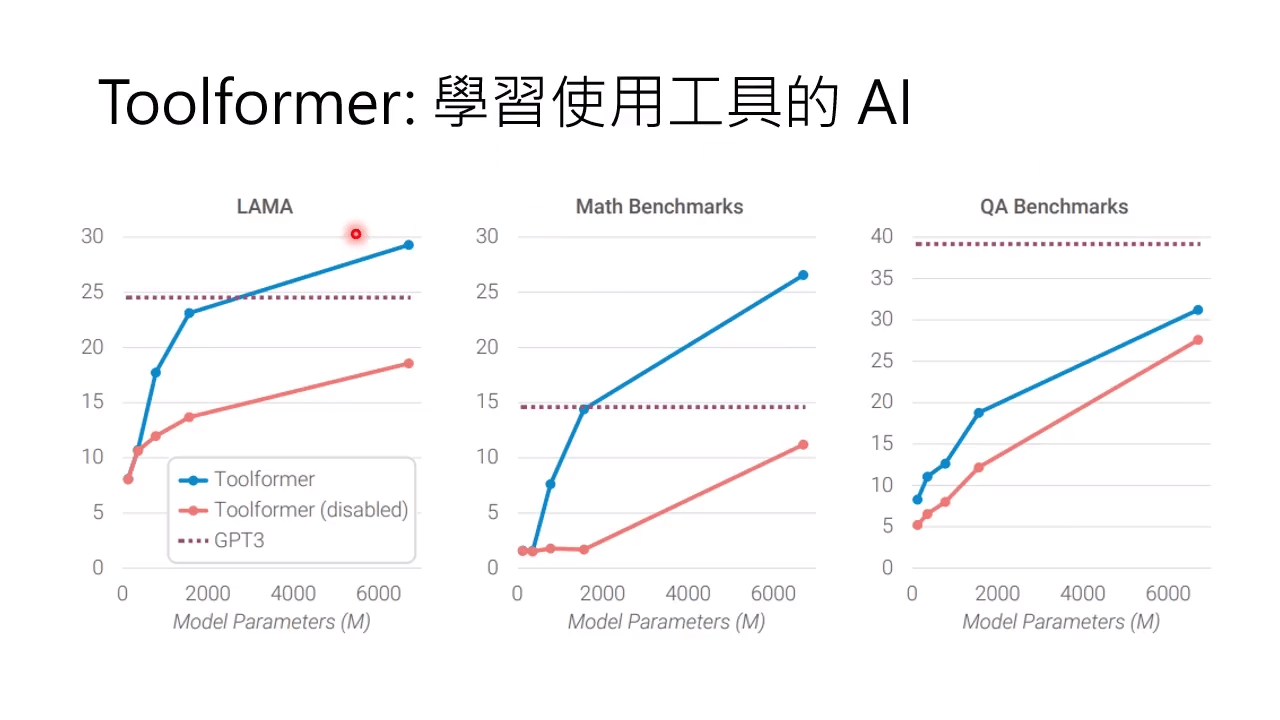
有些问题上比 GPT3 好使。