视频
课程
Python 学习中的两大法宝函数(当然也可以用在 PyTorch)
from torch.utils.data import Datasethelp(Dataset)Dataset??PyTorch 加载数据初认识
Pytorch 有两个类:
Dataset: 提供一种方式去获取数据及其标签- 如何获取每一个数据及其标签
- 告诉我们总共有多少数据
Dataloader: 为后面的网络提供不同的数据形式
Dataset 类代码实战
下载了数据包,是一个蚂蚁和蜜蜂的二分类问题。训练集根目录为 dataset/train,标签有 ants 和 bees。
设计一个类 MyData,负责读取数据集:
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
"""
初始化
:param root_dir: 根目录
:param label_dir: 标签目录
"""
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
"""
获取对象
:param idx: 索引
:return:
"""
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)
root_dir = "dataset/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)TensorBoard 的使用(一)
使用 pytorch 的 tensorboard 在网页端显示函数图像 :
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
for i in range(100):
writer.add_scalar("y=2x", 2 * i, i)
writer.close()在 shell 端口中 tensorboard --logdir=logs:(启动 tensorboard,logdir 目录为 logs)
PS D:\Study\1st-year-master\XiaoTuDui\Test> tensorboard --logdir=logs
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.9.1 at http://localhost:6006/ (Press CTRL+C to quit)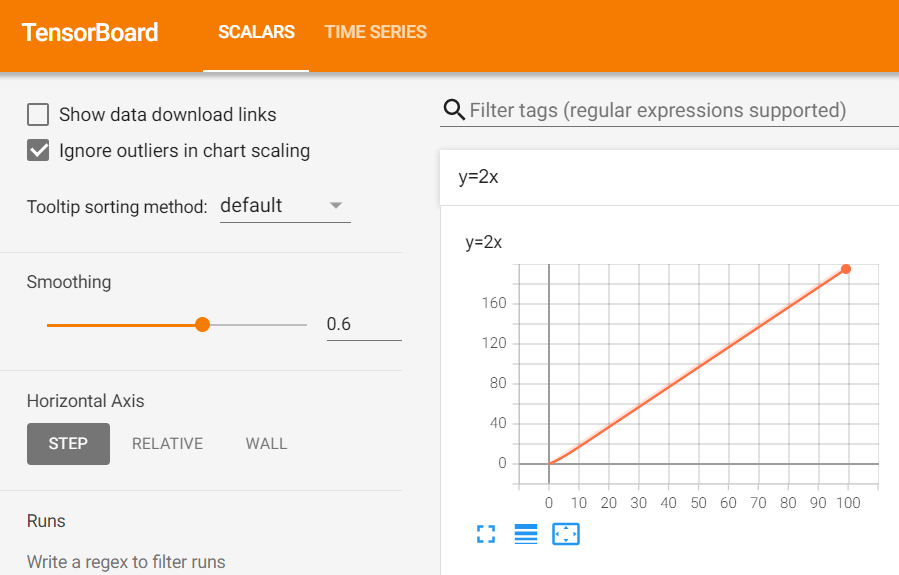
如果两段 writer.add_scalar 名称相同,可能会出现一张图像混合形成两张图像的情况,可以考虑清除项目中 logs/ 的缓存刷新。
TensorBoard 的使用(二)
主要讲了 writer.add_image 的用法。
def add_image( self, tag, img_tensor, global_step=None, walltime=None, dataformats="CHW" ): """Add image data to summary. Note that this requires the ``pillow`` package. Args: tag (str): Data identifier img_tensor (torch.Tensor, numpy.ndarray, or string/blobname): Image data global_step (int): Global step value to record walltime (float): Optional override default walltime (time.time()) seconds after epoch of event dataformats (str): Image data format specification of the form CHW, HWC, HW, WH, etc. Shape: img_tensor: Default is :math:`(3, H, W)`. You can use ``torchvision.utils.make_grid()`` to convert a batch of tensor into 3xHxW format or call ``add_images`` and let us do the job. Tensor with :math:`(1, H, W)`, :math:`(H, W)`, :math:`(H, W, 3)` is also suitable as long as corresponding ``dataformats`` argument is passed, e.g. ``CHW``, ``HWC``, ``HW``. Examples:: from torch.utils.tensorboard import SummaryWriter import numpy as np img = np.zeros((3, 100, 100)) img[0] = np.arange(0, 10000).reshape(100, 100) / 10000 img[1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000 img_HWC = np.zeros((100, 100, 3)) img_HWC[:, :, 0] = np.arange(0, 10000).reshape(100, 100) / 10000 img_HWC[:, :, 1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000 writer = SummaryWriter() writer.add_image('my_image', img, 0) # If you have non-default dimension setting, set the dataformats argument. writer.add_image('my_image_HWC', img_HWC, 0, dataformats='HWC') writer.close() Expected result: .. image:: _static/img/tensorboard/add_image.png :scale: 50% """
从 PIL 到 numpy,需要在 add_image() 中指定 shape 中每一个数字/维表示的含义。dataformats="HWC"(高、宽、通道数)
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs")
image_path = r"dataset\train\ants\0013035.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
print(type(img_array))
print(img_array.shape)
writer.add_image("test", img_array, 2, dataformats="HWC")
for i in range(100):
writer.add_scalar("y=2x", 2 * i, i)
writer.close()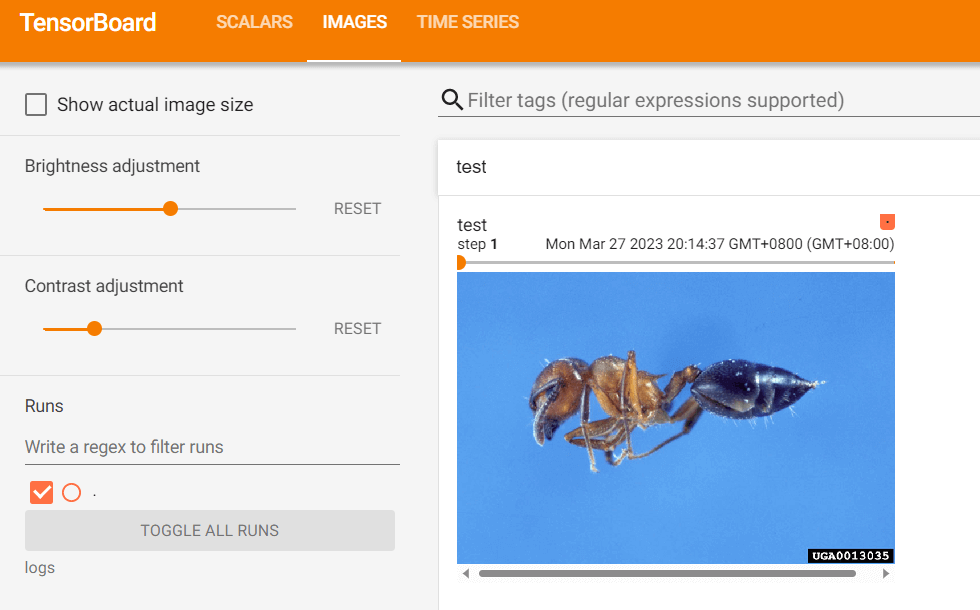
Transforms 的使用
transforms 是一个工具包,读入图片经过 transforms 后产生结果。
如 transforms.ToTensor() 将 Image 格式转换成 tensor 格式。
from torchvision import transforms
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
img_path = r"dataset/train/ants/0013035.jpg"
img = Image.open(img_path)
writer = SummaryWriter("logs")
# transforms 该如何被使用
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
print(tensor_img)
writer.add_image("Tensor_img", tensor_img)
writer.close()常见的 Transforms(一)
讲了 transforms.Normalize 的用法。
class Normalize(torch.nn.Module): """Normalize a tensor image with mean and standard deviation. 使用平均值和标准偏差归一化张量图像 This transform does not support PIL Image. Given mean: ``(mean[1],...,mean[n])`` and std: ``(std[1],..,std[n])`` for ``n`` channels, this transform will normalize each channel of the input ``torch.*Tensor`` i.e., ``output[channel] = (input[channel] - mean[channel]) / std[channel]`` .. note:: This transform acts out of place, i.e., it does not mutate the input tensor. Args: mean (sequence): Sequence of means for each channel. std (sequence): Sequence of standard deviations for each channel. inplace(bool,optional): Bool to make this operation in-place. """
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("images/pytorch.png")
print(img)
# ToTensor
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
# Normalize
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([6, 3, 2], [9, 3, 5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm, 1)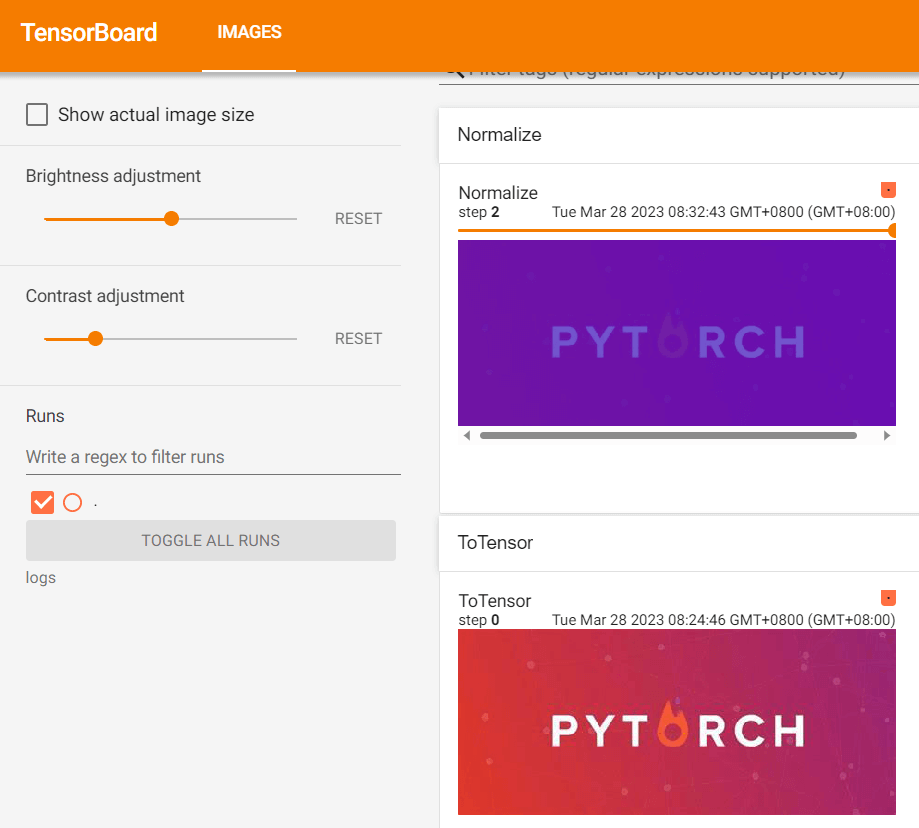
常见的 Transforms(二)
Resize 调整图像大小。
# Resize
print(img.size)
trans_resize = transforms.Resize((512, 512))
# img PIL -> resize -> img_resize PIL
img_resize = trans_resize(img)
# img_resize PIL -> totensor -> img_resize tensor
img_resize = trans_totensor(img_resize)
writer.add_image("Resize", img_resize, 0)
print(img_resize)
Compose: 将transforms列表里面的transform操作进行遍历。
class Compose: """Composes several transforms together. This transform does not support torchscript. Please, see the note below. Args: transforms (list of ``Transform`` objects): list of transforms to compose. Example: >>> transforms.Compose([ >>> transforms.CenterCrop(10), >>> transforms.PILToTensor(), >>> transforms.ConvertImageDtype(torch.float), >>> ]) .. note:: In order to script the transformations, please use ``torch.nn.Sequential`` as below. >>> transforms = torch.nn.Sequential( >>> transforms.CenterCrop(10), >>> transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)), >>> ) >>> scripted_transforms = torch.jit.script(transforms) Make sure to use only scriptable transformations, i.e. that work with ``torch.Tensor``, does not require `lambda` functions or ``PIL.Image``. """
# Compose - resize - 2
trans_resize_2 = transforms.Resize(512)
# PIL -> PIL -> tensor
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize", img_resize_2, 1)相当于先缩放 trans_resize_2,再转换成 tensor 类型 trans_totensor。
RandomCrop 随机裁剪
# RandomCrop
trans_random = transforms.RandomCrop([32, 64])
trans_compose_2 = transforms.Compose([trans_random, trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCropHW", img_crop, i)
torchvision 中的数据集使用
在官网上查看 torchvision.datasets 的用法
选用 CIFAR10 数据集,读入 train_set 和 test_set:
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)如果选择 download=True,会检查并验证 root 中是否存在数据集且是否完整,若没有,则会下载:
C:\Users\gzjzx\anaconda3\python.exe D:/Study/1st-year-master/XiaoTuDui/Test/P10_dataset_transform.py
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./dataset\cifar-10-python.tar.gz
1%| | 1114112/170498071 [00:40<48:11, 58582.60it/s]
可以将网址 https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz 复制到迅雷中由训练代下载,速度会快,将下载好的数据库拷贝回去。
Using downloaded and verified file: ./dataset\cifar-10-python.tar.gz
Extracting ./dataset\cifar-10-python.tar.gz to ./dataset
Files already downloaded and verified
根据官网 CIFAR-10 and CIFAR-100 datasets (toronto.edu) 对数据库的描述,查看数据信息:
print(test_set[0])
print(test_set.classes)
img, target = test_set[0]
print(img)
print(target)
print(test_set.classes[target])
# img.show()
print(test_set[0])
# 在 TensorBoard 中查看数据集中前 10 张图
writer = SummaryWriter("p10")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i)
writer.close()
DataLoader 的使用

Pytorch有两个类:Dataset: 提供一种方式去获取数据及其标签- 如何获取每一个数据及其标签
- 告诉我们总共有多少数据
DataLoader: 为后面的网络提供不同的数据形式
DataLoader 的使用:
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
# 测试数据集中第一张图片及 target
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
step = 0
for data in test_loader:
imgs, targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("test_data", imgs, step)
step += 1
writer.close()test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
dataset=test_data,读入test_data的数据集batch_size=4,每次读入 4 张图片shuffle=True,打乱图片顺序drop_last=False,数据集数量如果不能被 batch_size 整除,要丢弃最后一块吗?否
神经网络的基本骨架-nn.Module的使用
查看帮助文档:
对于神经网络的前向传播,input-forward-output, 自行设计一个神经网络的类,继承 nn.Moudle:初始化时,super(Model, self).__init__()
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))设计一个最简单的函数,让 output 为 input 的加 1:
import torch
from torch import nn
class MyClass(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input):
output = input + 1
return output
myClass = MyClass()
input = torch.tensor(1.0)
output = myClass(input)
print(output)tensor(2.)土堆说卷积操作(可选看)
大概讲了卷积操作 torch.nn.functional.conv2d,stride 和 padding 的含义。
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
print(input.shape)
print(kernel.shape)
output = F.conv2d(input, kernel, stride=1)
print(output)
output2 = F.conv2d(input, kernel, stride=2)
print(output2)
output3 = F.conv2d(input, kernel, stride=1, padding=1)
print(output3)torch.Size([1, 1, 5, 5])
torch.Size([1, 1, 3, 3])
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
tensor([[[[10, 12],
[13, 3]]]])
tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])
神经网络-卷积层
官方文档:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None):
- in_channels (int) – Number of channels in the input image 输入图像中的通道数
- out_channels (int) – Number of channels produced by the convolution 卷积产生的通道数
- kernel_size (int or tuple) – Size of the convolving kernel 卷积核的大小
- stride (int or tuple, optional) – Stride of the convolution. Default: 1
- padding (int, tuple or str, optional) – Padding added to all four sides of the input. Default: 0
较少用:
- padding_mode (str, optional) –
'zeros','reflect','replicate'or'circular'. Default:'zeros' - dilation (int or tuple, optional) – Spacing between kernel elements. Default: 1 内核元素之间的间距。默认值:1
- groups (int, optional) – Number of blocked connections from input channels to output channels. Default: 1 从输入通道到输出通道的阻塞连接数。默认值:1
- bias (bool, optional) – If
True, adds a learnable bias to the output. Default:True如果为“True”,则在输出中添加可学习的偏差。

输入/输出的大小计算公式,如果看论文时论文没有阐明,可以用这个公式推断出具体的参数。
导入相关库:
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = test_data = torchvision.datasets.CIFAR10("./dataset",
train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)设计卷积神经网络结构:
class MyClass(nn.Module):
def __init__(self):
super(MyClass, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
myClass = MyClass()
print(myClass)执行操作并输出到 Tensorboard 上:
writer = SummaryWriter("./logs")
step = 0
for data in dataloader:
imgs, targets = data
output = myClass(imgs)
print(imgs.shape)
print(output.shape)
# torch.Size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
# torch.Size([64, 6, 30, 30]) -> [xxx, 3, 30, 30]
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step += 1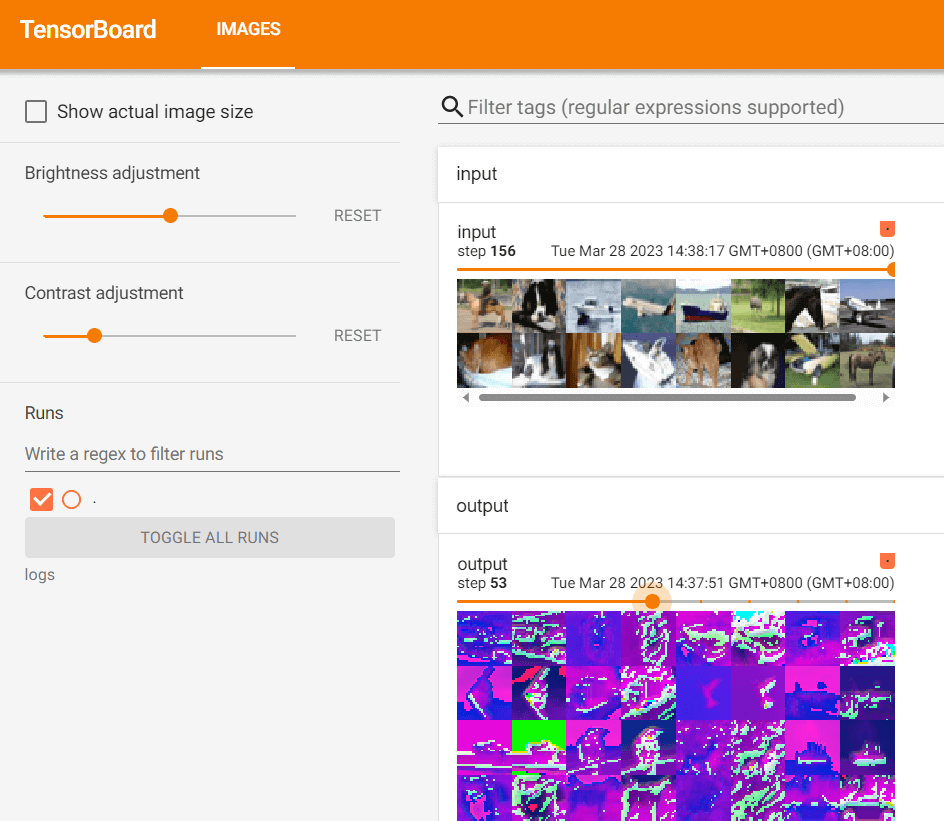
神经网络-最大池化的使用
Max-pooling 是 下采样的一种。
官方文档:
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False):
- kernel_size (Union[int, Tuple[int, int]**]) – the size of the window to take a max over 要放大的窗口的大小
- stride (Union[int, Tuple[int, int]**]) – the stride of the window. Default value is
kernel_size窗户的跨步 - padding (Union[int, Tuple[int, int]**]) – Implicit negative infinity padding to be added on both sides 要在两侧添加的隐式负无穷大填充
- dilation (Union[int, Tuple[int, int]**]) – a parameter that controls the stride of elements in the window 一个参数,用于控制窗口中元素的步幅
- return_indices (bool) – if
True, will return the max indices along with the outputs. Useful fortorch.nn.MaxUnpool2dlater 如果为“True”,则将返回最大索引以及输出 - ceil_mode (bool) – when True, will use ceil instead of floor to compute the output shap 当为True时,将使用ceil(向上取整)而不是floor(向下取整)来计算输出形状
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = test_data = torchvision.datasets.CIFAR10("./dataset",
train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32)
torch.reshape(input, (-1, 1, 5, 5))
print(input.shape)
class MyClass(nn.Module):
def __init__(self):
super(MyClass, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False)
def forward(self, input):
output = self.maxpool1(input)
return output
myClass = MyClass()
writer = SummaryWriter("./logs_maxpool")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
output = myClass(imgs)
writer.add_images("output", output, step)
step += 1
writer.close()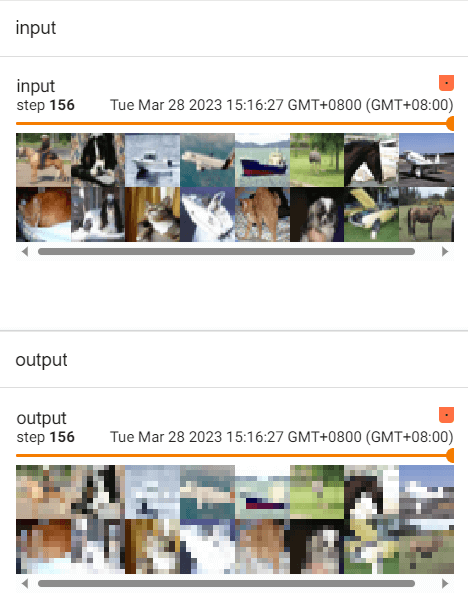
神经网络-非线性激活
官方文档:
import torch
import torchvision
from torch import nn
from torch.nn import ReLU
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2)) # 将其转换为 ReLU 能接受的形式
print(input.shape)
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class MyClass(nn.Module):
def __init__(self):
super(MyClass, self).__init__()
self.relu1 = ReLU()
def forward(self, input):
output = self.relu1(input)
return output
myclass = MyClass()
writer = SummaryWriter("./logs_relu")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("inputs", imgs, global_step=step)
output = myclass(imgs)
writer.add_images("output", output, step)
step += 1
writer.close()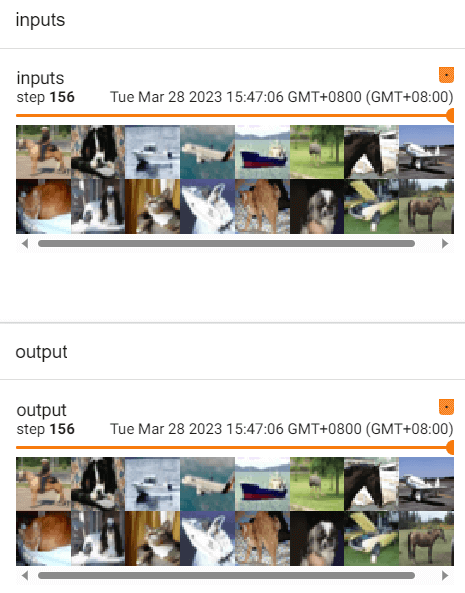
神经网络-线性层及其他层介绍
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class MyClass(nn.Module):
def __init__(self):
super(MyClass, self).__init__()
self.linear1 = Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
myclass = MyClass()
for data in dataloader:
imgs, targets = data
print(imgs.shape)
output = torch.flatten(imgs)
# output = torch.reshape(imgs, (1, 1, 1, -1))
print(output.shape)
output = myclass(output)
print(output.shape)从 torch.nn — PyTorch 2.0 documentation 获取更多神经网络架构。
也可从 Search — Torchvision 0.15 documentation (pytorch.org) 或 Models and pre-trained weights — Torchvision 0.15 documentation (pytorch.org) 获取经典神经网络模型。
神经网络-搭建小实战和 Sequential 的使用
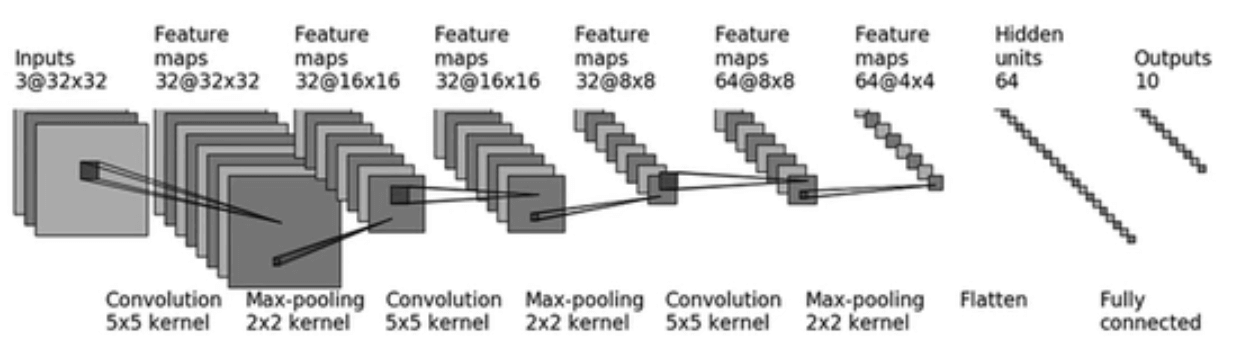
使用 Sequential() 将多个神经网络架构整合成一个。
整合如下神经网络:
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class MyClass(nn.Module):
def __init__(self):
super(MyClass, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
myClass = MyClass()
print(myClass)
input = torch.ones((64, 3, 32, 32))
output = myClass(input)
print(output.shape)
writer = SummaryWriter('../logs_seq')
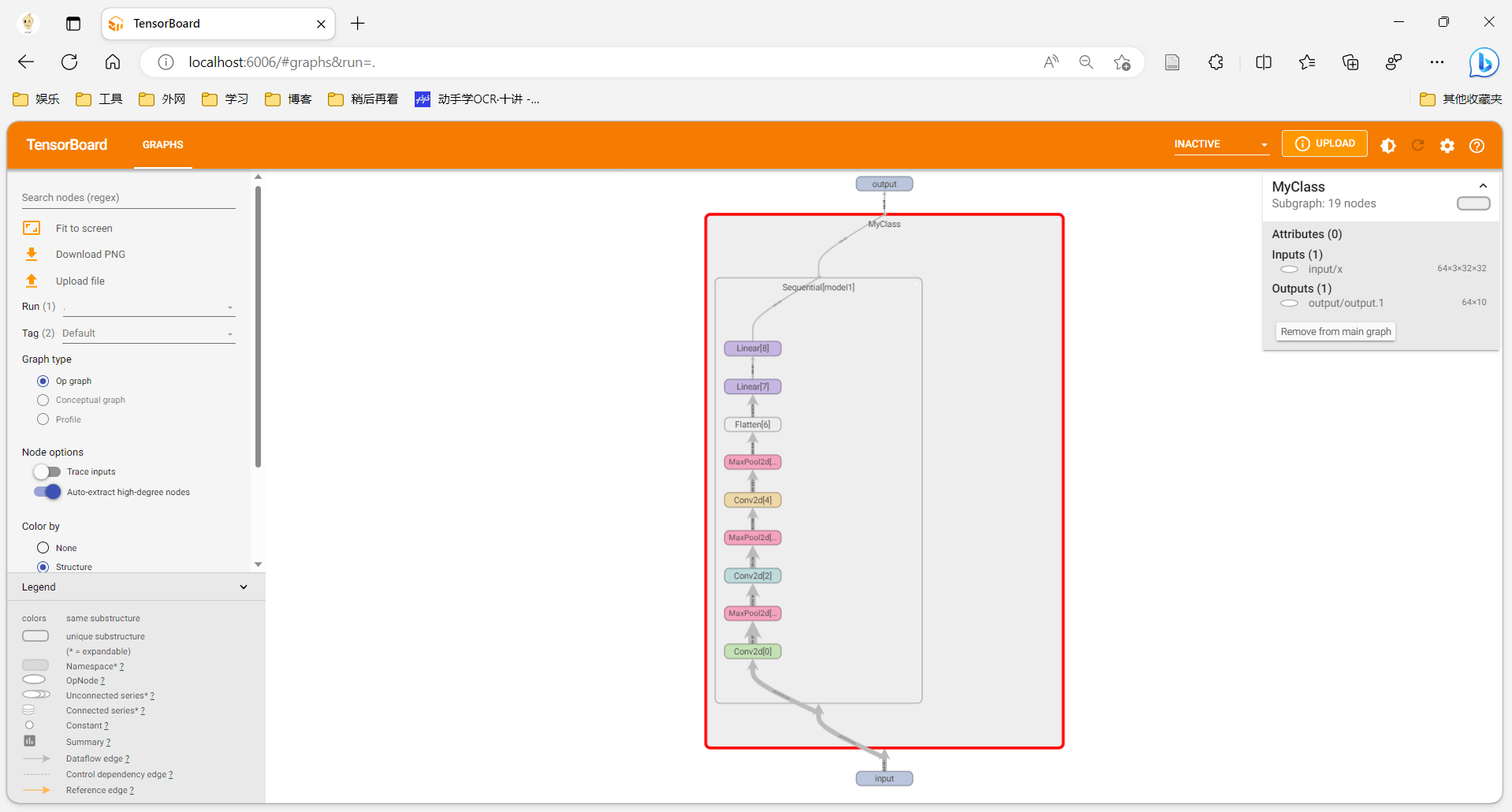
writer.add_graph(myClass, input)
writer.close()在 SummaryWriter() 中显示完整架构。
损失函数与反向传播
pytorch 中内置了很多损失函数。Search — PyTorch 2.0 documentation
L1Loss()、MSELoss()、CrossEntropyLoss()
import torch
from torch import nn
from torch.nn import L1Loss, MSELoss
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = L1Loss()
result = loss(inputs, targets)
loss_mse = MSELoss()
result_mse = loss_mse(inputs, targets)
print(result, result_mse)
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(result_cross)对损失函数进行反向传播可以得到模型中各个参数的梯度。result_loss.backward()。
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
class MyClass(nn.Module):
def __init__(self):
super(MyClass, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
myClass = MyClass()
for data in dataloader:
imgs, targets = data
outputs = myClass(imgs)
print(outputs)
print(targets)
result_loss = loss(outputs, targets)
print(result_loss)
result_loss.backward()优化器
官方文档:
loss = nn.CrossEntropyLoss()
myClass = MyClass()
optim = torch.optim.SGD(myClass.parameters(), lr=0.01)
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = myClass(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad()
result_loss.backward()
optim.step()
running_loss = running_loss + result_loss
print(running_loss)以最基本的随机梯度下降为例:optim = torch.optim.SGD(myClass.parameters(), lr=0.01)
,读入模型参数,然后读入学习率。
-
嵌套在
for epoch in range(20):进行多轮参数优化。 -
每次梯度下降都要清零梯度:
optim.zero_grad() -
计算出新的梯度:
result_loss.backward() -
更新模型参数:
optim.step()
一般而言,每轮迭代会让损失函数值变小。
现有网络模型的使用及修改
从官网 Models and pre-trained weights — Torchvision 0.15 documentation (pytorch.org) 中可以获得流行的模型以及 pretrain 后的模型。
-
初始化 vgg-16 模型,参数不变:
vgg16_false = torchvision.models.vgg16(pretrained=False) -
初始化 vgg-16 模型,并从官网上下载经过预训练后的参数:
vgg16_true = torchvision.models.vgg16(pretrained=True) -
在现有模型后追加层:
vgg16_true.add_module('add_linear', nn.Linear(1000, 10)) -
在现有模型后更改层:
vgg16_false.classifier[6] = nn.Linear(4096, 10)
完整的模型训练套路(一)
单独建一个 model.py 文件,用于定义模型:
# 搭建神经网络
import torch
from torch import nn
class MyClass(nn.Module):
def __init__(self):
super(MyClass, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
if __name__ == '__main__':
myClass = MyClass()
input = torch.ones((64, 3, 32, 32))
output = myClass(input)
print(output.shape)在 train.py 中,设置损失函数,优化器,训练轮次等训练神经网络:
from model import *
import torchvision
# 准备数据集
from torch import nn
from torch.utils.data import DataLoader
train_data = torchvision.datasets.CIFAR10(root='../dataset', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root='../dataset', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print('训练数据集的长度为:{}'.format(train_data_size))
print('测试数据集的长度为:{}'.format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
myClass = MyClass()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 定义优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(myClass.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数
epoch = 10 # 训练的轮数
# 训练
for i in range(epoch):
print('第 {} 轮训练开始'.format(i + 1))
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
outputs = myClass(imgs)
loss = loss_fn(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
print('训练次数: {}, Loss: {}'.format(total_train_step, loss.item()))完整的模型训练套路(二)(三)
from torch.utils.tensorboard import SummaryWriter
from model import *
import torchvision
# 准备数据集
from torch import nn
from torch.utils.data import DataLoader
train_data = torchvision.datasets.CIFAR10(root='../dataset', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root='../dataset', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print('训练数据集的长度为:{}'.format(train_data_size))
print('测试数据集的长度为:{}'.format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
myClass = MyClass()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 定义优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(myClass.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数
epoch = 10 # 训练的轮数
# 添加 tensorboard
writer = SummaryWriter('../logs_train')
# 训练
for i in range(epoch):
print('第 {} 轮训练开始'.format(i + 1))
# 训练步骤开始
myClass.train()
for data in train_dataloader:
imgs, targets = data
outputs = myClass(imgs)
loss = loss_fn(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
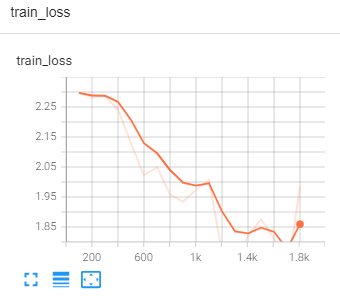
if total_train_step % 100 == 0:
print('训练次数: {}, Loss: {}'.format(total_train_step, loss.item()))
writer.add_scalar('train_loss', loss.item(), total_train_step)
# 测试步骤开始
myClass.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = myClass(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
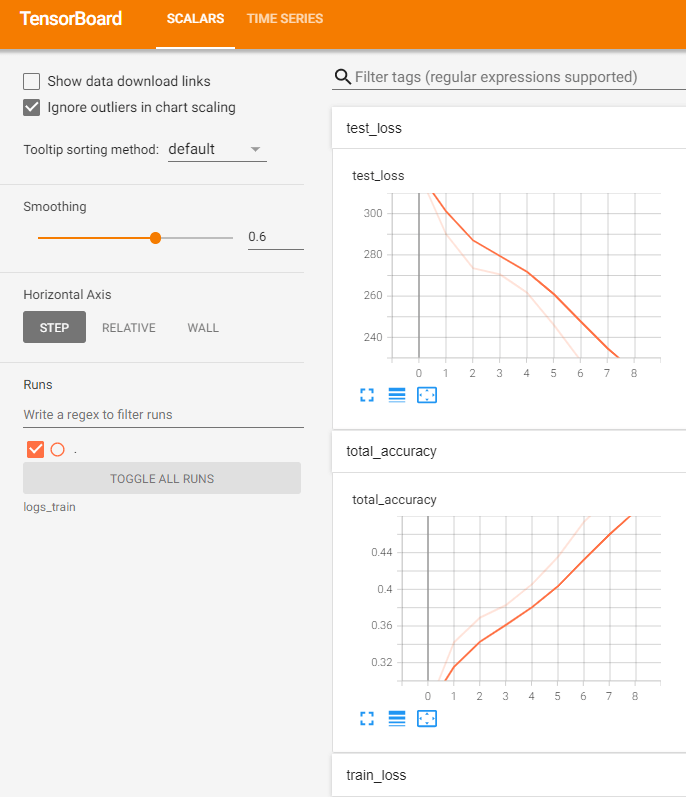
print('整体测试集上的 Loss: {}'.format(total_test_loss))
print('整体测试集上的正确率: {}'.format(total_accuracy / test_data_size))
writer.add_scalar('test_loss', total_test_loss, total_test_step)
writer.add_scalar('total_accuracy', total_accuracy / test_data_size, total_test_step)
total_test_step += 1
torch.save(myClass, "myClass_{}.pth".format(i))
# torch.save(myClass.state_dict(), "myClass_{}.pth".format(i))
print("模型已保存")
writer.close()将模型调整为 train / eval 模式:myClass.train()、myClass.eval(),该调整对 Dropout 和 BatchNorm 等架构有效。
测试步骤(不更新参数,不计算梯度,可以节约内存): with torch.no_grad():
输出每轮次的损失函数的值:
if total_train_step % 100 == 0:
print('训练次数: {}, Loss: {}'.format(total_train_step, loss.item()))计算正确率:
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy使用 SummaryWriter 可视化训练过程:
writer.add_scalar('train_loss', loss.item(), total_train_step)writer.add_scalar('test_loss', total_test_loss, total_test_step)writer.add_scalar('total_accuracy', total_accuracy / test_data_size, total_test_step)
保存每轮次训练出的模型:
torch.save(myClass, "myClass_{}.pth".format(i))
# torch.save(myClass.state_dict(), "myClass_{}.pth".format(i))
print("模型已保存")利用 GPU 训练(一)
网络模型可以使用 cuda:
if torch.cuda.is_available():
myClass = MyClass()
myClass = myClass.cuda() # 将网络模型转到 cuda 上损失函数可以使用 cuda:
# 损失函数
if torch.cuda.is_available():
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.cuda()优化器不可以。
测试集、数据集数据可以使用 cuda:
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
利用 GPU 训练(二)
使用 torch.device() 设置训练用的设备:device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
如果有多个 gpu,可以用cuda:0 指定 0 号 gpu 等。
将模型放到相应设备上训练:
-
myClass = myClass.to(device)模型 -
loss_fn = loss_fn.to(device)损失函数 -
python for data in train_dataloader: imgs, targets = data imgs = imgs.to(device) targets = targets.to(device)
完整的模型验证套路
利用已经训练好的模型,然后给它提供输入,得到期望的输出。
import torch
import torchvision
from PIL import Image
from torch import nn
image_path = '../imgs/dog.png'
image = Image.open(image_path)
image = image.convert('RGB')
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
class MyClass(nn.Module):
def __init__(self):
super(MyClass, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
model = torch.load("myClass_0.pth", map_location=torch.device('cpu'))
print(model)
image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))读入测试图片:
image_path = '../imgs/dog.png'
image = Image.open(image_path)
image = image.convert('RGB')
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)读入已经训练好的模型,map_location=torch.device('cpu')让在 cuda 上训练的模型也可以在 cpu 中测试,否则会报错:
model = torch.load("myClass_0.pth", map_location=torch.device('cpu'))
print(model)输出预期结果:
image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))tensor([[-2.7974, -0.1087, 0.5627, 1.2185, 1.4736, 1.4348, 2.3175, 1.3776,
-3.5540, -0.6126]])
tensor([6])
看看开源项目
看说明文档 README.md,一般 train.py 可以用来训练: