Preparation
【機器學習 2021】來自人類的惡意攻擊 -Adversarial Attack- -上- – 基本概念
Motivation

- 你训练了很多神经网络。
- 我们寻求在现实世界中部署神经网络。
- 网络对那些用来欺骗他们的输入是否稳健?
- 适用于垃圾邮件分类、恶意软件检测、网络入侵检测等。
比如垃圾邮件的发送者识图绕开 EMAIL FILTER 系统的检测发送垃圾邮件。
Example of Attack
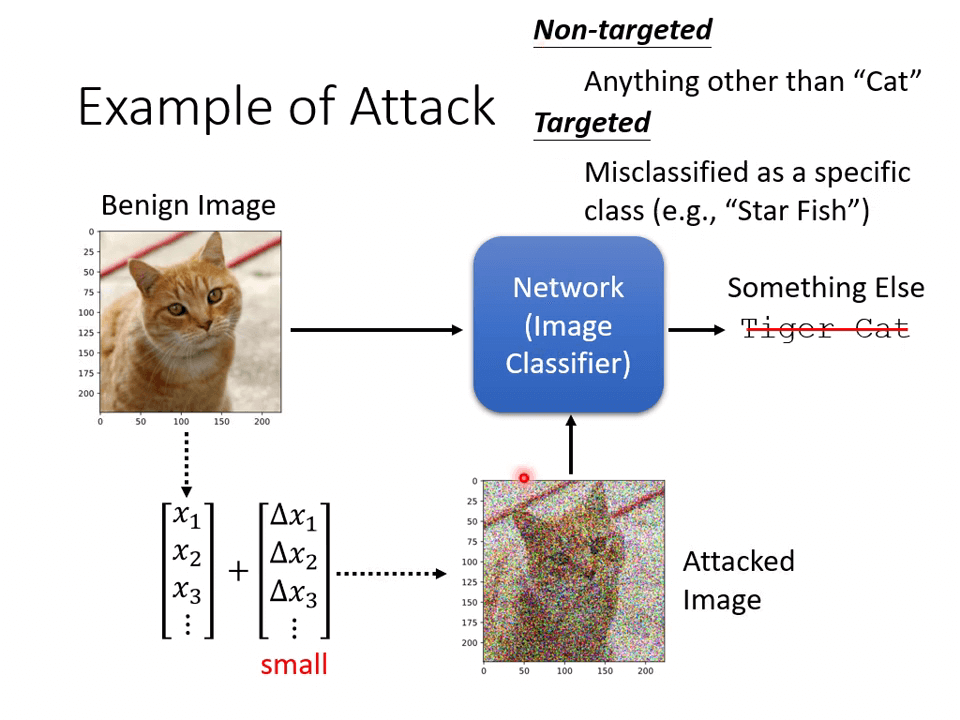
攻击在原始图像(Benign Image) 中添加一些微小的向量 ,得到 Attacked Image。
攻击分为两种:
- Non-targeted
- 让神经网络输出的不是”猫”
- Targeted
- 让神经网络输出某些特定的标签

通过加入一些微小的、特定的噪声,使得神经网络识别结果完全不合人类逻辑。

如果给图片随机添加噪声,并不会给神经网络造成太大的影响。
How to Attack
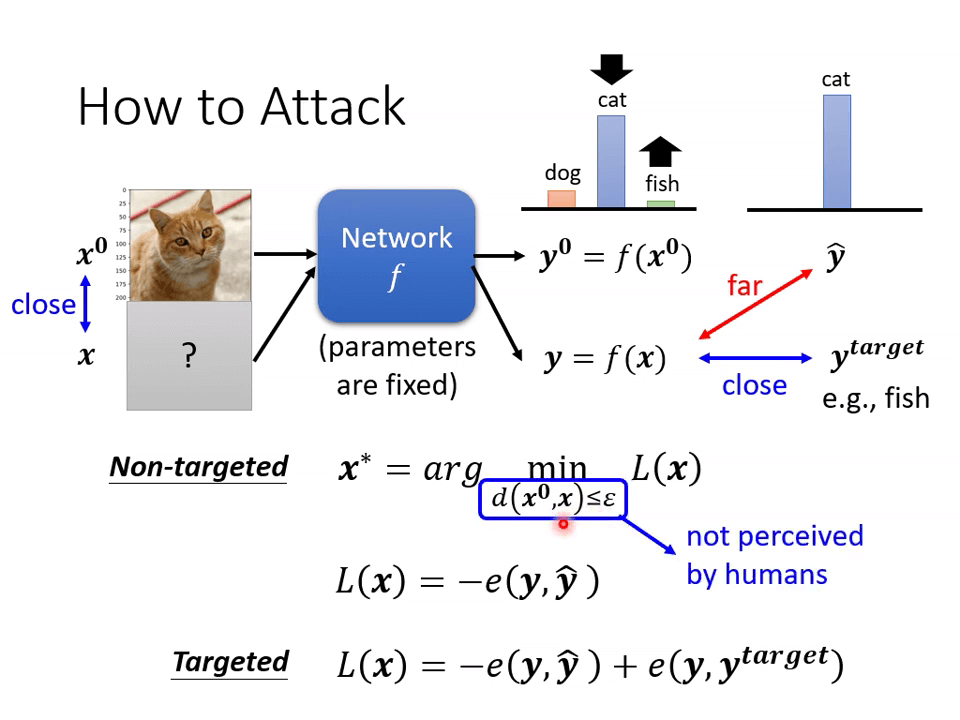
对于 Non-targeted 任务,要求受攻击神经网络的输出 与真实答案 尽可能远,因此攻击神经网络的目标为:
其中,损失函数
对于 Targeted 任务,不仅要使受攻击神经网络的输出 与真实答案 尽可能远,还要使受攻击网络得到错误的输出 。
所添加的信息 往往与原图 差距要足够小,使人难以辨别,因此有附加条件 , 是人为设定的阈值。
Non-perceivable
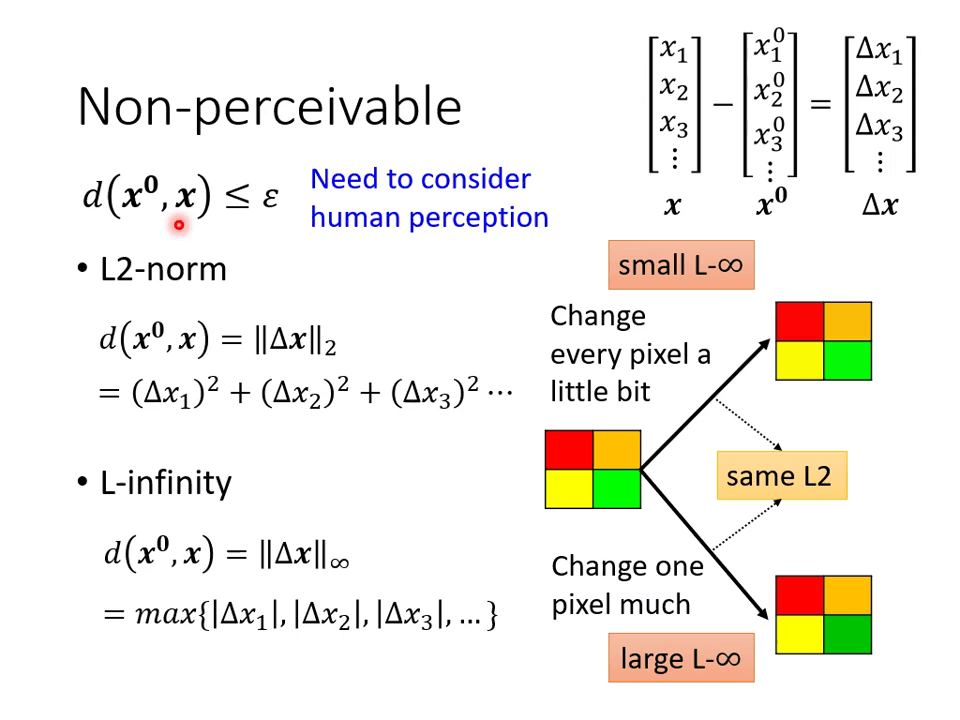
给图片添加的信息要是人难以感知(Non-perceivable)的,即 。
- 使用 L2-norm:
- 使用 L-infinity:
使用 L-infinty 更为合适:给每个像素一个很小的变化(人不易察觉)和对某些像素很大的变化(人容易察觉),其 L2-norm 可能相同,但 L- 不同。
Attack Approach
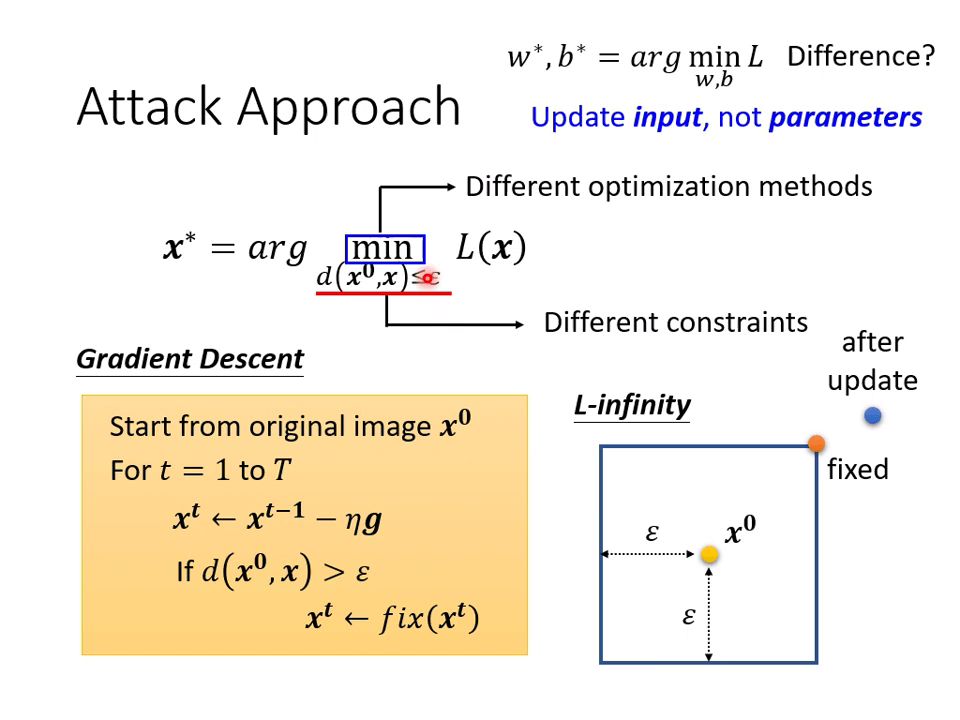
如何训练攻击神经网络?,使用梯度下降即可。对于 ,作一个阈值限制。
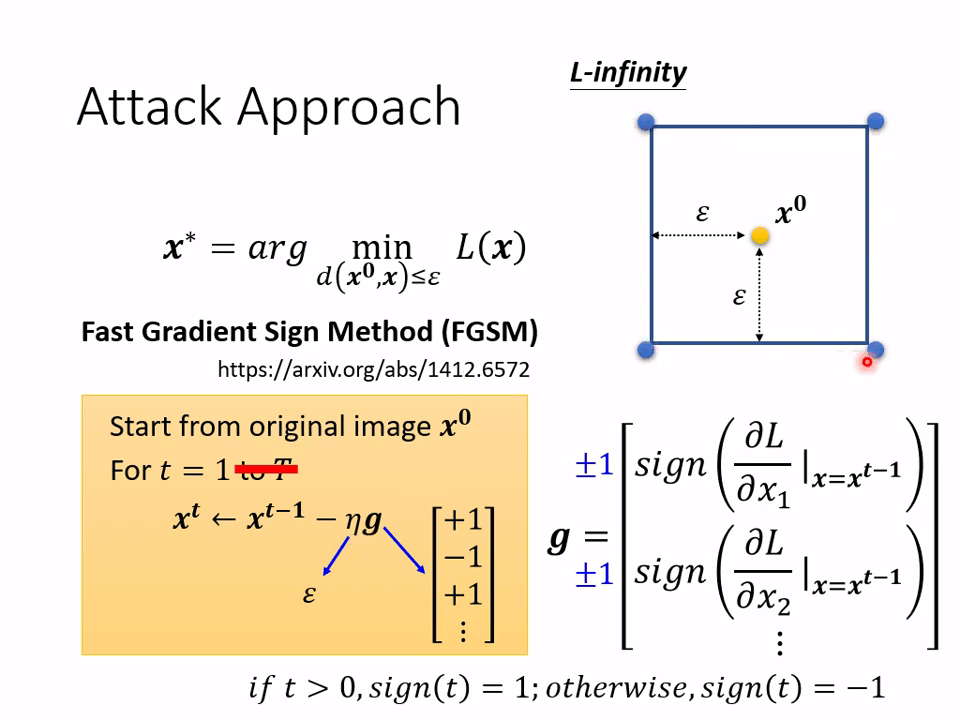
有一个应用上述思想的简单算法为 FGSM [1412.6572] Explaining and Harnessing Adversarial Examples (arxiv.org),其特点在于:
- 它只迭代一次
- 它的学习率设为我们限制的距离大小
- 它的梯度计算出来后会对每一个分量加上一个 sign 函数,使其成为正负 1

【機器學習 2021】來自人類的惡意攻擊 -Adversarial Attack- -下- – 類神經網路能否躲過人類深不見底的惡意?
White Box vs Black Box

- 在之前的攻击中,我们知道网络参数 。
- 这被称为白盒攻击。
- 但是多数情况你只能获得 online API 而不能获得模型参数。
- 如果我们不开源模型,是否安全?
- 否,黑盒攻击也是可能的。
Black Box Attack
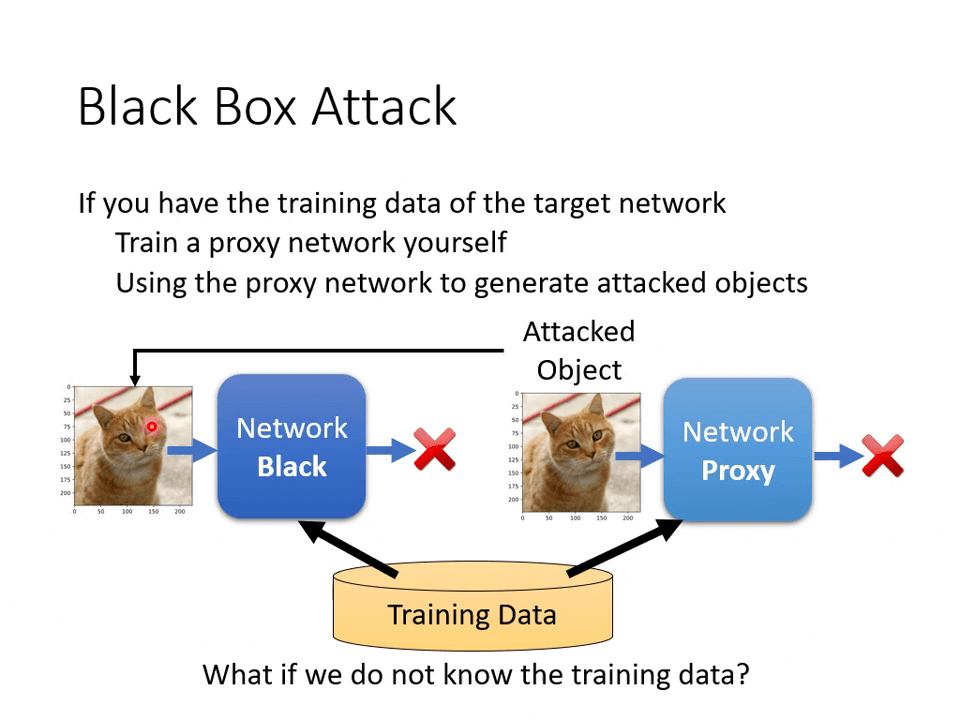
如果我们不知道受攻击网络,但是知道他们所用的训练集,我们可以根据训练集模仿一个受攻击网络(proxy network)。
但如果我们不知道训练集呢?
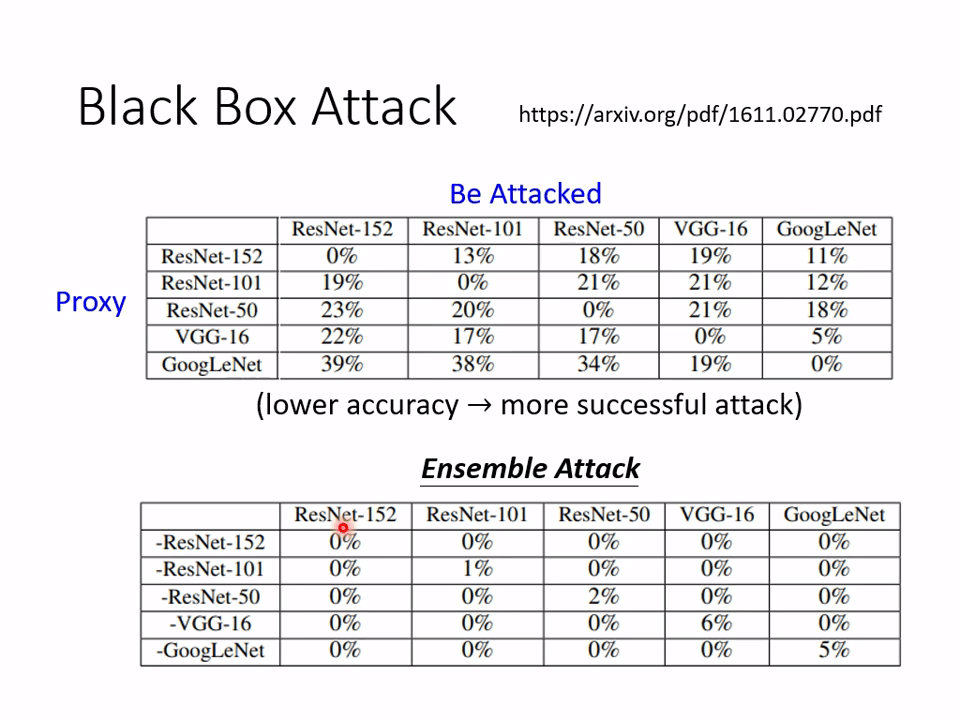
通过攻击相似网络得到的攻击神经网络,再攻击受攻击网络,也可以得到很好的攻击效果(受攻击)。
The attack is so easy!Why?

攻击似乎很容易?不同的网络面对同一个数据集似乎拟合出相似的分布。
被攻击不是神经网络的漏洞,是数据集的特性。
One pixel attack

只改变一个像素就能进行模型攻击也是可能的。
Universal Adversarial Attack

只用一张噪声图,就可以改变所有图片的识别结果。
Beyond Images

攻击在语音识别和 NLP 中的应用:
Attack in the Physical World

通过带上特制的眼镜,破坏人脸识别的结果。
- 攻击者需要找到超越单个图像的扰动。
- 扰动中相邻像素之间的极端差异不太可能被相机准确捕捉到。
- 希望制作主要由打印机可再现的颜色组成的扰动。

通过给路牌添加某些标记,改变自动驾驶识别车牌的结果。

给 35mph 车牌的 3 延长一点,识别器就会认为是限速 85mph。
Adversarial Reprogramming
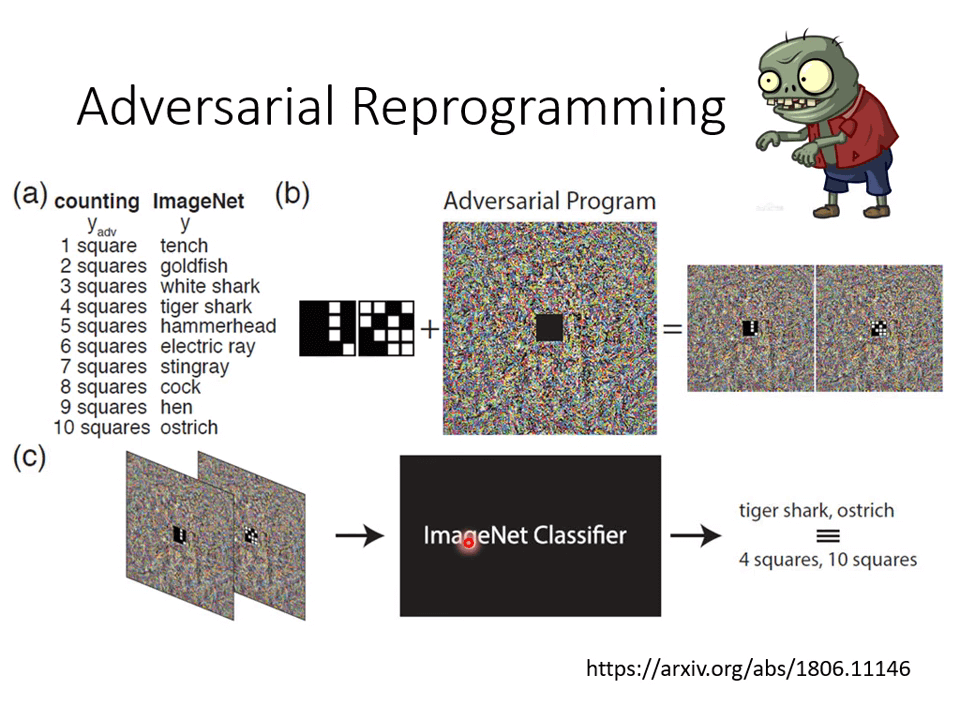
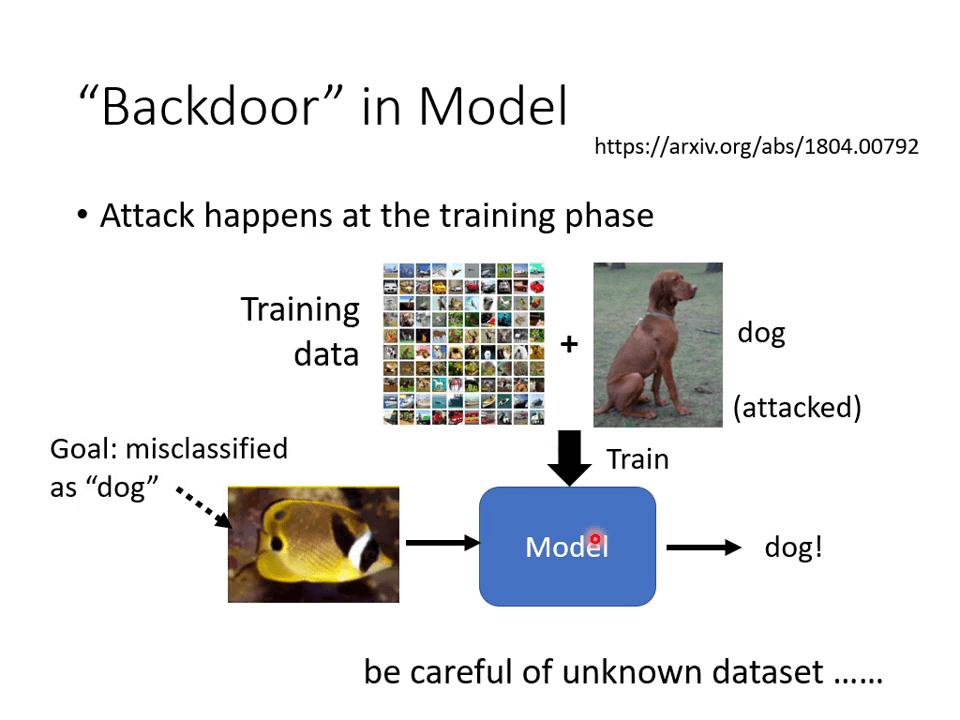
“Backdoor” in Model
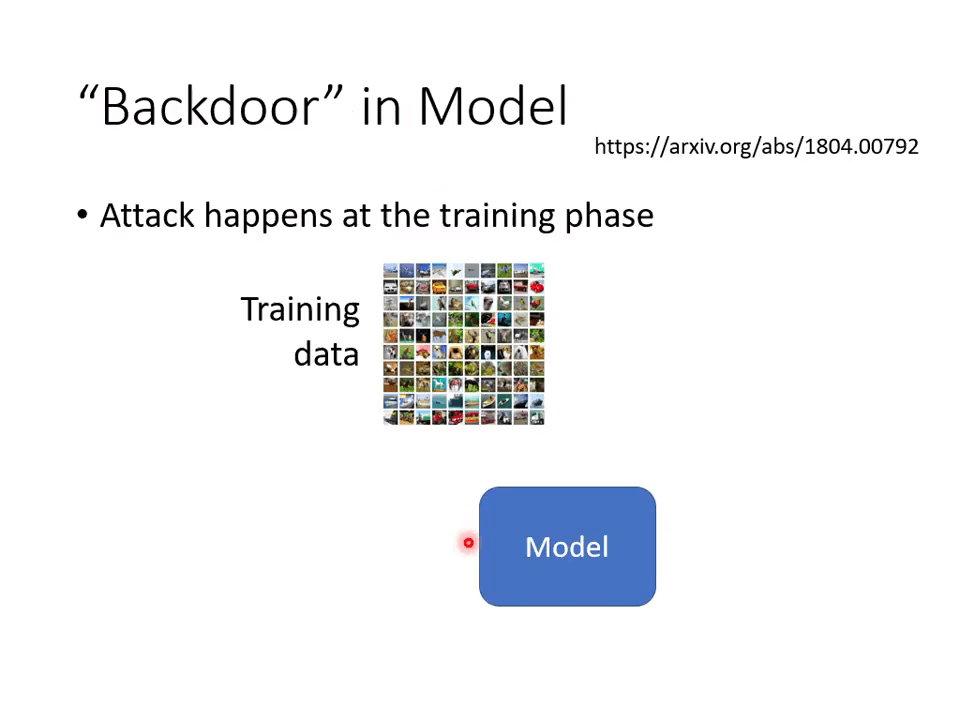
- [[1804.00792\] Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks (arxiv.org)](https://arxiv.org/abs/1804.00792)
在训练集上就可以做到模型攻击。
Passive Defense
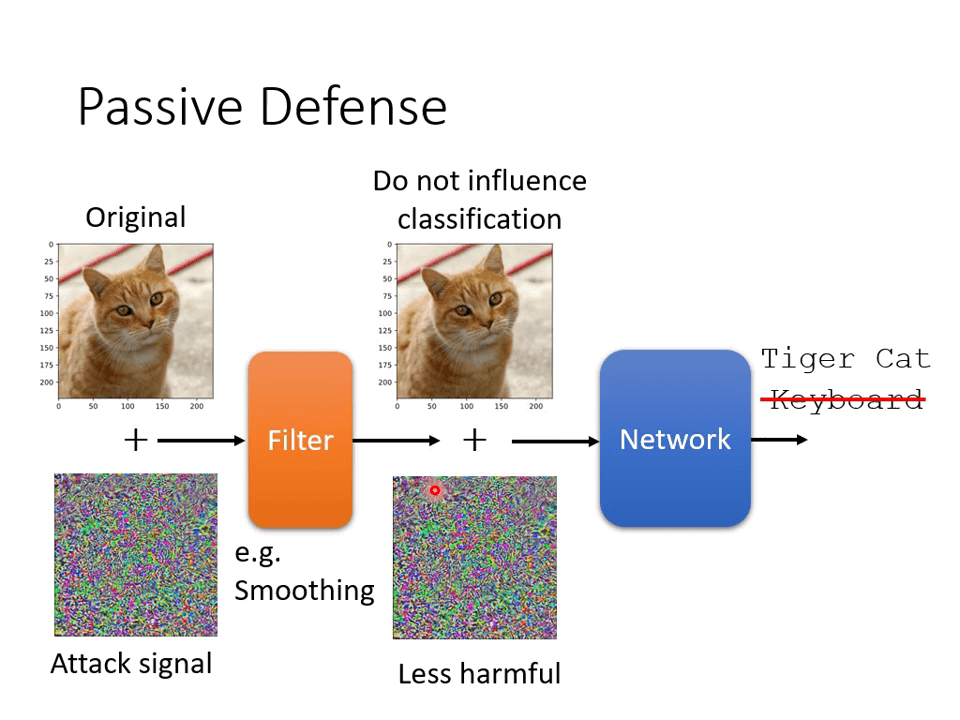
事先给输入的图片加一点模糊操作,使得攻击信号减弱。
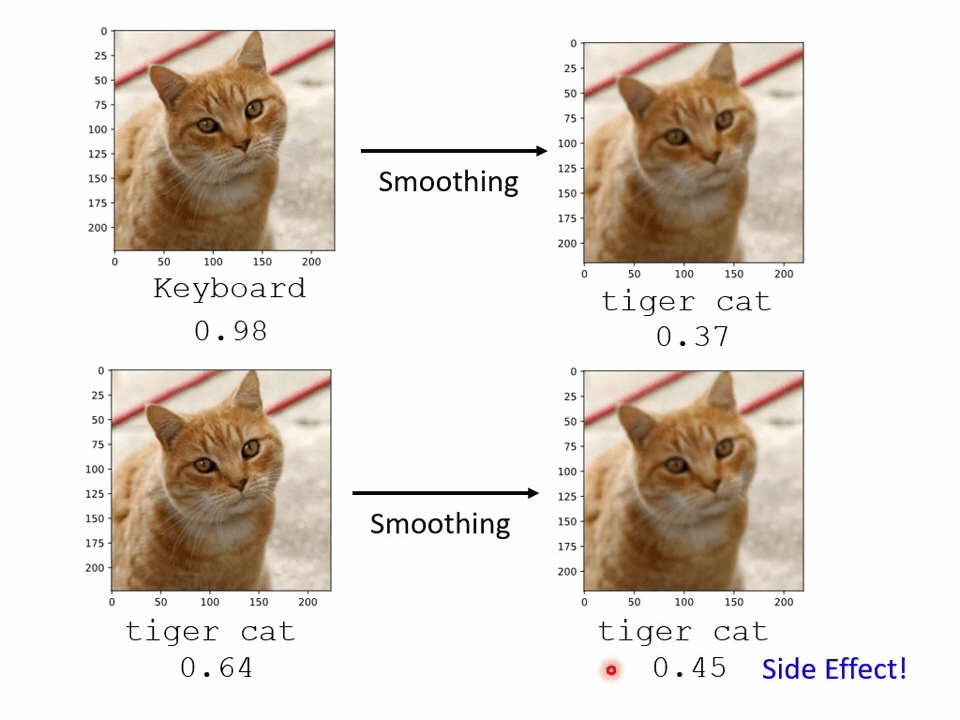
但这也有可能影响原先的识别性能。

使用图像压缩的方式/生成的方式减弱攻击信号。
- [1804.00792] Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks (arxiv.org)
- [1802.06816] Shield: Fast, Practical Defense and Vaccination for Deep Learning using JPEG Compression (arxiv.org)
- [1805.06605] Defense-GAN: Protecting Classifiers Against Adversarial Attacks Using Generative Models (arxiv.org)
Passive Defense - Randomization

如果攻击者知道模型会事先作模糊操作,可能还会改进攻击操作使攻击更有效。通过随机化的方式使网络难以受攻击。
Proactive Defense

Proactive Defense 主动防御
在训练的时候从攻击算法中修改数据进行训练。这也是数据增强的一种方式。但是对新的攻击算法不好使。
Concluding Remarks

- 攻击:给定网络参数,攻击非常容易
- 甚至黑匣子攻击也是可能的
- 防御:被动和主动
- 攻击/防御仍在发展